 Resources
Resources 
Large language models (LLMs) like OpenAI’s GPT series and Google’s BERT have become foundational technologies powering many applications, from automated customer service to advanced research tools.
However, training LLMs requires a substantial financial investment due to their vast number of parameters and the enormous computational power needed. It typically involves high-end GPUs or specialized AI accelerators, which are costly resources to acquire and run.
For example, while the original 2017 Transformer that introduced the core LLM architecture cost only about $900 to train, the compute cost for training GPT-3 (175 billion parameters) was estimated in 2020 to range from about $500,000 up to $4.6 million, depending on the hardware and optimization techniques used. By comparison, newer models have pushed costs much higher.
Training OpenAI’s GPT-4 reportedly cost more than $100 million, with some estimates ranging up to $78 million in compute cost, and Google’s Gemini Ultra model is estimated to have cost $191 million in training compute. These staggering sums partly reflect why model size and complexity have exploded.
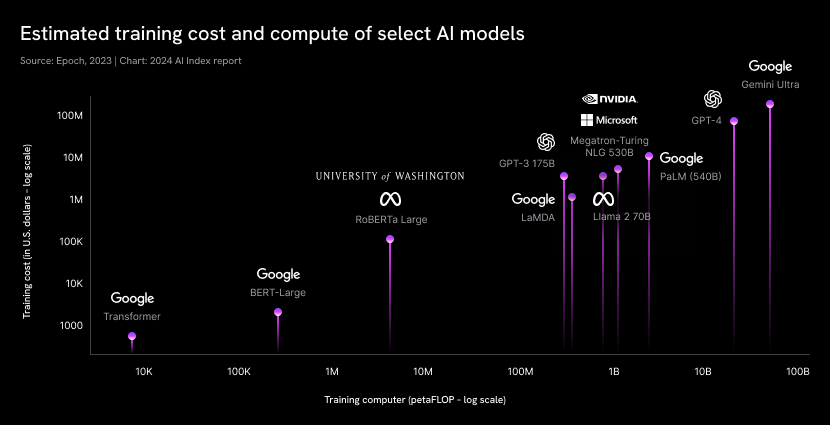
Training compute petaFLOP log scale. Source: Paper
In this article, we’ll explore the expenses of bringing modern generative AI and reasoning models to life, focusing on infrastructure needs, data management, and the increasingly important role of cloud computing.
What are large language models?
LLMs are AI systems designed to understand and generate language in a way that mimics human communication and reasoning. They are trained on vast datasets containing text from books, websites, code repositories, and other digital content.
By learning statistical patterns in language, LLMs can generate coherent and contextually relevant text based on a given input. For example, models like GPT are trained on a huge swath of internet text and can produce writing that mirrors human style across many topics.
These models typically rely on the transformer architecture, which uses mechanisms like self-attention to consider the context of words in a sequence, allowing the model to weigh the importance of different parts of the input text relative to each other, enabling a better understanding of context and meaning.
For instance, Google’s BERT model reads text bidirectionally – both left-to-right and right-to-left – to capture context, a significant advancement over older one-directional models, making BERT especially effective for tasks requiring deep language understanding, like question answering or sentiment analysis.
As LLMs have grown, they’ve gotten better at fluent text generation and shown emergent reasoning abilities. Newer generative models such as GPT-4o-mini and DeepSeek R1 can perform complex tasks like solving multi-step math problems or writing code by reasoning through steps, especially when guided by techniques like chain-of-thought prompting.
Given the right prompts, these models can simulate a step-by-step reasoning process, allowing them to handle more complex queries. The emergence of reasoning in LLMs is partly a byproduct of scale, as larger models trained on more data tend to develop more advanced capabilities, and partly due to specialized training or fine-tuning on data that encourages logical reasoning.
Models like Anthropic’s Claude have also been trained with specific methods, like Constitutional AI, to better follow instructions and reason safely. All of these advances, however, come with increased training requirements. Next, we’ll discuss the cost of training a large language model.
Cost of training LLMs with cloud infrastructure
As AI development increasingly shifts to cloud platforms, driven partly by limited availability of GPUs, cloud services have become one of the most practical and scalable ways to train LLMs. The cloud offers on-demand access to large numbers of GPUs/TPUs and the ability to distribute training across multiple machines.
Such scalability is excellent for the fluctuating demands of AI training cycles. Major providers have built massive supercomputers in the cloud to facilitate LLM training. Microsoft, for example, constructed an Azure supercomputer with over 10,000 GPUs and ultra-fast networking specifically for OpenAI’s model training.
However, renting such infrastructure comes at a significant cost. A recent example from NVIDIA CEO Jensen Huang illustrates the scale of resources required, stating that training the GPT-MoE-1.8T model using 25,000 Ampere-based GPUs (most likely the A100) took 3 to 5 months. Doing the same with H100 would take about 8,000 GPUs in 90 days.
The above statement shows how each generation of hardware can improve training efficiency. The H100s offer substantially higher throughput than A100s, reducing the time and number of machines needed for the same task.
Still, whether using 25,000 older GPUs or 8,000 newer ones, the compute cluster required is enormous, and most organizations simply cannot afford to assemble or rent such resources for training from scratch.
While it is possible to train a model from scratch, most users won’t train giant LLMs from scratch due to these high costs and infrastructure hurdles. Instead, they’ll use pre-trained models provided by AI labs or open-source communities and then adapt them to their needs. This avoids spending millions of dollars in compute for initial training.
Generally, if a company or researcher needs an LLM, there are two approaches:
- Hosting your own model: Obtain a pre-trained model checkpoint, either open-source or via license, and run further training or fine-tuning on it using cloud servers that you rent or own.
- Pay-per-token access: Use a hosted model provided through an API, like OpenAI’s or Google’s, and pay for usage, rather than handling any training yourself.
Let’s examine each of these approaches and their cost implications.
Read more: How to build an AI
Hosting models in the cloud
If you choose to host and train/fine-tune models in the cloud, you might need to rent compute resources. Companies like CUDO Compute offer suites of services that support the entire machine learning lifecycle from data storage to GPU compute to deployment.
The advantage of cloud-based training is convenience and scalability, as you can spin up hundreds of GPUs for a few days of training and then shut them down, only paying for what you used. You also don’t have to maintain physical hardware.
When training large models with tens or hundreds of billions of parameters, such as GPT-3 or Meta’s Falcon 180B, the expense goes beyond just the headline price of GPUs. In a cloud environment, you also need to account for supporting resources and overheads:
- Virtual CPUs (vCPUs) to coordinate and feed data to the GPUs during training.
- Memory (RAM) for holding training data batches, model activations, and other intermediate computations.
- Storage for datasets and for saving model checkpoints (which themselves can be hundreds of gigabytes in size for big models), as well as costs for data transfer.
Each of these components adds to the bill. Cloud providers typically charge based on the compute time for both GPU and CPU, the amount of memory provisioned, and the volume of data stored or transferred. This means training a large AI model can incur costs on multiple fronts.
Efficiently using and managing all these resources helps to keep the budget under control. For example, ensuring GPUs are kept busy so you’re not paying for idle time, and not provisioning more CPU or memory than needed.
Let’s break down how this might work when training an LLM on a large model on CUDO Compute:
At the time of writing, the cost of the A100 on CUDO Compute starts from $1.50 per hour. There is also a monthly commitment option of $1,125.95. When factoring in the other costs, such as vCPUs and memory needed, each is charged based on location.
Using the median location from the roster, we will base our analysis on the pricing from the Los Angeles 1 location. Here is how much it costs for each resource needed:

Multiple GPUs are advised for optimal results. This would be the recommended amount needed to train a Falcon 180B on CUDO Compute based on the default instance for training the same model on AWS:
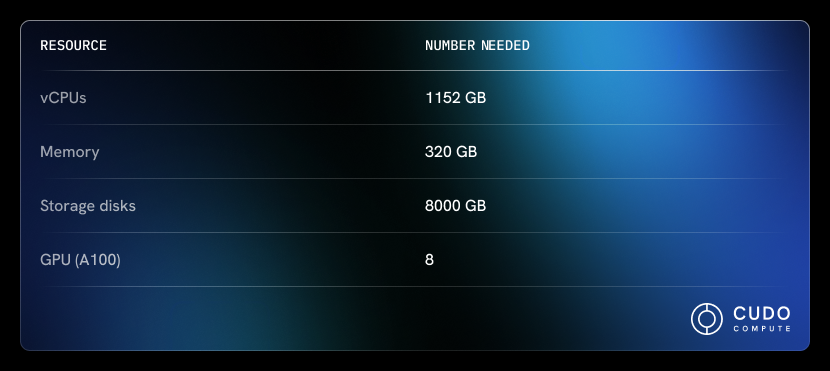
The above configuration is very similar to the default configuration used on AWS for training LLMs on the same model. To use this configuration on CUDO Compute, assuming the model is not scaled up or down, and no discounts are applied, it will total just over USD 13,000 monthly. Here is the breakdown:
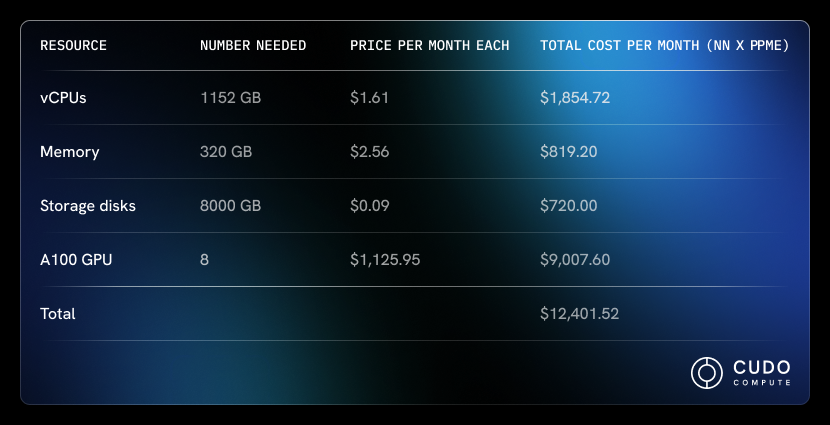
Since training an LLM from scratch will likely take months, this cost will pile up over time, particularly when training involves multiple iterations over extensive datasets.
Also, as CUDO Compute is one of the cheapest cloud platforms available, bear in mind that the compute costs may be higher on other platforms. For example, using an instance with a similar configuration on AWS (ml.p4de.24xlarge) will cost over USD 23,000 per month.
It’s worth noting that newer GPU hardware can change this calculus. The above costs were with NVIDIA’s A100 GPUs. The H100 GPUs offer about 2–3 times the performance of A100 for training workloads, and the B100 is even more improved than the H100. You could use fewer B100s to train in less time, potentially lowering the total cost, but B100s are also more expensive per hour than A100s and H100s.
Hosting and training large models in the cloud gives flexibility but requires careful resource planning. You will often fine-tune an existing model for a specific task (which is far cheaper) rather than train a new LLM from scratch. Next, we’ll look at an alternative to any training, using a pay-per-token model to use models others have already trained.
Pay-per-token access to LLMs
The high cost of training and maintaining LLMs has led to the rise of the pay-per-token (PPT) model for accessing these powerful language models. Here's how it works:
Companies like OpenAI and Google AI pre-train massive LLMs on vast datasets and allow developers and businesses to use these models, such as GPT-3 or similar, without the prohibitive costs and technical challenges of training such models themselves.
Users don't incur the upfront costs of training and infrastructure. Instead, they pay a fee based on the number of tokens (roughly equivalent to words or sub-words) processed by the LLM when completing tasks like text generation, translation, or code writing.
The PPT model offers a significantly more cost-effective approach than in-house training for tasks that don't require extensive LLM usage. Users only pay for the resources they actually use.
Benefits of pay per token:
- Reduced costs: This model eliminates the upfront investment in hardware, software, and training data.
- Scalability: Users can easily scale their LLM usage up or down based on their needs, paying only for the tokens they consume.
- Accessibility: PPT allows a wider range of users and smaller companies to access LLMs without the prohibitive costs of in-house training.
Why is it so expensive to train LLMs?
There are several reasons why training large language models is extraordinarily expensive:
- Massive model sizes and data: Modern LLMs are huge. While GPT-3 had 175 billion parameters, newer models like GPT-4 are rumored to have on the order of 1 trillion parameters. The amount of computation (floating point operations) needed to train a model scales roughly linearly with the number of parameters multiplied by the number of training examples (tokens).
To achieve high performance, these models are trained on extremely large datasets with hundreds of billions or even trillions of tokens of text. For example, an LLM might be trained on 300-500 billion tokens of data, iterating through that corpus multiple times.
The combination of a gigantic model and a gigantic dataset leads to an eye-popping number of total compute operations.
It is estimated that GPT-4’s training consumed 2.1 × 1025 FLOPs (21 billion petaFLOPs), and models like Gemini Ultra might be around 5.0 × 1025FLOPs, driving those compute bills. Simply put, scale is costly. Even with highly efficient software and hardware, you’re pushing an unfathomable amount of data through the model.
- Expensive hardware requirements: To handle that scale of computation within a reasonable timeframe, you need fleets of high-end accelerators (GPUs or TPUs). Training runs often use thousands of GPUs working in parallel for weeks or months.
Owning such hardware is capital-intensive, as one NVIDIA H100 GPU can cost $25k–$40k; a pod of 1000 of them would be $25–40 million in hardware alone, and renting them is expensive too, as we discussed earlier.
Additionally, the electricity and cooling for running these at full tilt 24/7 are very costly. Large training runs can consume megawatt-hours of energy, and only a few companies have the infrastructure to dedicate 10,000 GPUs to a single task.
Supporting hardware like high-speed networking, like InfiniBand or custom interconnects, is also needed to ensure those GPUs can communicate rapidly as they split up the training load. All of this specialized infrastructure drives up the cost significantly.
- Extended training durations: Despite massive parallelism, training a reasoning model can still take weeks or months. During that entire period, the hardware must be powered and utilized.
For instance, if you run 1,000 GPUs for one month, that’s 1,000 GPU-months of usage, which, at say $2,000 per GPU-month, would be $2 million. Now, consider some runs use 5,000 or 10,000 GPUs for several months. It’s easy to see how the cost racks up to tens of millions of dollars. Every additional epoch of training to slightly improve the model’s performance comes with that price tag.
Moreover, training often isn’t a one-shot process; researchers may do multiple runs while tuning hyperparameters or testing different configurations. The final model you see is the product of many trial runs and experiments behind the scenes. Those experimental runs also consume a lot of compute.
According to recent analysis, the total compute used in developing a new model could be 2–3 times the compute of the final training run, once you account for all the failed or exploratory experiments along the way.
- Advanced techniques and multiple phases: Training a competitive LLM now involves more than just one pass through a dataset. For example, after the initial pre-training where you predict the next word on huge text data, many models undergo fine-tuning phases, such as Reinforcement Learning from Human Feedback (RLHF), to align the model with human preferences and instructions.
RLHF involves training additional models (reward models) and running reinforcement learning algorithms that themselves require lots of computations on GPUs and custom data generated by human annotators, which is expensive.
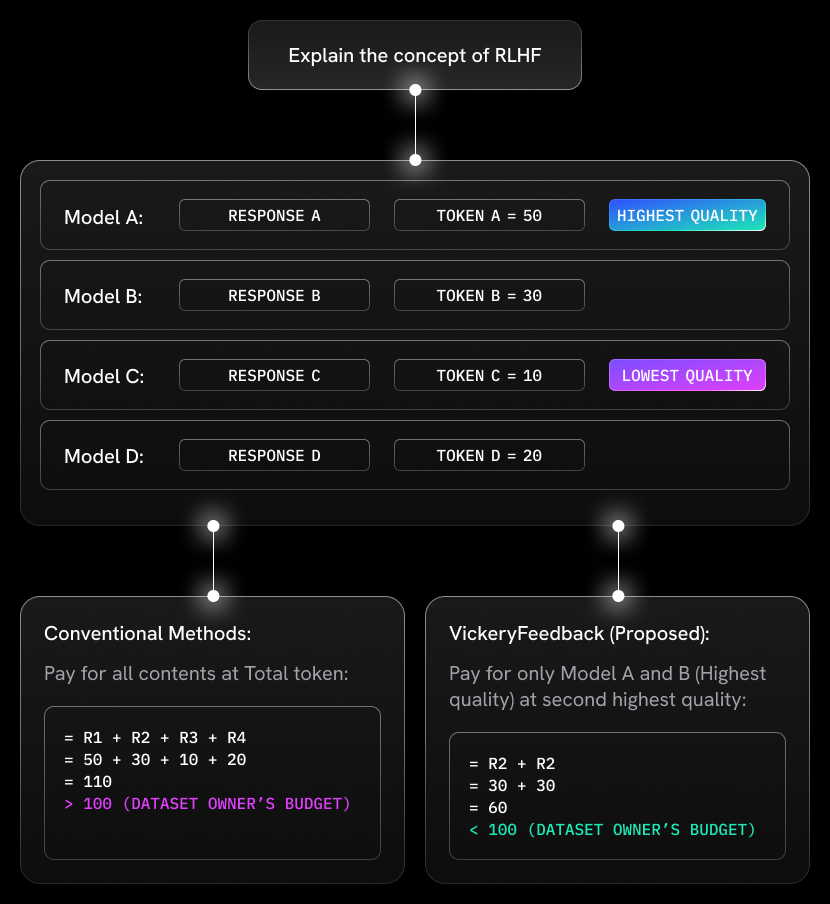
Illustration of Vickrey Feedback for RLHF. Source: Paper.
OpenAI’s ChatGPT/GPT-4 alignment process, for instance, meant hiring human contractors to produce conversations and feedback, and then performing iterative fine-tuning, improving the model’s usefulness and safety, but it adds to the total cost of development, both in terms of money and time, beyond the baseline pre-training.
Similarly, to imbue reasoning abilities, researchers might fine-tune LLMs on complex problem-solving datasets or use techniques like chain-of-thought prompting and self-correction, which can require generating and filtering a lot of model outputs, again consuming compute.
Each additional training objective or stage, be it tutoring the model on logic puzzles or making it follow a constitution of AI principles, introduces extra expense.
- Data acquisition and preparation: Often overlooked in pure compute discussions is the cost of the data itself. High-quality datasets may need to be purchased or scraped and cleaned at scale. For example, an LLM might ingest the entire Wikipedia, huge swaths of web text, news, books, academic papers, code repositories, etc. Web crawling and data storage incur infrastructure costs.
Additionally, if a model is to excel at, say, coding or medical questions, one might need to curate domain-specific data, which could be behind paywalls or require licensing. Companies might pay for access to archives of journals or specific private datasets.
Then comes the preprocessing: filtering out problematic content, deduplicating text, formatting it for training, and so forth. This can involve substantial engineering effort and cloud processing power.
Preparing a trillion-token corpus that is diverse, high-quality, and legally usable is a non-trivial expense, sometimes involving human annotators for labeling or verification in the loop.
Pushing the limits of dataset size, model size, and compute scale is expensive because it sits at the edge of what’s technologically possible. To do so requires cutting-edge hardware, huge energy consumption, and often a team of researchers and engineers whose salaries are another factor.
The result is that only a handful of companies and well-funded academic labs can afford to train the largest models. Others must be clever in using those models or finding ways to achieve results with smaller-scale systems.
In the following section, we’ll discuss strategies for controlling and reducing the cost of training.
Steps to controlling the cost of training LLMs
While training large models will likely remain resource-intensive, there are several strategies that can optimize resource utilization and reduce expenses. In fact, for most organizations, the question isn’t “Can we train our own GPT-4?” but “How can we achieve our AI goals within a reasonable budget?”.
Below are key approaches to managing and minimizing the costs of training and deploying LLMs:
1. Implement model and training optimization techniques: Optimize what you build and how you build it so you need less compute for the same result.
- Model architecture selection and sizing: Carefully choose a model architecture and size that balances performance with cost. Bigger is not always better for a given task. If you can achieve your target accuracy with a 6-billion-parameter model, there’s no need to train a 60-billion-parameter one.
Techniques like model pruning (removing unnecessary weights) or quantization can reduce the effective size and computation of a model without a significant loss in accuracy. Using newer architecture improvements can also get more bang for the buck, as some architectures are more parameter-efficient than others.
The goal is to avoid overspending on compute capacity you don’t actually need. In some cases, multiple smaller specialized models ensemble might be better than one large model.
- Training data optimization: Ensure your training data is high-quality and relevant. A smaller, curated dataset can sometimes outperform a larger, noisy one. Removing redundant or low-value data can shorten training time.
For instance, if you’re building a biomedical language model, 100GB of well-chosen medical text will train faster and yield a more accurate model in that domain than 1TB of random internet text.
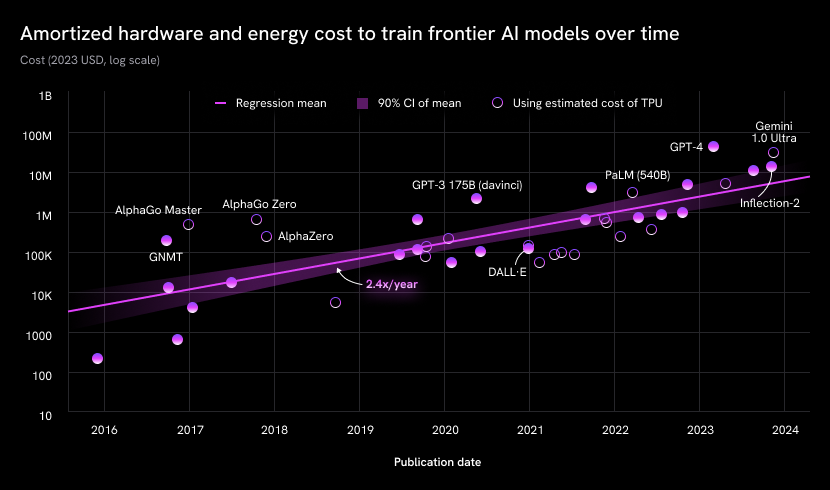
Amortized hardware cost plus energy cost for the final training run of frontier models. Source: Paper
Use data filtering to eliminate spam, duplicated content, or irrelevant information, and augmentation to add useful diversity are important steps. Every epoch on unnecessary data is wasted GPU time, so focus on quality over sheer quantity when possible.
- Knowledge distillation: This technique involves training a smaller “student” model to replicate the behavior of a larger “teacher” model. You first train a large model (or take an existing one), then use its outputs to guide the training of a compact model.
The student model can often achieve near the teacher’s performance but with far fewer parameters, effectively compressing the knowledge of a huge model into a cheaper, faster model that is much easier to deploy and even continue training.
Distillation was used, for example, to create smaller BERT variants and even some DeepSeek distillations, cutting down model size by 10 times or more while retaining most capabilities. For organizations, one strategy is to fine-tune a large model on your task (possibly using an API or a short-term rental on a big GPU machine), then distill it into a smaller model you can afford to train further or run in production.
- Mixed-precision training: Modern hardware and software allow using lower numerical precision for calculations to speed up training. Instead of 32-bit floating point for everything, frameworks use 16-bit or even 8-bit in certain parts of the computation.
This cuts memory usage and can double the training speed on supported hardware without noticeably affecting model accuracy due to techniques like loss scaling to maintain numerical stability.
The latest NVIDIA GPUs and Google TPUs all support mixed precision. You can significantly reduce the compute time and cost required for each training step using mixed-precision training. It’s a free efficiency gain and has become standard practice in training large models.
- Parameter-efficient fine-tuning: A recent development, particularly useful if you’re working with pre-trained models, is to fine-tune only a subset of the model’s parameters or use add-on adapters, instead of complete end-to-end training.
Approaches such as low-rank adaptation (LoRA) and other adapter-based methods allow you to train just a small additional set of weights or a low-rank update to the original weights that can be merged with the model for new tasks, drastically reducing the compute and data needed to adapt a model to a domain.
For example, LoRA was used to fine-tune large models like GPT-3 on specific tasks using 10x–100x less compute than tuning the entire model. By training fewer parameters, you use less GPU memory and can get away with shorter training times, all while achieving nearly the same performance as full fine-tuning.
Parameter-efficient fine-tuning uses the investment already made in a pre-trained model and avoids having to reinvent the wheel. In general, always prefer fine-tuning or adapting an existing model over training from scratch when possible; it’s very much like transfer learning that can cut requirements by orders of magnitude.
2. Optimize training configurations: Train smarter, not harder – improve your training process to converge faster or use fewer resources.
- Hyperparameter tuning and efficient experimentation: The choice of hyperparameters can dramatically affect how fast a model learns. A well-tuned training run might reach a target accuracy in 50% fewer steps than a poorly tuned one, which directly translates to 50% less cost.
Rather than guessing, use systematic approaches to hyperparameter search (grid search, Bayesian optimization, etc.) on smaller-scale models or subsets of data to find good settings, then scale up.
Also, monitor training in real-time. If loss has plateaued early or something looks off, intervene or stop rather than let a bad configuration run to completion. Implement an early stopping strategy so that if your model’s performance on a validation set stops improving, it halts the training to avoid wasting epochs that don’t yield gains.
Read more: How to build an AI
- Checkpointing and fault tolerance: Training runs can be long, and failures like machine crashes and spot instance termination can happen. By checkpointing regularly (saving the model state every so often), you can resume from the last checkpoint instead of starting over, thereby saving all the progress made until the interruption. This is more about avoiding unnecessary re-training costs rather than reducing the cost of the successful run, but it’s important.
- Smaller-scale and iterative training: Often, one can pre-train on a smaller scale first to get a sense of things. For example, train a smaller model (say 10% of the full size) on the full data, or the full model on 10% of the data, to identify issues or get learning curve estimates. This “pilot run” approach can reveal if your learning rate is way off, or if the model is too small to ever reach your target, etc., without spending the full budget.
You can also try using learning rate warmups*,* cosine decays, and other training schedule tricks, which can also help stabilize the training of large models, avoiding divergence that would force you to restart with different settings, which is another hidden cost.
4. Use advanced model strategies:
Use model designs that reduce per-model compute and external resources that make the job easier.
- Mixture-of-experts (MoE) models: MoE is an architecture that effectively has multiple sub-models called experts and a gating mechanism that activates only some of them for each input, meaning that at any given time, only a portion of the model’s parameters are used, rather than all of them.
MoEs can significantly cut down the compute needed for a given parameter count – for instance, Google’s Switch Transformer (an MoE model) achieved comparable results to a dense model but with far less computation by sparsely activating experts.
In a research, they got a model with 1.6 trillion parameters to train with the computational cost of only a 100+ billion parameter dense model. The benefit is that you get the effect of a huge model (in terms of capacity and specialization) without having to pay the full cost every time.
MoEs spread out the workload and can be more efficient if implemented well. However, they add complexity; not all frameworks easily support them, and they can be tricky to get right. But as research advances, MoEs are becoming more common in large-scale settings.
For cost-savvy training, exploring MoE architectures could allow training frontier-sized models on a smaller budget by reducing the computational load per token.
- Retrieval and external knowledge integration: Another way to reduce the burden on the model itself is to give it tools or access to information during training/inference. For example, Retrieval-Augmented Generation (RAG) techniques provide the model with relevant documents fetched from an external database, so the model doesn’t need to memorize every fact; instead, it can look things up.
DeepMind’s RETRO model demonstrated that a model with retrieval support could match the performance of a model 25 times larger that had everything baked into its parameters. By integrating a massive external knowledge base, they maintained performance with a much smaller network, which implies huge training cost savings of 25 times fewer parameters to train is roughly 25 times less compute.
This approach can be thought of as augmenting the model with a form of memory or tools so it doesn’t have to do all the work internally. Likewise, allowing a model to use a calculator for arithmetic or call an API for current knowledge means you don’t have to train it to death trying to internalize those capabilities.
In a practical sense, building a system that combines an LLM with retrieval (e.g., queries to Wikipedia or a company knowledge base) can let you use a smaller base model to achieve the same or better performance than an extremely large model without retrieval, cutting down training requirements.
Many current applications, like search engine bots, use this strategy. So, from a cost perspective, invest in a slightly more complex system (model + retrieval tool) and you might avoid having to invest in a model that’s 10 times bigger and 10 times more expensive to train.
- Multi-step reasoning and curriculum learning: If you want an LLM with strong reasoning, an efficient approach is to train it to encourage reasoning via multiple steps, rather than expecting the model to solve everything in one go with brute-force parameters.
For example, techniques like chain-of-thought training involve showing the model intermediate reasoning steps for problems (like math solutions or code logic) during training. This can teach a smaller model to approach complex tasks systematically, narrowing the gap with a larger model that might implicitly learn those skills.
It’s not a direct cost-saving in compute, but it can mean you reach the desired capability without an exponential increase in model size. Similarly, curriculum learning (starting with easier tasks and then increasing difficulty) can help a model learn faster and converge better, meaning fewer epochs (less cost) to achieve high performance.
The overarching idea is training smarter. Guiding the model’s learning process can trim the needed compute compared to naive training on a jumble of tasks. This is especially useful for reasoning-centric models where the objective is not just fluent text, but correct and logical solutions.
5. Collaborate and use open-source ecosystems:
Don’t go at it alone; take advantage of community efforts, existing models, and shared resources.
- Use pre-trained models and tools: Using open-source pre-trained models significantly reduces costs by eliminating the need for full-scale training from scratch. Models such as Meta’s LLaMA 2, BLOOM, and DeepSeek R1 are available with pre-trained weights, enabling companies and researchers to fine-tune these models for their specific needs at a fraction of the original training cost.
As we showed earlier, fine-tuning a large model like LLaMA 2 (70B parameters) typically costs tens of thousands of dollars, substantially less than full-scale initial training.
Additionally, the open-source ecosystem provides robust tools and libraries optimized for efficient distributed training. Frameworks such as DeepSpeed and Fully Sharded Data Parallel (FSDP) effectively manage large models across limited hardware by sharding model components, allowing greater efficiency and reduced hardware requirements.
Hugging Face’s Accelerate and tools like Horovod further streamline distributed training processes. You can benefit from shared knowledge, compute resources, and reduced overall costs by tapping into community-developed resources and collaborating within research communities, like EleutherAI, LAION, and BigScience.
By applying these strategies, you’ll be able to cut down the cost required to train or fine-tune LLMs. Some emerging efforts have shown it’s possible to reach GPT-3/4 level performance on much smaller budgets.
For example, the founder of 01.ai claimed they trained a GPT-4-comparable model using only 2,000 GPUs and about $3 million of compute by optimizing every aspect of the process, which is a stark contrast to the amount reportedly spent on GPT-4 by OpenAI. While such claims have yet to be fully verified, they underscore that efficiency matters. The gap between big-budget labs and smaller players can be narrowed with clever engineering.
Controlling the cost of training LLMs is about making prudent choices at each step, from choosing the right model size, hardware, data, and tools. Those who do so can build impressive language and reasoning models without breaking the bank.
The landscape of LLM development is evolving quickly. While the cutting-edge models will always push expensive extremes, the practical know-how for cost-effective training is more available than ever. If you need to learn how, read our guide on how to build an AI from scratch to learn more.
With careful planning, training your LLM or tailoring an existing one to your needs is feasible within a reasonable budget, and CUDO Compute can help you achieve that easily. We offer cost-effective GPUs on demand and scalable GPU clusters equipped with the latest NVIDIA GPUs. You can get started with a few clicks. Get started.
