 Resources
Resources 
Advanced AI algorithms like Generative AI rely heavily on hardware performance and reliability. The complexity and scale of computations involved in the training and inference of these models require robust and reliable hardware.
Issues like hardware failures, overheating, and computational inefficiencies can significantly impact the development and deployment of generative AI models. This makes the conversation about hardware reliability important, albeit sometimes overlooked, in the AI community.
Ensuring hardware reliability is crucial in AI development. Unreliable hardware can have negative consequences, ranging from minor inconveniences like losing valuable training data and progress to catastrophic failures resulting in the loss of months of training.
In this article, we’lll examine the challenges associated with traditional on-premises hardware setups and discuss why cloud GPUs offer a viable solution for achieving and maintaining high levels of hardware reliability.
What is hardware reliability in AI?
Hardware reliability refers to the ability of the underlying computing infrastructure to consistently perform its intended functions without failure over a specified period. This encompasses various aspects, including the prevention of hardware failures, mitigation of errors, and recovery from disruptions.

Within GPU clusters used for AI training and inference, reliability is the ability of the interconnected GPUs and supporting infrastructure to consistently perform their intended functions without failure over extended periods, which is important for AI training and other high-performance computing tasks that require sustained processing power.
Reliability can be quantified by metrics such as Mean Time Between Failures (MTBF), which estimates the average operational time before a failure occurs, and Mean Time To Repair (MTTR), which measures the average time to restore the system after a failure. A higher MTBF indicates greater reliability, as it suggests longer intervals between failures, while lower MTTR values indicate that the system can be quickly restored to operational status, minimizing downtime.
Here are some of the most common reliability problems in GPU clusters:
Common Reliability Problems in GPU Clusters
- GPU HBM ECC Errors:
HBM (High Bandwidth Memory) ECC (Error Correcting Code) errors refer to errors that occur in the high-speed memory used in modern GPUs. ECC is a mechanism designed to detect and correct errors in memory to maintain data integrity and prevent crashes or malfunctions.
HBM ECC errors can be classified into two types:
- Correctable Errors: These are minor errors that the ECC mechanism can detect and correct without affecting the GPU's operation.
- Uncorrectable Errors: These are more severe errors that the ECC mechanism cannot correct. They can lead to data corruption, crashes, or other malfunctions in the GPU.
Different things might lead to GPU HMB ECC errors; here are a few of them:
- Manufacturing Defects: Defects in the HBM chips or interconnects can lead to errors during operation.
- Wear and Tear: Over time, HBM components can degrade due to factors like heat, voltage fluctuations, or particle radiation, increasing the likelihood of errors.
- Overclocking: Pushing the GPU beyond its factory-specified limits can stress the HBM and increase the risk of errors.
- Software Issues: Faulty drivers or software bugs can also trigger HBM ECC errors.
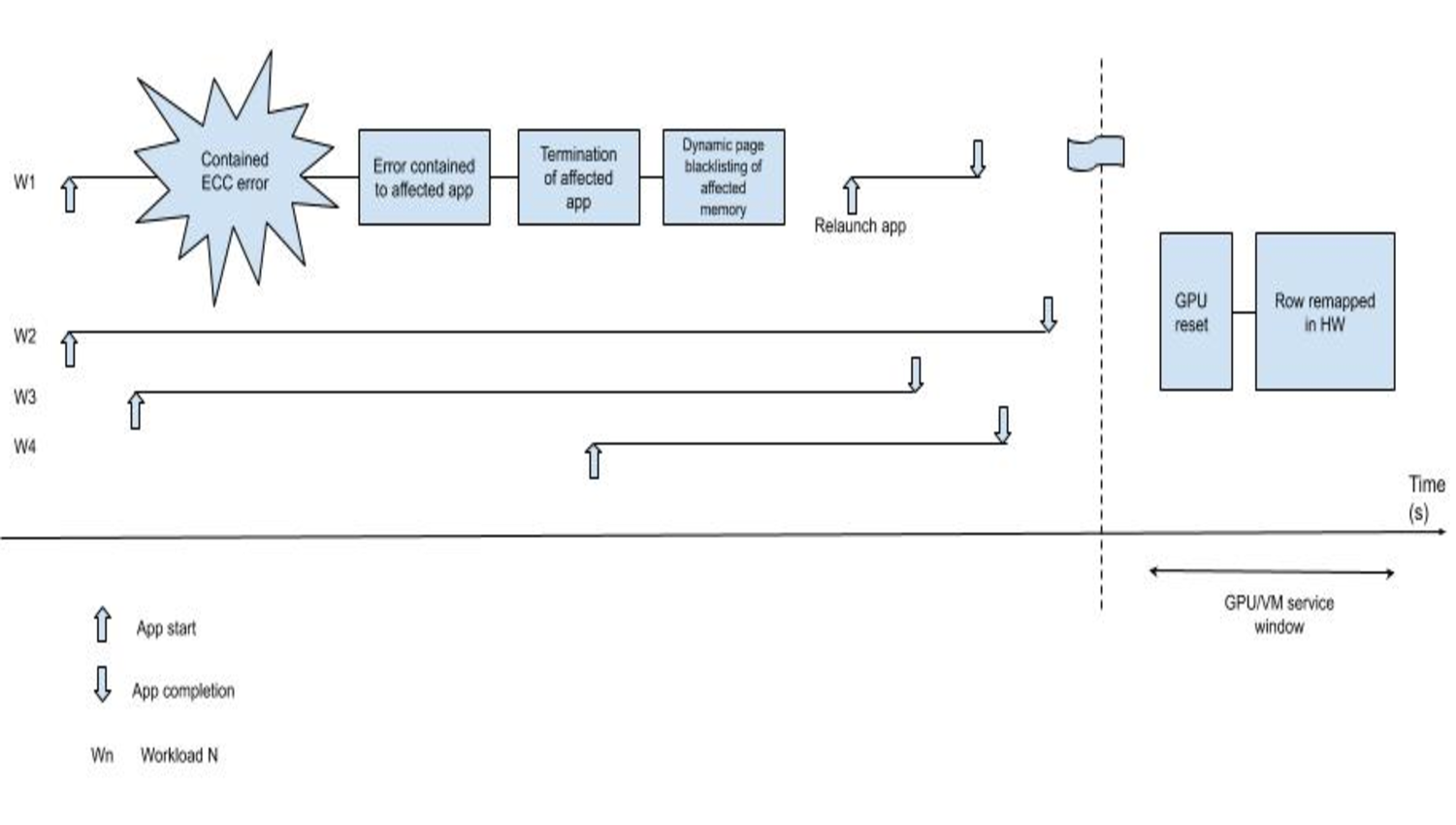 Source: NVIDIA
Source: NVIDIA
One of the best ways to reduce the chances of HMB ECC errors is to use GPUs with error-handling mechanisms like the NVIDIA H100. You can start using the NVIDIA H100 on CUDO Compute with a few clicks. Sign up to begin.
- GPU Drivers Getting Stuck:
GPU drivers getting stuck leads to a situation where the software that controls your graphics processing unit (GPU) stops responding or becomes unresponsive. This can manifest in several ways:
- Screen freezes: The display may freeze completely, with no movement or response to input.
- Black screen: The screen may go black, but the computer remains powered on.
- Error messages: You might see error messages like "Display driver stopped responding and has recovered" or a similar notification.
- Performance issues: Even if the display doesn't freeze entirely, you might experience lag, stuttering, or other performance problems in graphics-intensive applications.
Some of the causes of GPU driver issues in clusters are:
- Driver Incompatibilities: Different GPUs within the cluster might have varying driver versions or configurations, leading to conflicts and instability.
- Communication Problems: Issues with the software or network communication between GPUs can cause drivers to hang or crash.
- Workload Imbalance: If workloads are not distributed evenly across GPUs, some GPUs might be overloaded, leading to driver crashes due to excessive stress or resource exhaustion.
- Hardware Failures: Faulty GPUs or other hardware components can trigger driver errors, affecting the entire cluster.
Stuck drivers can cause running jobs or tasks to fail, leading to delays and lost productivity. Frequent driver crashes can make the entire cluster unstable, requiring restarts or manual intervention to restore functionality. Even if the cluster remains operational, driver issues can lead to reduced performance and inefficient utilization of GPU resources.
- Optical Transceivers Failing:
Optical transceivers are essential components in GPU clusters. They enable high-speed communication between GPUs, servers, and storage systems over fiber optic cables, aiding efficient data transfer and coordination in AI workloads.
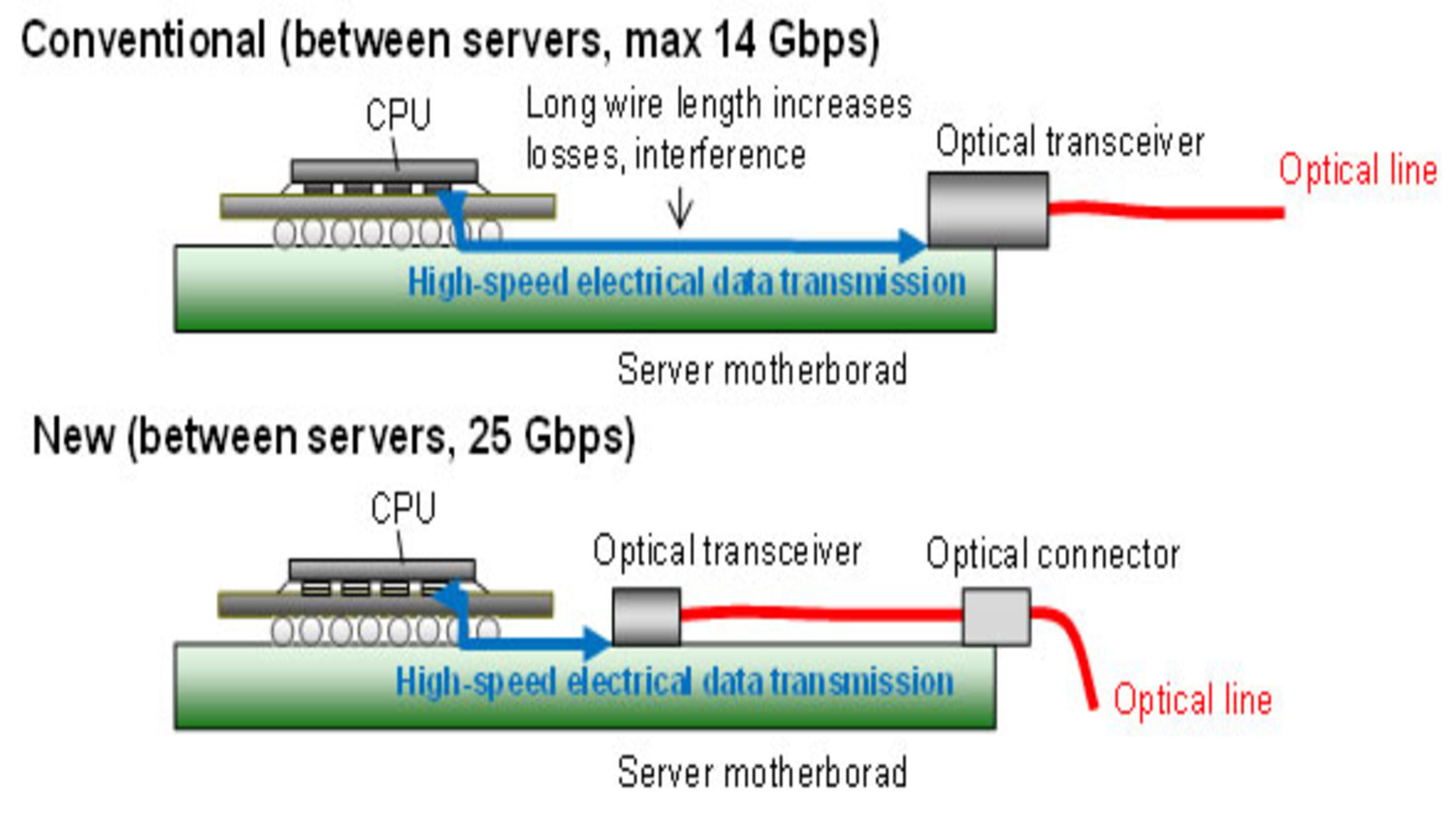 Source: Fujitsu
Source: Fujitsu
Optical transceivers can fail due to:
- Thermal Stress: Optical transceivers generate heat during operation, and excessive heat can degrade their performance and lifespan. Inadequate cooling or high ambient temperatures can accelerate this process.
- Laser Degradation: The lasers within optical transceivers can degrade over time due to factors like aging, temperature fluctuations, and high-power operation.
- Physical Damage: Physical stress, such as vibration, shock, or mishandling, can damage the delicate components within optical transceivers.
- Manufacturing Defects: Defects in the manufacturing process can lead to premature failures of optical transceivers.
A failed optical transceiver can disrupt communication between GPUs and other components in the cluster, leading to performance degradation, errors, or even complete system outages.
If the failure occurs during a critical data transfer, it can result in data loss or corruption. Replacing failed optical transceivers requires downtime and maintenance, impacting productivity and potentially incurring significant costs.
- NICs Overheating:
Network Interface Cards (NICs) can overheat under high load conditions, particularly in poorly ventilated environments. Overheating can cause the NICs to fail or throttle performance.
The high throughput of AI workloads due to the amount of data transferred between GPUs can push NICs to their limits, generating substantial heat that can exacerbate NIC overheating.
As NICs overheat, their performance can degrade, leading to slower data transfer rates, increased latency, and potential errors. Prolonged exposure to high temperatures can damage NIC components, shortening their lifespan and potentially leading to permanent failure.
One of the challenges when dealing with reliability is that GPUs are directly connected to each other through PCIe switches, so there is no fault tolerance at the network architecture level. What this means is that if one NIC, transceiver, or GPU fails, the whole server is considered down.
With all these said, here is how to avoid reliability issues:
How to prevent hardware reliability issues
The challenges discussed above underscore the importance of proactive measures to avoid or, at least, reduce hardware reliability issues. Here are some steps to help improve the reliability of your GPU:
- Use fault tolerance technique:
Fault tolerance is designing systems that can continue operating, sometimes at reduced capacity, even when individual components fail. Redundancy is a fundamental aspect of fault tolerance and can be implemented at multiple levels.
At the hardware level, incorporating redundant power supplies, network interfaces, and storage devices ensures that another seamlessly takes over if one fails. Having hot-swappable spares ready for immediate replacement for critical components like GPUs can significantly reduce downtime.
For data, real-time replication across multiple storage locations or cloud services safeguards against data loss due to storage failures. Additionally, software-level fault tolerance techniques, such as checkpointing, can help preserve progress in long-running AI workloads, allowing them to resume from a saved state in case of interruptions.
It would be beneficial to use fault tolerance training techniques like Oobleck. Oobleck provides a fault tolerance approach for large-scale distributed training of deep neural networks (DNNs). Here’s how it works:
- Pipeline Templates: Oobleck uses a planning-execution co-design approach. It first generates pipeline templates that define how many nodes to assign to a pipeline, the stages to create, and how to map model layers to GPUs. This decoupling allows for fast failure recovery by replacing lost nodes with new pipeline templates.
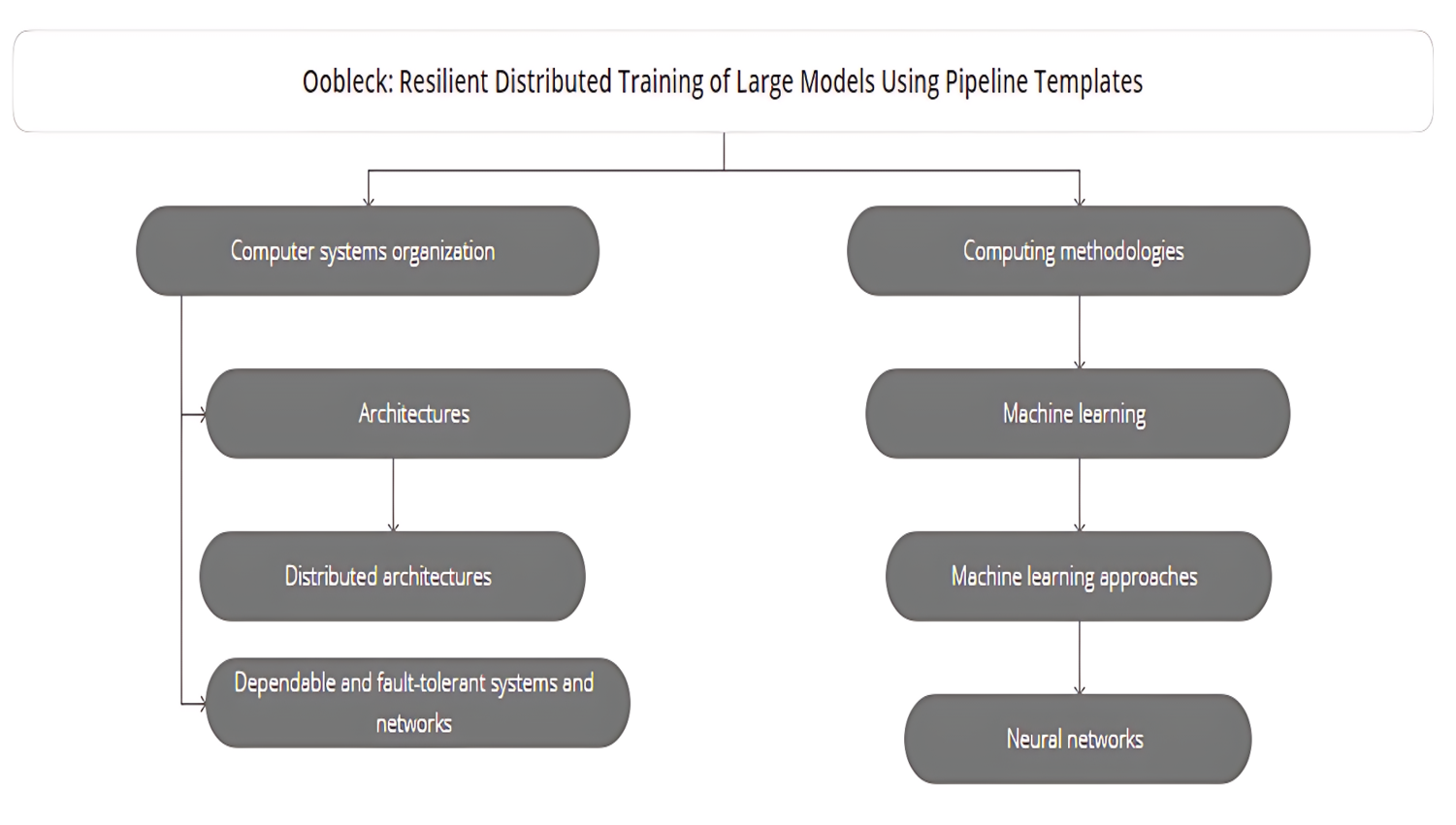 Source: AMC DL
Source: AMC DL
- Redundant Computation: Oobleck instantiates multiple (f + 1) logically equivalent pipeline replicas to tolerate any f simultaneous failures. This redundancy ensures that even if multiple nodes fail, training can continue without needing a full restart.
- Checkpointing: While traditional checkpointing methods involve storing training progress and restarting from the most recent checkpoint after a failure, Oobleck reduces the recovery time by dynamically reconfiguring the training jobs without significant overhead.
- Recovery without Restart: Oobleck guarantees fault tolerance by allowing for reconfiguration without restarts for up to a specified number of simultaneous failures. This minimizes downtime and maintains high training throughput even in the presence of frequent failures.
Oobleck has been evaluated on large models like GPT-3, demonstrating its ability to maintain high throughput and effective fault tolerance. The system is designed to handle the growing complexity and scale of modern AI models, providing a resilient and efficient solution for distributed training environments.
- Software resilience through streamlined design and intelligent management
While robust hardware is essential, software also plays a significant role in ensuring cluster reliability. Complex, poorly structured codebases can lead to errors and vulnerabilities. Therefore, it is important to adopt a streamlined and modular design approach.
Breaking down complex code into smaller, manageable modules with well-defined interfaces enhances code maintainability and reduces the risk of cascading failures. Furthermore, incorporating thorough error handling and automated testing helps identify and rectify issues before they impact cluster operation.
- Hardware reliability
The foundation of a reliable GPU cluster lies in selecting high-quality hardware components. GPUs with built-in error correction mechanisms, such as ECC memory, can automatically detect and correct memory errors, preventing crashes and data corruption.
Choosing GPUs with effective thermal throttling ensures that performance is dynamically adjusted to maintain safe operating temperatures, safeguarding against thermal damage. Investing in enterprise-grade network interface cards (NICs) and durable optical transceivers further enhances the resilience of the communication infrastructure within the cluster.
Additionally, adequate cooling and airflow management helps prevent overheating, which can significantly increase component lifespan and reliability.
By combining fault-tolerant design principles, robust software practices, and high-quality hardware components, organizations can create GPU clusters that are resilient to failures, ensuring uninterrupted operation and maximizing the value of their AI investments.
While the strategies above can enhance the reliability of on-premises GPU clusters, the inherent complexities and costs associated with building and maintaining such infrastructure can be a significant burden.
Cloud services like CUDO Compute, with their scalable and managed infrastructure, offer a compelling alternative for organizations seeking to streamline their AI initiatives and focus on core research and development. Here is how.
How cloud GPUs solve AI hardware reliability
One of the advantages of cloud GPUs is their inherent scalability. Organizations can easily scale up or down their GPU resources based on their workload demands, eliminating the need for large upfront investments in hardware. This elasticity enables them to handle peak workloads without overprovisioning resources during periods of lower demand, ensuring optimal cost efficiency.
 Source: Server Simply
Source: Server Simply
- Redundancy and high availability built-in: Cloud providers typically design their infrastructure with redundancy in mind. For instance, CUDO Compute offers multiple critical component instances, such as servers, storage devices, and network infrastructure, available within the cloud environment. If one component fails, the workload can be seamlessly transitioned to another, minimizing downtime and ensuring high availability.
- Managed infrastructure and offloading maintenance burden: Cloud providers take on the responsibility of managing the underlying hardware infrastructure, including maintenance, updates, and repairs. This frees up valuable time and resources for organizations to focus on their core AI research and development activities rather than dealing with the complexities of hardware management.
- Global Reach and Accessibility: Cloud GPUs are accessible from anywhere in the world with an internet connection, enabling geographically distributed teams to collaborate seamlessly on AI projects and facilitating disaster recovery by allowing organizations to quickly spin up new resources in a different location in case of regional outages.
- Cost Efficiency and Pay-as-You-Go Model: Cloud GPU providers like CUDO Compute typically operate on a pay-as-you-go model, where organizations only pay for the resources they actually use, eliminating the need for large upfront investments and allowing for more predictable budgeting. Additionally, CUDO Compute offers GPUs on demand, on reserve, and tailored contracts to suit your workload, further optimizing cost efficiency.
- Addressing Reliability Challenges: Cloud GPU services can effectively address many of the reliability challenges discussed earlier. For instance, the redundancy built into cloud infrastructure mitigates the risk of single points of failure. Managed infrastructure ensures that hardware is regularly updated and maintained, reducing the likelihood of issues arising from outdated components or software. Furthermore, cloud providers often have robust disaster recovery plans in place to ensure business continuity in case of major disruptions.
CUDO Compute offers the latest NVIDIA GPUs to speed up your model training and inference at the lowest rates. Sign up for free today.
