Setup
The LLMs are served using a vLLM Open AI server, so they come with an Open AI compatible API. An example is shown below. After launching a model you may have to wait up to 30 minutes for the API to become live! To call the model from python you will need:- Your CUDO_TOKEN
- The Model ID
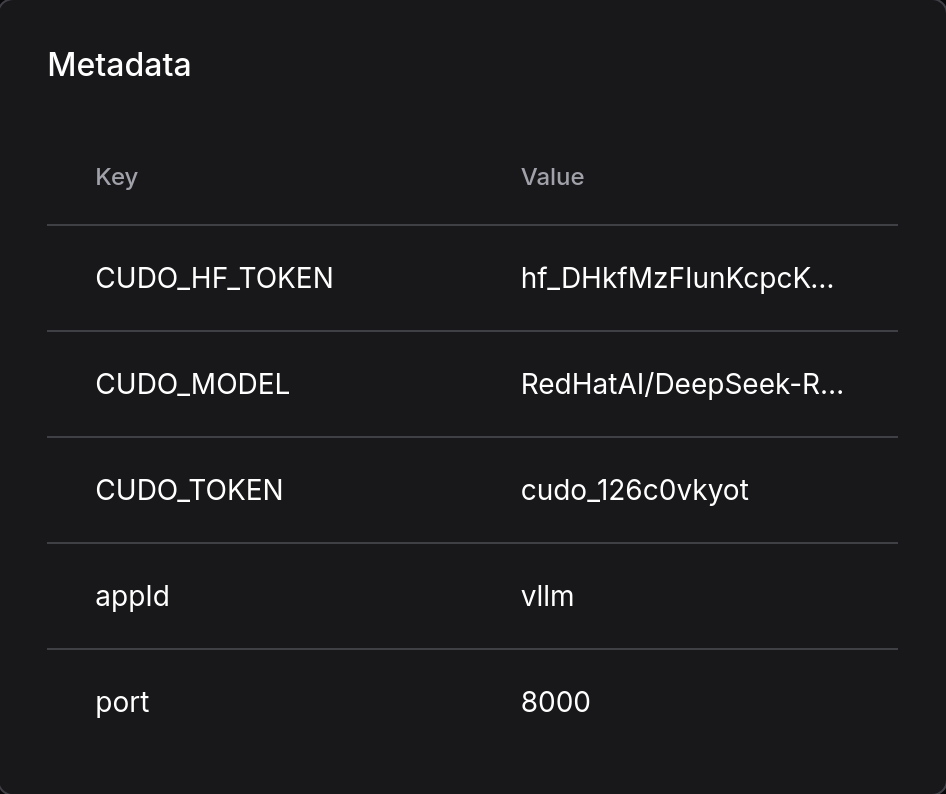
Quick Reference
| Model | App Option | Model ID |
|---|---|---|
| DeepSeek-R1 | 14b/24GB GPU | RedHatAI/DeepSeek-R1-Distill-Qwen-14B-quantized.w4a16 |
| DeepSeek-R1 | 32b/48GB GPU | RedHatAI/DeepSeek-R1-Distill-Qwen-32B-quantized.w4a16 |
| DeepSeek-R1 | 70b/80GB GPU | RedHatAI/DeepSeek-R1-Distill-Llama-70B-quantized.w4a16 |
| Llama 3.3 70b | w4a16/48GB GPU | RedHatAI/Llama-3.3-70B-Instruct-quantized.w4a16 |
| Llama 3.3 70b | w4a16/80GB GPU | RedHatAI/Llama-3.3-70B-Instruct-quantized.w4a16 |
| Llama 3.3 70b | FP8/94GB GPU | RedHatAI/Llama-3.3-70B-Instruct-FP8-dynamic |
| Llama 3.1 405b | 3xA100 80GB | RedHatAI/Meta-Llama-3.1-405B-Instruct-quantized.w4a16 |
| Llama 3.1 405b | 4xH100 NVL 94GB | RedHatAI/Meta-Llama-3.1-405B-Instruct-quantized.w4a16 |
| Llama 3.1 405b | 4xH100 SXM 80GB | RedHatAI/Meta-Llama-3.1-405B-Instruct-quantized.w4a16 |