 Resources
Resources 
Enterprise AI budgets are no longer inching upward—they’re compounding at venture-style speed. IDC now pegs global spend on AI-centric servers and storage at a 42% five-year CAGR, projecting well over $200 billion by 2028 as accelerated hardware becomes the default in production clusters.
Yet money alone can’t conjure silicon. Even with Nvidia shipping H100s at a record pace, typical delivery windows have only just eased from nearly a year to 8-12 weeks, keeping many projects in holding patterns while queue-hopping cloud platforms charge premium rates for priority access.
At the same time, the urgency to deploy generative AI capabilities has spiked to near unanimity: 90% of executives now list data and AI investment as a top strategic priority for 2025, up from 88% last year. This convergence—run-away capital allocation, lingering GPU scarcity, and a C-suite mandate for rapid results—turns the classic build-versus-buy debate into a time-sensitive risk calculation.
Choosing an approach that aligns with both your talent bench and your GPU access window can make the difference between shipping a flagship model this fiscal year and watching competitors sprint ahead.
In this article, we’ll examine the trade-offs through a skills-gap lens, quantify the true total cost of ownership (TCO), and provide a decision framework supported by fresh market data and engineering benchmarks.
What makes up a modern AI infrastructure?
A production-grade AI stack today resembles a three-layer pyramid—compute, data & MLOps, and people, all of which must scale in lock-step.
1. Compute tier
Training clusters still consume the lion’s share of up-front capital expenditure (capex), but once a model is in production, the run-rate cost of serving billions of tokens climbs even faster. Barclays analysts, for example, predict that global inference-hardware spend will jump from roughly $12 billion in 2025 to $21 billion in 2026, overtaking training expenditures within the next 12–18 months.
NVIDIA’s Blackwell-class accelerators—B100 and B200—and the rack-scale GB200 NVL72 pod are built for that reality. Compared with Hopper, they deliver up to 25 × lower energy per token and introduce hardware-level confidential computing over NVLink for secure multi-tenant clusters.
Original equipment manufacturers (OEMs) are already shipping validated HGX systems with eight B100 GPUs per node, and industry forecasts indicate high-volume GB200 shipments will begin in mid-2025 as hyperscalers secure capacity.
For latency-critical inference, organizations increasingly embed lighter GPUs or specialized ASICs into edge gateways, all orchestrated from the same central control plane, balancing response-time SLAs with cluster-wide efficiency.
2. Data and MLOps layer
Even the most advanced GPU idles if your data pipeline is slow or clunky. Best practices typically combine three elements:
- High-throughput object storage: NVMe-backed, S3-compatible pools feed multi-terabyte training jobs at line rate. Object storage service supplies this layer out of the box, eliminating the time and capital expenditure of setting up separate storage clusters.
- Sub-millisecond feature serving: Streaming feature stores (e.g., Feast, Hopsworks) sit in front of the object store, pushing fresh embeddings to models in ≤ 300 ms thanks to modern streaming engines that now deliver p99 latencies under that threshold.
- Declarative pipelines: Teams orchestrate ETL, training, and evaluation with open-source frameworks such as Kubeflow, Dagster, and self-hosted MLflow Tracking—all containerized and deployable in minutes. MLflow’s OSS server lets you version every run and artefact without handing metadata to a third-party cloud.
Under the hood, NVMe fabrics and RDMA networking (mirroring NVIDIA’s DGX SuperPOD reference design) maintain high data ingest bandwidth to saturate B100 clusters during peak epochs.
If any step in that pipeline is slow (due to network bottlenecks, manual data preparation, or missing lineage tracking), the GPUs spend much of their time waiting rather than crunching tensors. The key point is that investing in storage, streaming, and MLOps automation—or even top-tier hardware — won’t deliver ROI.
3. People layer
Hardware and software only create value when a cross-functional team turns them into shipped models—and that’s where most organizations now hit a wall. A 2025 study found that 44% of executives cite a lack of in-house AI expertise as the single biggest barrier to generative-AI deployment.
Separate research tracking 40 growth-stage and enterprise data teams shows that machine-learning roles still account for barely a quarter of headcount, with data-platform and analytics engineers filling the rest—evidence that specialized ML talent remains scarce.
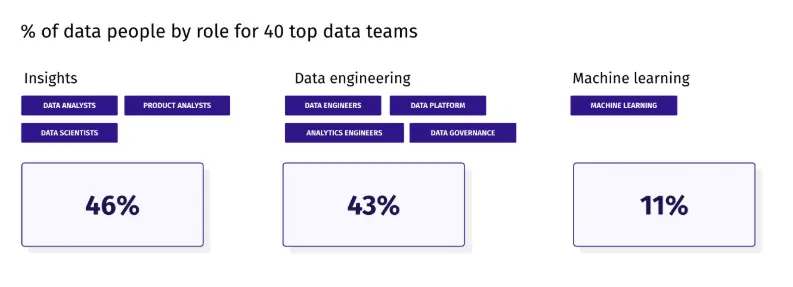 Source: Benchmark
Source: Benchmark
A pragmatic staffing pattern looks like this:
| Role | Focus | Typical ratio |
|---|---|---|
| Platform Engineers | GPU cluster ops, Kubernetes, infra-as-code | 1 per 200 GPUs |
| ML Engineers | Model training, hyper-tuning, evaluation | 3–4 per project |
| Data Engineers | Pipelines, feature store, quality checks | 1 per 2 ML engineers |
| MLOps/SRE | CI/CD, observability, rollback playbooks | 1 per 10 prod models |
*Median ranges derived from DataBenchmarks 2024–25 team-composition survey.
When any of these seats remain vacant—be it platform, data, or MLOps—projects stall and budgets bleed. That dynamic is why many firms co-create with external experts: partners arrive with an already established talent bench, allowing internal hires to ramp up gradually instead of blocking the launch calendar.
In-house build: Advantages & hidden costs
Setting up your own AI facility carries the undeniable allure of absolute data sovereignty, balance-sheet assets that can be amortized, and hardware tuned exactly to your workloads. But once you run the numbers, the polish fades quickly.
What you gain
| Benefit | Why it matters |
|---|---|
| Full control of the stack | You can hard-partition GPUs for regulated workloads, dictate upgrade cadence, and opt out of multi-tenant “noisy neighbor” risks. |
| Long-term depreciation | Capital assets can be written down over 3–5 years, turning today’s outlay into future tax shields. |
| Proprietary optimization | Teams can co-design networking topologies, cache hierarchies, and scheduling policies that would be impossible on a generic cloud SKU. |
Hidden costs:
- Hardware prices
- A single NVIDIA H100 still lists at approximately $25,000; an eight-GPU HGX node therefore starts near $200,000 and climbs higher with NVSwitch fabrics.
- Density drives costs further: the average AI rack is projected to hit $3.9 million thanks to liquid cooling, busbars, and redundant power trains.
- Facility & energy overhead
- Even a “small” green-field AI data center shell today costs between $10 million and $50 million before you add a single GPU.
- Cooling accounts for up to 40% of the total power draw; a 20,000-GPU cluster at 80% utilization consumes around 29 megawatts and incurs over $20 million per year in electricity costs at average US tariffs.
- Industry capital outlays reflect these numbers, as hyperscalers alone are expected to invest $320 billion in data-centre build-outs in 2025, signalling the substantial spend required to build AI infrastructure at scale.
- Lead-time risk
- While supply-chain logjams have eased, server OEMs still quote about 39 weeks for H100-class systems; a full campus build routinely stretches to 12 months. A single delay pushes model launches by entire fiscal quarters.
- Talent acquisition & retention
- The median 2025 salary for a machine learning engineer now tops $189,873 globally, excluding equity or bonus compensation.
- Nearly 44% of executives say a shortage of in-house AI expertise is their top roadblock to scaling generative AI products, a gap that Bain projects will persist through 2027.
- Recruiting timelines compound the bill: industry averages put advanced engineering hires at 2–3 months, and senior platform roles can stretch well beyond that—salaries effectively “accruing” before the first GPU is provisioned.
- Utilisation drag
- Private clusters rarely exceed 60% sustained utilization outside of big training cycles. Every idle rack hour amortizes capital expenditure across fewer model tokens, inflating the true cost-per-token far beyond the purchase price.
The takeaway
In-house builds work when your organization values absolute control, operates at a steady 70%+ utilization, and can absorb a year-long runway of sunk capital expenditure and hiring. For everyone else, the “hidden line items” in talent, energy, and lead-time risk tip the scales toward partnering, at least for the first production cycle.
Outsourcing to external experts: Advantages and trade-offs
Outsourcing your AI infrastructure to a specialist GPU cloud or managed services partner flips the economics and the timeline on its head. Here’s how:
1. Speed to first token
AI projects live or die on iteration velocity. Every week you wait for hardware is a week that a competitor’s model is learning from real-world feedback. External GPU clouds (CUDO Compute included) maintain a “warm” inventory: the racks, power train, and networking are already provisioned, and the control plane can carve out a slice in a matter of hours.
Internally, even with purchase orders approved, vendors still quote ~8-10 weeks for high-end cards, plus time for rack integration, burn-in, and security hardening. In a GenAI market where models leapfrog every quarter, those lost cycles show up as opportunity cost, not just calendar time.
Strategic nuance: Fast access is most valuable during the exploration stage, when architectures, data recipes, and prompt engineering jobs are constantly evolving. Once you converge on a stable training regime, the value of shaved weeks diminishes, and the calculus may shift toward in-house control or a reserved-capacity contract.
2. OPEX vs CAPEX flexibility
Finance teams are increasingly treating AI spend like SaaS: variable, usage-based, and easy to adjust up when a product demo is presented and down when executive priorities shift. Hourly billing converts a capital request that may require board approval into an operating expense that can be spread across quarters.
Strategic nuance: Variable spend is a two-edged sword. Without tight cost governance, surprise bills can arise, especially when hyperparameter sweeps or long-tail fine-tuning runs overnight. Mature teams set budget service level objectives (SLOs) alongside latency and accuracy SLOs, and they integrate these objectives into their CI/CD pipelines so that jobs slow down or pause when they threaten to exceed their allocated resources.
3. Price-per-GPU
The headline rate difference (H100 at $2.50/h on CUDO vs. over $8 on AWS) compounds rapidly at scale. A 64-GPU training run that takes 300 hours looks like:
| Provider | Rate (USD/h) | 64 GPUs × 300 h | Total |
|---|---|---|---|
| CUDO Compute | $2.47 | $47,424 | $47k |
| AWS | $8.25 | $158,400 | $158k |
After you factor in egress and management fees, you sit 2-3 times cheaper.
Strategic nuance:
- Spot vs reserved: Some clouds quote eye-catching spot prices, but preempt your job. If your training loop can’t checkpoint or restart inexpensively, “cheap” compute may be expensive in developer time.
- Commit blocks: Locking in a 12-month commitment often reduces CUDO rates by 20-40%. That starts to resemble amortized in-house cost, without tying up capital or talent.
4. 24×7 Ops and compliance
Running a GPU cluster is a facilities and security discipline as much as an engineering one, as you’ll need firmware patches, kernel CVEs, rack-level power anomalies, and ISO audit paperwork. Providers spread that operational burden across hundreds of customers, achieving economies that your single organization rarely can.
Strategic nuance: Your internal security posture doesn’t disappear; you still own data classification, encryption, and role-based access. The real win is shifting infrastructure compliance (SOC 2, ISO 27001, PCI) to a vendor whose business model already demands it, allowing your security team to focus on application-layer threats.
5. Skills injection
Partners bring experience from dozens of rollouts, having debugged NCCL halo hangs, tuned MIG partitions, and scripted continuous integration (CI) for sharded checkpoints. Your engineers absorb that tribal knowledge by osmosis, shortening their own learning curve.
Strategic nuance: Make the partnership deliberately instructional by pairing your ML engineers with the vendor’s platform site reliability engineering (SREs) during on-call rotations, or negotiate shadowing sessions. Otherwise, you risk creating a permanent dependency instead of transferring skills.
6. Elastic utilization
Few organizations maintain over 70% GPU utilization year-round. External clouds let you scale to 100% during a model’s training sprint, then downshift to a handful of inference nodes. Idle on-premises racks, by contrast, continue to depreciate regardless of the circumstances.
Strategic nuance: If you foresee predictable high utilization (e.g., a SaaS with steady inference traffic plus quarterly model refreshes), consider a hybrid approach. For instance, a small baseline capacity in-house for inference, and bursting to the cloud for training, which caps OPEX volatility while minimizing idle GPUs.
Trade-offs in depth
| Risk | Why it’s real | Mitigation |
|---|---|---|
| Vendor lock-in | Tooling ecosystems (storage APIs, scheduler semantics) can create switching costs. | Adopt open-source orchestration (Kubernetes, Kubeflow) and insist on data-egress clauses that mirror ingress rates. |
| Premium pricing at peaks | Demand spikes (such as new GPU launches or viral models) trigger surge pricing. | Buy reserved blocks or capacity futures and benchmark break-even against on-premises costs. |
| Less topology control | You can’t overhaul the network fabric or the cooling profile. | Negotiate SLAs for inter-GPU bandwidth and rely on MIG partitioning for noisy neighbor isolation. |
| Shared-tenancy risk | Side-channel attacks are a genuine threat. | Require confidential-compute features (such as memory encryption and hardware-verified isolation) and third-party penetration test attestations. |
| Opaque forecasting | Hourly billing is noisy; finance hates surprises. | Instrument cost telemetry at the job level and roll it into your observability stack; use anomaly alerts just like latency errors. |
The external-expert route is essentially a time-and-variance arbitrage: you trade some architectural sovereignty for (a) an accelerated launch window and (b) reduced cost volatility. The closer your roadmap pressures you to deliver now, and the scarcer your specialist talent, the more weight that arbitrage carries. Conversely, as your workloads stabilize and utilization rises, the pendulum often swings back toward building or, at the very least, reserving dedicated capacity.
The pain-point spotlight
The build-vs-buy debate narrows to a single choke point: access to high-end GPUs when needed, at a cost-effective price.
1. Supply is easing from critical to hard
Lead times for NVIDIA’s Hopper H100 have fallen from 8-11 months at the 2023 peak to roughly 2-3 months today, thanks to expanded CoWoS packaging lines and ODM ramp-ups. That is still a full fiscal quarter of waiting if you’re building in-house, and new Blackwell B100/B200 parts are strictly “on request” until late 2025.
2. On-demand prices remain a roller coaster
Independent clouds now advertise H100 SXM at $2.40–$3.00 per GPU-hour; CUDO Compute falls within the lower end of that range. Major hyperscalers, by contrast, still price the same GPU at the equivalent of $8–$ 12 per GPU hour. When a 64-GPU, 300-hour training run can swing between approximately $50,000 and $230,000, cost visibility becomes as critical as FLOPS.
3. Reserved capacity vs queues
Cloud providers now offer two distinct lanes:
- On-demand/spot: Instant, but surge pricing can apply, and instances can be reclaimed.
- Reserved blocks or capacity futures: Lock-in 12- to 36-month contracts at a 20-40% discount and guaranteed start dates.
Teams without reservations still face wait-lists during product-launch spikes; Amazon’s internal “Project Greenland” was born entirely to triage such queues.
4. Why this matters for skills-gap decisions
Every extra month in a hardware queue magnifies the value of external partners who already hold capacity blocks. Conversely, if you can guarantee over 70% utilization, a reserved cluster—whether owned or contracted—may outprice cloud on-demand.
Rule of thumb: If your forecast shows utilization below ~60% or you need GPUs within 90 days, buy time, not GPUs.
How to bridge the skill gap
The hardware decision is only half the story; the steeper cliff is peopleware. As stated earlier, 44% of global executives name “lack of in-house AI expertise” as the single biggest blocker to Gen-AI roll-outs. This gap is expected to persist through 2027.
Below are the three practical paths organizations use to bridge the skill gap, along with realistic timelines and caveats.
1. Upskill the engineers you already have
Sending data, platform, or backend engineers through an ML “bootcamp” is the least disruptive route culturally, as it requires no new headcount approvals, no onboarding frictions, and people who already understand your codebase gain new capabilities.
- Timeline: Full-time ML bootcamps now run between12 and 16 weeks on average. Part-time or employer-sponsored tracks can extend to 26 weeks. Graduates still need a few additional weeks inside your pipelines before they’re producing reliable models, so plan on roughly a quarter from the first day of training to the first production pull request.
- Cash outlay: Tuition hovers around $13,000–16,000 per person, plus the hidden cost of backfilling their former duties while they are studying.
- Benefits:
- Strengthens morale and retention—people see a growth path in-house.
- Creates T-shaped engineers who can bridge ML and the rest of your stack.
- Watch-outs.
- Bootcamp grads still need senior ML mentorship; without it, their early experiments risk sprawl or technical-debt traps.
- Opportunity cost: Your most versatile engineers are learning, not shipping, for several months.
When to choose it: When product deadlines are elastic and you’re building a bench for the long haul rather than racing to hit a market window.
2. Recruit proven ML or MLOps talent
Hiring seasoned specialists brings instant credibility and, over time, deeper domain knowledge; however, it is the slowest and most expensive path.
- Timeline: LinkedIn’s 2024–25 hiring data indicate that it now takes approximately 5–6 months to recruit and fully onboard a senior machine-learning engineer. Delays come from multi-round interviews, competing offers, and lengthy notice periods.
- Cash outlay: As stated earlier, the global median total compensation for ML engineers reached $ 189,873 in 2025, before equity or bonuses. Add recruiter fees (20–30% of first-year salary) and relocation or signing bonuses, and you’re well past $225,000 for the first year before they train a single model.
- Benefits:
- Tight control of IP and model governance.
- Institutional memory continues to accrue internally year after year.
- Watch-outs:
- Large cash burn before any model ships, as it is risky if budgets tighten.
- The exact roles you need, like distributed-training SREs and large-scale evaluation engineers, are in extreme shortage worldwide.
When to choose it: Once the business case is proven, utilization is steady, and you’re willing to pay a premium for long-term self-reliance.
3. Co-create with external experts (“talent-on-demand”)
Specialist GPU-cloud or consultancy partners parachute in small, cross-functional pods—typically platform/SRE, ML, and data engineers—and bring a live hardware stack with them.
- Timeline: Top-tier GPU clouds ship pre-configured Slurm or Kubernetes clusters that cut “time-to-useful work” from days to hours, and customers regularly report launching their first fine-tune or proof-of-concept within two to four weeks of contract signature.
- Cash outlay: Costs are rolled into day rates or project fees, with no recruiter commissions and no long-term salary commitments. In accounting terms, this is pure OPEX, easier to scale down when the burst of work ends.
- Benefits:
- Immediate velocity: Critical when board mandates require a demo this quarter.
- Knowledge transfer: Your team shadows veterans who have already debugged NCCL hangs, Slurm topology files, and MIG quirks.
- Watch-outs.
- Risk of permanent dependency if you don’t codify a hand-off plan.
- Vendor selection and contract negotiation matter, so ensure clear SLAs, exit clauses, and data-egress terms.
When to choose it: Whenever time-to-market is the overriding metric, or while you’re still hunting for permanent hires but can’t pause the roadmap.
| Path | Ramp-to-productivity* | Typical cash outlay | Key pros | Key cons |
|---|---|---|---|---|
| Upskill existing staff (bootcamps, internal rotations) | 12–18 weeks — median ML bootcamp runs ~14 weeks + 2-4 weeks to embed practices | Tuition ≈ $13k per head (bootcamp avg.), plus backfill time for day jobs | Preserves culture; boosts retention; good for steady talent drip | Slower start; bootcamp grads still need mentoring; opportunity cost while learning |
| Direct hiring of ML / MLOps engineers | 5–6 months to hire and fully onboard a senior ML engineer | Fully-loaded annual comp ≈ $190 k (mid-senior), plus recruiter fees | Long-term IP ownership; deep domain context | Highest cash burn before first model ships; global talent pool still < demand |
| Talent-on-demand / co-creation with external experts | 2–4 weeks—GPU-cloud partners arrive with battle-tested playbooks and warm hardware | Day-rate or project fee; no recruiter cost; rolled into OPEX | Instant velocity, knowledge transfer baked in; de-risks first launch | Requires a knowledge-capture plan to avoid permanent dependency |
*Ramp = clock time from engagement start to a team delivering working model artefacts in staging. Sources: Forbes boot-camp pricing analysis forbes.com; LinkedIn hiring-timeline study linkedin.com; SemiAnalysis ClusterMAX customer feedback on cloud-partner onboarding semianalysis.com.
Think of these three paths as complementary, not mutually exclusive:
- Borrow expertise first (external pod) to ship a pilot and capture quick wins.
- Upskill internal staff in parallel, so they can inherit and extend the solution.
- Recruit strategic specialists once the product proves its ROI, and you can justify high fixed costs.
Sequencing in that order allows you to bridge the skills gap without stalling the business—or overcommitting cash—while building a sustainable, in-house AI capability.
How to use hybrid and phased models
Pure “all-cloud” and “all-on-prem” strategies sit at the ends of a spectrum. Most organizations now land somewhere in the middle, mixing external capacity for burst speed with owned or reserved clusters for steady-state efficiency and edge nodes for ultra-low-latency inference.
These are three practical blueprints that dominate current architectural roadmaps:
| Blueprint | How it works | When it shines | Watch-outs |
|---|---|---|---|
| Burst-then-Repatriate | 1) Prototype and first training cycles run on a GPU cloud. 2) Once utilization forecasts exceed ~70%, migrate the mature workload to an owned or long-term reserved cluster. 3) Reserve cloud capacity for future experiments. | Fastest time-to-market and lowest long-run $/token once demand is predictable. | Data egress costs during migration; need for dual tool-chains if stacks diverge. |
| Dual-Track Inference | • Latency-sensitive inference moves to edge gateways (4-8 GPUs / node). • Batch or non-SLA inference stays in the cloud or central DC.• Training remains wherever the cheapest, dense fabric lives. | Customer-facing apps where <50 ms round-trip ≈ revenue (voice bots, real-time fraud scoring). | The Ops team must juggle two release cadences; edge nodes still require observability and patching. |
| Capacity Futures | • Sign 12–36 months “GPU-capacity futures” with a provider—essentially Colo-as-a-Service.• Provider guarantees racks, power, cooling; you supply images & orchestration.• Option to purchase the hardware at the end of the term. | When you want near-OEM pricing without building a data centre, it fits CFOs wary of 100% OPEX. | Contract complexity: exit clauses, extension pricing, hardware refresh terms. |
Why hybrid wins in practice
- Smoother cash curve: Up-front cloud OPEX avoids the 6 to 12-month capex hole that sinks many green-field builds; repatriation later captures depreciation benefits once revenue is proven. A survey reveals that 58% of AI-native scale-ups now follow a burst-then-repatriate cadence, up from 41% two years ago.
- Queue-busting flexibility: Cloud GPUs absorb demand spikes (model refresh, marketing demo) while owned servers keep a high utilization. Cisco’s 2024 hybrid-cloud blueprint notes that even hyperscalers maintain small on-premises “AI pods” for internal testing and development.
- Latency where it counts: Edge-cloud collaborative inference frameworks, such as Hybrid SD for Stable Diffusion, cut cloud costs by 66% while meeting tight latency budgets, proving that splitting the diffusion pipeline is feasible today.
- Risk hedging: When you experience a supply delay, your cloud infrastructure can step in, and when a vendor hikes prices, you can redirect more traffic to your owned server. This optionality is why Gartner puts hybrid AI infrastructure on its list oftop strategic technology trends for 2026.
Talent ramp in a hybrid scenario
Hybrid models also dovetail with the skills-gap paths from the previous section:
- Phase 0: The external partner supplies the full SRE/ML platform pod.
- Phase 1: Internal hires shadow; bootcamp grads join feature-store and data-pipeline work.
- Phase 2: The core training cluster migrates; the partner remains on retainer for peak bursts and architecture reviews.
By the time the first on-premises rack reaches 70% utilization, your internal team is often within one hiring cycle of achieving self-sufficiency.
Decision framework & checklist
Choosing between an in-house build, a managed partner, or a hybrid path is less guesswork when you score each option against a seven-factor rubric. Weight the factors to match your organization’s priorities, rate each option 1 – 5, then tally.
This simple worksheet turns the scores into traffic-light guidance:
| Factor | What you’re really asking | Weight† | Score Build | Score Hybrid | Score Partner |
|---|---|---|---|---|---|
| Data gravity & sovereignty | Does large, sensitive data have to be stored on-premises? | 4 | 5 | 3 | 1 |
| Capex headroom | Can finance absorb multi-million-dollar hardware outlays today? | 3 | 1 | 3 | 5 |
| Regulatory burden | Will regulators audit the physical cluster? Do we need sovereign hosting? | 3 | 4 | 4 | 2 |
| Talent pool depth | How many proven ML-infra engineers can we hire/retain in the next 6 months? | 4 | 2 | 3 | 5 |
| Time-to-market pressure | Do we need a production model inside 1–2 quarters? | 5 | 1 | 4 | 5 |
| GPU availability | Can we secure more than 70% of the GPUs we need within 90 days? | 4 | 2 | 4 | 5 |
| Cultural appetite for vendors | Are we comfortable co-owning the roadmap with an external partner? | 2 | 2 | 4 | 5 |
†Weights are defaults from CUDO Compute workshops—tweak them to fit your board’s KPIs.
How to use the matrix
- Assign weights (0–5) to each factor based on its strategic importance.
- Fill scores (1 = poor, 5 = excellent) for each deployment path.
- Multiply & sum: Highest composite score marks the front-runner.
- Sanity-check the outliers: If one factor is mission-critical (e.g., data sovereignty in healthcare), override the tally accordingly.
Rule of thumb:
- Score over 80% of max: Pursue that option.
- Score 60 – 80%: Pilot a hybrid or phased approach.
- Score under 60%: Revisit assumptions or defer the project.
Quick-hit checklist before you commit
- Business case signed off: Align infrastructure spend with a revenue or cost-avoidance target.
- Utilization forecast complete: Base it on token volume, not just GPU hours.
- Capacity reservation in writing: For partners, lock-in SLAs and surge-rate caps.
- Data-transfer plan: Budget for egress or migration tooling.
- Security and compliance map: Confirm ISO/SOC attestations and tenant isolation technology.
- Skills-transfer clauses set: Ensure external experts pair with internal staff.
- Exit strategy defined: Identify triggers (utilization, cost crossover, policy change) that would prompt repatriation or deeper build-out.
Pro tip: Run the checklist at every major roadmap milestone; fast-moving AI markets can flip a “buy” answer to “build” within six months if talent availability, GPU pricing, or regulation shifts.
Cost of running AI workloads
To illustrate how the decision matrix translates into dollars, let’s walk through a three-year cost scenario for a mid-sized generative AI team that requires a 64-GPU training cluster and a small inference fleet.
| Input Variable | On-Demand Cloud (CUDO Compute) | Hyperscale Cloud (AWS P5) | Owned Cluster |
|---|---|---|---|
| GPU type | H100 PCIe | H100 SXM | H100 SXM |
| Hourly rate (1 yr commit) | $1.80/GPU-h www.cudocompute.com | $6.50/GPU-h (post-June 2025 cut) cyfuture.cloudaws.amazon.com | N/A |
| Hardware cost | OPEX | OPEX | $ 34,000 × 64 = $2.18M Capex |
| Power draw per GPU | 350 W (PCIe) | 700 W (SXM) | 700 W (SXM) |
| Training runtime/cycle | 300 h | 300 h | 300 h |
| Cycles/year | 4 | 4 | 4 |
| Inference footprint | 8 GPUs × 24 × 365 | same | same |
| Electricity price | included | included | $0.10 / kWh |
1 . Training Costs (Year 1)
| Path | 64 GPUs × 300h × 4 cycles | Year-1 Spend |
|---|---|---|
| CUDO Compute | 76,800 GPU-h × $1.80 | $138 k |
| AWS P5 | 76,800 GPU-h × $6.50 | $499 k |
| Owned Cluster | Capex $2.18 M + rack & integration $0.45 M | $2.63 M |
2 . Inference Run-Rate (Annual)
Eight PCIe H100s at 350 W each draw 28 kW; with a 1.4 PUE, that’s 344 MWh/year, or $34,000 in electricity. Cloud pricing folds power into the hourly rate:
| Path | GPU-h / year (8 × 24 × 365) | Annual Inference OPEX |
|---|---|---|
| CUDO Compute | 70 080 × $1.80 | $126,000 |
| AWS P5 | 70 080 × $6.50 | $456,000 |
| Owned Cluster | Power $34,000k + maintenance 10% of capex | $252,000 |
3 . Three-Year Cumulative Spend
| Path | Year 1 | Years 2–3 (incl. 5% price decline) | Total 36-mo. |
|---|---|---|---|
| CUDO Compute | $264k | $502k | $766k |
| AWS P5 | $955k | $1.75M | $2.70M |
| Owned Cluster | $2.88M | $0.50M | $3.38M |
What the numbers tell us
- Cloud OPEX dominates in Year 1: CUDO is 5 times cheaper upfront than a new data center build.
- Cost crossover occurs late: With four major training cycles per year, the owned cluster only overtakes CUDO Compute in month 34, assuming 80%+ utilization and no hardware refresh.
- Inference spending matters: Because token volumes balloon post-launch, the inference line item grows from ~30% of the budget in Year 1 to over 50% by Year 3, reinforcing the need for lower-energy hardware, quantization, or edge offload.
- Hyperscale premiums compound: AWS ends three years almost 3.5× costlier than CUDO and still trails the owned cluster crossover point by six months.
Sensitivity knobs in the calculator
- Utilization slide: Shows how idle time drags the owned-cluster ROI.
- Price-decline curve: Model annual 10–25% cloud rate cuts or Moore-style hardware price drops.
- Power tariff selector: Swap $/kWh for your region to see the energy impact.
- Cycles-per-year: Bump training frequency to test GenAI product cadences.
Takeaway: Unless you can guarantee high utilization and amortize $2–3 M in capex quickly, renting GPUs, especially at independent-cloud rates, wins on both cash flow and risk. The hybrid “burst-then-repatriate” approach becomes economically viable only after the first year’s production data validates a sustained workload.
AI success hinges on matching the right hardware, the right people, and the right timing to your business goals. Our walkthrough demonstrates how external experts expedite the first mile, how hybrid models mitigate long-term costs, and when owning GPU servers finally pays off, but only when utilization and talent are already in place.
Use the seven-factor rubric and the cost calculator to ground every decision in hard numbers rather than vendor hype. Re-run the analysis at each roadmap milestone because GPU prices, inference volumes, and hiring realities shift quarter by quarter.
Most importantly, build a skills-transfer plan into any partnership so your organization’s capability grows alongside its infrastructure footprint. With clear metrics, phased planning, and a culture of continuous learning, you can bridge today’s skills gap and deploy AI at the pace your market demands.
Ready to see how your numbers stack up? Reach out to CUDO Compute’s solution architects for a tailored roadmap that meets both your budget and launch date requirements.
