 Resources
Resources 
Scaling generative AI models to billions or trillions of parameters requires specialized hardware beyond the capabilities of traditional CPUs.While Graphics Processing Units (GPUs) remain the dominant solution for AI acceleration, a new contender has emerged: the Language Processing Unit (LPU).
GPUs such as NVIDIA’s AI-optimized Hopper series are renowned for their parallel processing capabilities, while LPUs, such as those developed by Groq, are architected to address the sequential nature of natural language processing (NLP) tasks, a fundamental component of building AI applications.
In this post, we’ll consider the key differences between GPUs and LPUs for deep learning workloads, examining their architectures, strengths, and performances.

Let’s begin with an overview of the GPU architecture.
Architecture of a GPU
We have previously discussed the architecture of specific GPUs like the NVIDIA series, this will be a more general overview of what makes up a GPU.
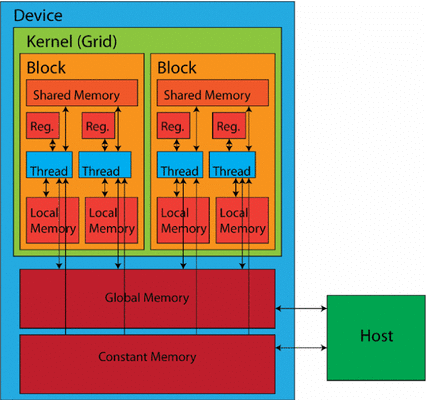
At the core of GPUs are compute units (also known as execution units), which contain several processing units (referred to as stream processors or CUDA cores in NVIDIA terminology), along with shared memory and control logic. In some architectures, particularly those designed for graphics rendering, additional components such as Raster Engines and Texture Processing Clusters (TPCs) may also be present.
A compute unit consists of multiple smaller processing units and can manage and execute many threads simultaneously. It includes its own registers, shared memory, and scheduling units. Each compute unit operates multiple processing units in parallel, coordinating their work to handle complex tasks efficiently, with each processing unit carrying out individual instructions for basic arithmetic and logical operations.
 Source: Research Paper
Source: Research Paper
Processing Units and Instruction Set Architecture (ISA)
Each processing unit within a compute unit is designed to execute a specific set of instructions defined by the GPU's Instruction Set Architecture (ISA). The ISA determines the types of operations (arithmetic, logical, etc.) that a processing unit can perform and the format and encoding of these instructions.
The ISA is the interface between the software (e.g., CUDA or OpenCL code) and the hardware (processing units). When a program is compiled or interpreted for a GPU, it is translated into a series of instructions that conform to the GPU's specific ISA. The processing units then execute these instructions, ultimately performing the desired computations.
Different GPU architectures may have different ISAs, impacting their performance and capabilities for specific workloads. Some GPUs offer specialized ISAs for specific tasks, such as graphics rendering or machine learning, to optimize performance for those use cases.
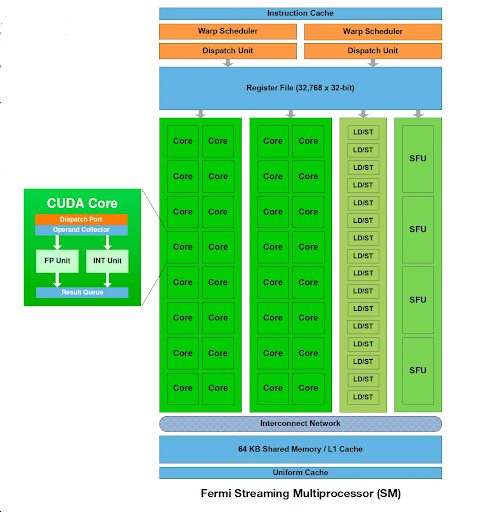
While processing units handle general-purpose computations, many GPUs incorporate specialized units to accelerate specific workloads further. For instance, Double-Precision Units (DPUs) handle high-precision floating-point calculations for scientific computing applications. At the same time, Tensor Cores (NVIDIA) or Matrix Cores (AMD) specifically designed for accelerated matrix multiplications are now components of the compute units.
GPUs use a multi-tiered memory hierarchy to balance speed and capacity. Closest to the processing core are small on-chip registers for temporarily storing frequently accessed data and instructions. This register file offers the fastest access times but has limited capacity.
Next in the hierarchy is Shared Memory, a fast, low-latency memory space that can be shared among processing units within a compute unit cluster. Shared Memory facilitates data exchange during computations, improving performance for tasks that benefit from data reuse within a thread block.
Global Memory serves as the main memory pool for larger datasets and program instructions that cannot fit in the on-chip memories. Global Memory offers a much larger capacity than registers or shared memory but with slower access times.
 Source: Gao, Medium
Source: Gao, Medium
Communication Networks within GPUs
Efficient communication between processing units, memory, and other components is critical for optimal GPU performance. To achieve this, GPUs utilize various interconnect technologies and topologies.
Here is a breakdown and how they work:
High-bandwidth Interconnects:
- Bus-based Interconnects: A common approach used in many GPUs, bus-based interconnects provide a shared pathway for data transfer between components. While simpler to implement, they can become a bottleneck under heavy traffic as multiple components compete for access to the bus.
- Network-on-Chip (NoC) Interconnects: Some high-performance GPUs employ NoC interconnects, which offer a more scalable and flexible solution. NoC consists of multiple interconnected routers that route data packets between different components, providing higher bandwidth and lower latency than traditional bus-based systems.
- Point-to-Point (P2P) Interconnects: P2P interconnects enable direct communication between specific components, such as a processing unit and a memory bank. P2P links can significantly reduce latency for critical data exchanges by eliminating the need to share a common bus.
Interconnect Topologies:
- Crossbar Switch: This topology allows any compute unit to communicate with any memory module. It offers flexibility but can become a bottleneck when multiple compute units need to access the same memory module simultaneously.
- Mesh Network: In Mesh Network topology, each compute unit is connected to its neighbors in a grid-like structure. This reduces contention and allows for more efficient data transfer, especially for localized communication patterns.
- Ring Bus: Here, compute units and memory modules are connected circularly. This allows data to flow in one direction, reducing contention compared to a bus. While not as efficient for broadcasting as other topologies, it can still benefit certain communication patterns.
In addition to on-chip interconnects, GPUs must also communicate with the host system (CPU and main memory). This is typically done through a PCI Express (PCIe) bus, a high-speed interface that allows for data transfer between the GPU and the rest of the system.
By combining different interconnect technologies and topologies, GPUs can optimize data flow and communication between various components, achieving high performance across various workloads.
To maximize utilization of its processing resources, the GPU uses two key techniques: multi-threading and pipelining. GPUs typically employ Simultaneous Multi-Threading (SMT), allowing a single compute unit to execute multiple threads from the same or different programs concurrently, enabling better resource use, even when tasks have some inherent serial aspects.
GPUs support two forms of parallelism: thread-level parallelism (TLP) and data-level parallelism (DLP). TLP involves executing multiple threads concurrently, usually implemented using a Single Instruction, Multiple Threads (SIMT) model. DLP, on the other hand, processes multiple data elements within a single thread using vector instructions.
Pipelining further enhances efficiency by breaking down complex tasks into smaller stages. These stages can then be processed concurrently on different processing units within a compute unit, reducing overall latency. GPUs often employ a deeply pipelined architecture, where instructions are broken down into many small stages. Pipelining is implemented not only within the processing units themselves but also in memory access and interconnects.
The combination of numerous streaming processors, specialized units for specific workloads, a multi-tiered memory hierarchy, and efficient interconnects allows GPUs to handle massive amounts of data concurrently.
To use the latest NVIDIA GPUs for your AI and HPC projects, contact us at CUDO Compute. We have the NVIDIA H100 and other GPUs on reserve and demand. Reach out to get started now!
Architecture of an LPU
LPUs are newer to the market and are lesser known at the moment, but as Groq has shown, they can be very powerful. LPUs are built to address the unique computational demands of Natural Language Processing (NLP) workloads.
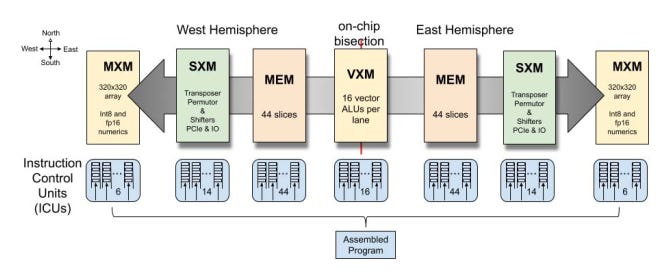
We will focus our discussion on Groq’s LPU. The Groq LPU contains a Tensor Streaming Processor (TSP) architecture. This design is optimized for sequential processing, which aligns perfectly with the nature of NLP workloads. Unlike GPU architectures that may struggle with the irregular memory access patterns of NLP tasks, the TSP excels at handling the sequential flow of data, enabling faster and more efficient processing of language models.
 Source: Underlying Architecture of Groq's LPU
Source: Underlying Architecture of Groq's LPU
The LPU's architecture also addresses two critical bottlenecks often encountered in large-scale NLP models: computational density and memory bandwidth. By carefully managing computational resources and optimizing memory access patterns, the LPU ensures that processing power and data availability are effectively balanced, resulting in significant performance gains for NLP tasks.
The LPU particularly shines in inference tasks, where pre-trained language models are used to analyze and generate text. Its efficient data handling mechanisms and low-latency design make it ideal for real-time applications like chatbots, virtual assistants, and language translation services. The LPU incorporates specialized hardware to accelerate critical operations like attention mechanisms, essential for understanding context and relationships within text data.
Software Stack:
To bridge the gap between the LPU's specialized hardware and NLP software, Groq provides a comprehensive software stack. A dedicated compiler optimizes and translates NLP models and code to run efficiently on the LPU architecture. This compiler supports popular NLP frameworks like TensorFlow and PyTorch, enabling developers to leverage their existing workflows and expertise without major modifications.
The LPU's runtime environment manages memory allocation, thread scheduling, and resource utilization during execution. It also provides application programming interfaces (APIs) for developers to interact with the LPU hardware, facilitating customization and integration into various NLP applications.
Memory Hierarchy:
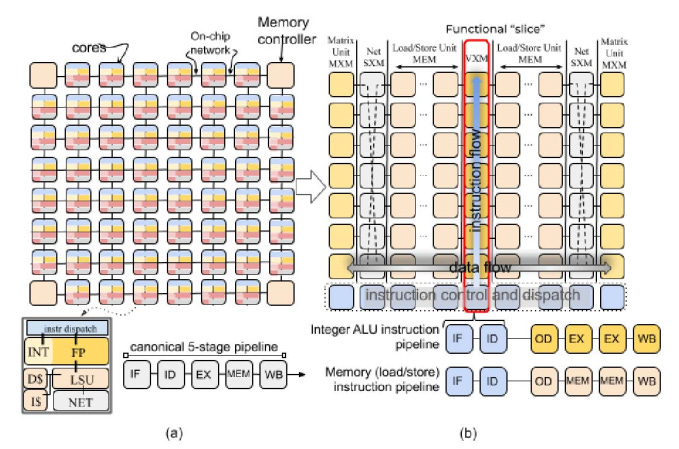
Efficient memory management is crucial for high-performance NLP processing. The Groq LPU employs a multi-tiered memory hierarchy to ensure data is readily available at various stages of computation. Closest to the processing units are scalar and vector registers, providing fast, on-chip storage for frequently accessed data like intermediate results and model parameters.
The LPU uses a larger and slower Level 2 (L2) cache for less frequently accessed data. This cache is an intermediary between the registers and the main memory, reducing the need to fetch data from the slower main memory.
 Source: Underlying Architecture of Groq's LPU
Source: Underlying Architecture of Groq's LPU
The primary storage for bulk data is the main memory, which stores pre-trained models and input and output data. Within the main memory, dedicated model storage is allocated to ensure efficient access to the parameters of pre-trained models, which can be very large.
Furthermore, the LPU incorporates high-bandwidth on-chip SRAM, reducing the reliance on slower external memory and thus minimizing latency and maximizing throughput. This is particularly beneficial for tasks that involve processing large volumes of data, such as language modeling.
Interconnect Technologies:
The Groq LPU uses interconnect technologies to facilitate efficient communication between processing units and memory. Bus-based interconnects handle general communication tasks, while Network-on-Chip (NoC) interconnects provide high-bandwidth, low-latency communication for more demanding data exchanges. Point-to-Point (P2P) interconnects enable direct communication between specific units, further reducing latency for critical data transfers.
Performance Optimization:
To maximize the utilization of processing resources, the LPU employs multi-threading and pipelining techniques. Neural Network Processing Clusters (NNPCs) group processing units, memory, and interconnects specifically designed for NLP workloads. Each NNPC can execute multiple threads concurrently, significantly improving throughput and enabling thread- and data-level parallelism.
Pipelining further enhances efficiency by breaking down complex tasks into smaller stages, allowing different processing units to work on different stages simultaneously. This reduces overall latency and ensures a continuous flow of data through the LPU.
Here is a performance head-head with both hardware.
Performance Comparison
LPUs and GPUs have distinct use cases and applications, reflecting their specialized architectures and capabilities. Groq’s LPUs are designed as inference engines for NLP algorithms, so it is hard to truly compare these chips side-by-side on the same benchmarks.
Groq’s LPUs are capable of accelerating the inference process for AI models faster than any GPU currently on the market and can generate up to five hundred inference tokens per second, which would translate to writing a novel in mere minutes.
| Feature | GPU | LPU |
|---|---|---|
| Architecture | Massively parallel: Numerous smaller cores optimized for concurrent execution of many simple tasks. | Sequential: Fewer, larger cores designed for deterministic, step-by-step processing of complex tasks. |
| Ideal Workloads | High parallel processing power: Excels at tasks like image/video processing, scientific simulations, and diverse AI workloads. | Efficient sequential processing: Optimized for natural language processing (NLP) tasks, language models, and inference. |
| Strengths | Mature ecosystem: Extensive software support, libraries, and frameworks. Versatile for a wide range of applications beyond AI. | Specialized for NLP: Tailored architecture for NLP tasks, resulting in higher efficiency and lower latency for specific workloads. |
| Weaknesses | Less efficient for irregular workloads: Can struggle with tasks that don't fit the SIMD model well. High power consumption. | Less mature ecosystem: Fewer software libraries and frameworks specifically optimized for LPUs. Less versatile for non-NLP tasks. |
| Memory | Multi-tiered hierarchy: Registers, shared memory, global memory, and dedicated caches for faster access to frequently used data. | Similar hierarchy: Registers, L2 cache, main memory, and dedicated model storage for efficient access to large model parameters. |
| Interconnects | High-bandwidth interconnects: Bus-based, Network-on-Chip (NoC), and Point-to-Point (P2P) for efficient data transfer between components. | Bus-based, NoC, and P2P: Similar to GPUs, but potentially with less emphasis on extreme parallelism due to the sequential nature of NLP tasks. |
| Performance Optimization | Simultaneous Multi-Threading (SMT): Enables a single core to handle multiple threads concurrently. Pipelining: Breaks down tasks into stages for parallel execution. | Multi-threading: Supports thread-level and data-level parallelism. Pipelining: Similar to GPUs but tailored for sequential processing. |
GPUs are not designed for just inference, they can be used for the entire AI lifecycle, which includes inference, training, and deploying all types of AI models. With specialized cores for AI development – like Tensor Cores – GPUs canbe used for the training of AIs. GPUs can also be used in data analytics, image recognition, and scientific simulations.
Both can handle large datasets, but LPUs can contain more data, which speeds up the inference process. The architecture of Groq's LPU, designed with high-bandwidth, low-latency communication, and efficient data handling mechanisms, ensures that these NLP applications run smoothly and efficiently, providing a superior user experience.
General-Purpose Parallel Processing: Beyond AI, GPUs excel at accelerating various tasks involving large datasets and parallel computations, making them valuable tools in data analytics, scientific simulations, and image recognition.
Choosing the right tool for the job
GPUs are likely the better choice if your workload is heavily parallel and requires high computational throughput across various tasks. If you are working on the entire AI pipeline from development through to deployment, GPUs would be the best hardware to invest in.
However, if you're primarily focused on NLP applications, especially those involving large language models and inference tasks, the specialized architecture and optimizations of LPUs can offer significant advantages in terms of performance, efficiency, and potentially lower costs.
You can access the best GPUs at affordable rates on CUDO Compute.
