 Resources
Resources 
When organizations plan AI clusters, most of the attention — and budget — goes to GPUs. It’s easy to see why: they’re the engines that drive large-scale training. But storage, often treated as an afterthought, can quietly become the bottleneck that undermines performance, reliability, and cost efficiency.
One of the biggest culprits is checkpointing — the process of periodically saving model states during training. Checkpointing is essential for fault tolerance and recovery; however, as models and clusters scale, the storage requirements grow at a rate that often surprises many teams. A single checkpoint of a 70B-parameter model can run into hundreds of gigabytes.
Multiply that across frequent saves, long training runs, and large GPU clusters, and storage demands quickly spiral into tens of terabytes per day. On a technical level, this creates constant pressure on input and output (I/O) bandwidth, parallel filesystems, and recovery times. From a business and planning perspective, it translates into escalating costs, complex capacity planning, and hidden risks in cluster operations.
In this article, we’ll explore how checkpointing impacts storage requirements, how those requirements scale with cluster size, and what it means for both designing training workflows and making infrastructure investments.
Understanding checkpointing
Checkpointing is about resilience. During a long training run, a deep learning framework like PyTorch or TensorFlow is programmed to save the complete state of the model periodically. If a hardware failure or other interruption occurs, training can resume from the most recent checkpoint, saving potentially weeks of compute time that would be lost if training were to start from scratch.
While its primary purpose is fault tolerance, checkpointing enables several critical functions in a modern AI workflow:
- Experimentation and fine-tuning: Checkpoints serve as a saved baseline, allowing teams to launch new experiments or fine-tune a pre-trained model without having to start from a random state.
- Reproducibility: A saved checkpoint enables the reloading, analysis, or sharing of a specific model state with colleagues to reproduce results.
- Scaling resilience: As GPU clusters expand, the likelihood of a single node failure increases significantly. Frequent checkpointing becomes a non-negotiable requirement for ensuring that large-scale jobs can be completed successfully.
The practical challenge of checkpointing, however, comes from its size. To accurately plan for storage, it's important to understand that a checkpoint saves far more than just the model's weights. A typical checkpoint includes:
- Model weights: The parameters of the network itself. While this is the most obvious component, it is often not the largest.
- Optimizer state: The state of the training optimizer, which includes momentum vectors and other adaptive learning rate parameters. For common optimizers like AdamW, this state can be up to 2–3 times the size of the model weights.
- Training metadata: Other information needed to resume training precisely, such as the current epoch, learning rate schedule, and random number generator seeds. This part is typically small but essential.
The combination of model weights and optimizer states leads to a surprisingly large footprint. A useful rule of thumb for mixed-precision training (using bfloat16 or fp16 for weights and fp32 for optimizer states) is that a complete checkpoint requires approximately 8 to 12 bytes of storage per model parameter.
This relationship means that as models scale, their checkpoint sizes grow linearly, reaching massive scale:
| Model Size (Parameters) | Model Weights Size (bfloat16) | Estimated Full Checkpoint Size |
|---|---|---|
| 7 Billion | ~14 GB | ~70 GB |
| 70 Billion | ~140 GB | ~700 GB |
| 175 Billion | ~350 GB | ~1.75 TB |
Table: Estimated single checkpoint sizes based on model parameter count, assuming ~10 bytes per parameter for a full save.
With checkpoints reaching hundreds of gigabytes or even terabytes, the next critical question is how often to save them. This decision involves a direct trade-off between performance overhead and recovery cost.
- Checkpointing too frequently (e.g., every 30 minutes): This minimizes the amount of lost work in the event of a failure. However, it imposes a significant "I/O tax" on the cluster, as GPUs may sit idle while the massive checkpoint file is written to storage, reducing overall training throughput.
- Checkpointing too infrequently (e.g., every 8-12 hours): This maximizes GPU utilization during training but risks wasting a tremendous amount of expensive compute time if a failure happens just before the next scheduled save.
The optimal frequency is a balancing act determined by:
- Cluster reliability: Training on large GPU clusters, especially those with thousands of nodes, suffers from increased failure rates. For example, during OPT‑175B training on 992 A100 GPUs, over 105 restarts occurred across 60 GPU‑days, averaging a failure roughly every 14 hours. Larger jobs have shorter mean time to failure (MTTF), making frequent checkpointing essential to avoid massive compute waste.
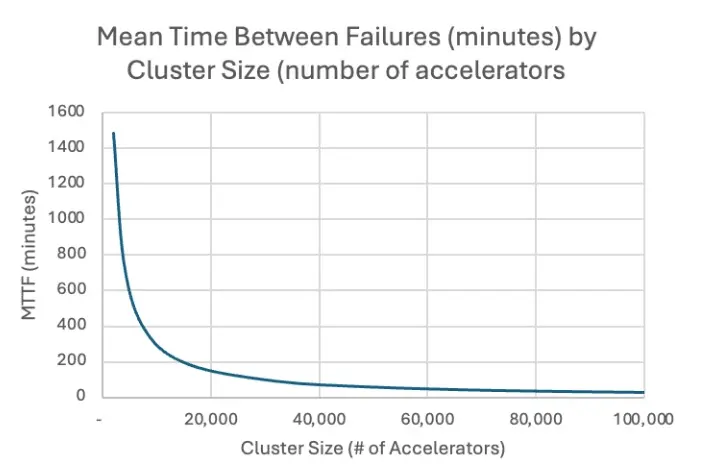 Source: MLCommons
Source: MLCommons
- Storage performance: A high-performance storage system that can absorb large, parallel writes quickly will reduce the "I/O tax," allowing for more frequent checkpoints without significantly slowing down training.
- Cost of compute: The more expensive the compute hours, the stronger the argument for checkpointing more often to avoid losing that investment. For example, consider a training job running on 512 A100 GPUs. At a conservative cloud cost of $2 per GPU-hour, a single 8-hour loss due to a failed job means wasting over $8,000 in compute. On larger clusters with thousands of GPUs, that figure can easily climb into the tens or hundreds of thousands of dollars for a single failure. Against that backdrop, the storage expense of more frequent checkpointing is often trivial compared to the potential cost of lost compute time.
Tuning the checkpoint frequency directly connects cluster reliability, storage architecture, and the economics of AI training.
How cluster size magnifies the storage problem
The previous section established that checkpoints are massive. However, their true operational impact isn't just a function of model size—it's magnified by the number of GPUs in the training cluster. As organizations scale from dozens to thousands of GPUs, the storage challenge evolves from a simple capacity issue into a critical performance bottleneck that directly impacts cost and efficiency.
The amplified cost of an I/O delay
The central problem is that the cost of the time it takes to checkpoint grows in direct proportion to the cluster size.
Imagine a 700 GB checkpoint that takes 15 minutes to write to storage.
- On a 32-GPU cluster: The cost is 15 minutes of idle time for 32 GPUs. This is an inconvenience.
- On a 512-GPU cluster: The cost is 15 minutes of idle time for 512 GPUs. This is a major financial and operational drain.
This leads to the most critical takeaway for infrastructure planning:
The duration of a checkpoint stall may be constant, but the cost of that stall is multiplied by every GPU left idle.
This stall occurs because checkpointing a distributed training job requires a "many-to-one" write operation. Hundreds or thousands of GPU processes must pause and write their state to a central storage system simultaneously, creating two primary points of failure:
- Network and filesystem congestion: On parallel filesystems (like Lustre or GPFS), this flood of simultaneous writes can saturate the network or overwhelm the metadata servers if the storage backend isn't architected for this specific high-concurrency workload.
- Insufficient ingest rate: When using object storage, the system may not offer the consistent, low-latency performance required to ingest hundreds of gigabytes in minutes, leading to prolonged checkpoint durations and idle GPUs.
While local SSDs on each node can buffer writes, they don't solve the core problem of consolidating that data onto durable, centralized storage for true fault tolerance.
Let's quantify this with a practical example that combines model size, cluster scale, and checkpoint frequency.
| Small research cluster | Large production cluster |
|---|---|
| Cluster size | 32 GPUs |
| Model | 30B Parameters |
| Checkpoint size | ~300 GB |
| Checkpoint frequency | Once every 4 hours |
| Daily storage footprint | 1.8 TB |
| The hidden cost | The occasional pause is a manageable nuisance. |
For small clusters, storage planning is a matter of capacity. For large clusters, it becomes a battle against time, where every minute of I/O delay burns thousands of dollars and undermines the entire investment in large-scale compute.
The hidden danger demonstrated here is that checkpoint overhead scales faster than many teams anticipate:
- Storage capacity requirements grow linearly with model size and checkpoint frequency.
- But the cost of lost time during checkpointing grows multiplicatively with cluster size.
This means that for small research clusters, storage may feel like a manageable nuisance. But for production-scale clusters, checkpointing can quietly consume a double-digit percentage of total training time—and cost.
Storage architectures and optimization strategies
Checkpointing at scale is as much a storage problem as it is a compute one. An effective strategy requires both the proper storage foundation and a clear-eyed approach to the trade-offs of different optimization techniques. The goal is not just to save the checkpoint, but to do so with minimal impact on GPU utilization.
How to choose the right storage
The physical storage backend is the bedrock of any checkpointing strategy. Each technology offers a different profile of performance, scalability, and cost.
| Storage Type | Strengths | Challenges | Best For |
|---|---|---|---|
| Parallel filesystems (Lustre, GPFS, etc.) | Designed for high-throughput, concurrent HPC workloads. Offers low latency and high bandwidth. | Complex to set up, tune, and manage. It can be costly at a large scale and prone to congestion if not provisioned correctly. | Environments requiring the highest and most consistent I/O performance. |
| Object Storage | Virtually unlimited capacity, durable, and highly cost-effective for large data volumes. Simple API integration. | Higher latency and variable performance. Not designed for the demands of frequent, low-latency parallel writes from an active training job. | Cost-effective long-term persistence and archival of checkpoints. |
| Local NVMe SSDs | Extremely high IOPS and bandwidth, providing the fastest possible write and read speeds. Minimizes the time GPUs are stalled. | Limited capacity and not shared. Data is lost if a node fails, making it unsuitable as a persistent, standalone solution. | The "hot tier" for capturing checkpoints instantly before they are offloaded elsewhere. |
In practice, large-scale clusters rarely choose just one. The most effective architecture is a hybrid, tiered approach that combines the strengths of each:
- Write to Local NVMe: Checkpoints are first written at maximum speed to each node's local storage, minimizing GPU idle time.
- Offload to persistent storage: In the background, a separate process copies the checkpoint from the local NVMe to a durable, centralized backend, such as a parallel file system or an object store, for long-term safety.
This hybrid model strikes a balance between speed and durability, but it requires more sophisticated workflow orchestration.
Optimization techniques
Beyond the hardware, several software-level strategies can reduce the checkpointing burden. However, each technique is a trade-off between storage size, performance, and complexity.
- Sharded checkpoints
- What it is: Instead of one massive file, the checkpoint is split into multiple "shards," with each GPU or process responsible for writing its own piece in parallel. This is a standard feature in modern distributed training frameworks, such as PyTorch fully shared data parallel (FSDP).
- The benefit: Dramatically reduces the wall-clock time required to save a checkpoint, as the I/O work is parallelized.
- The trade-off: While largely transparent to the user, it can create "thundering herd" problems where thousands of processes hit the storage system at once, requiring a backend that can handle high concurrency.
- Asynchronous checkpointing
- What it is: The training process "hands off" the checkpoint data to a background process and immediately resumes training the next batch. The save operation happens concurrently with continued GPU computation.
- The benefit: This is the holy grail for efficiency, as it can almost completely eliminate GPU stalls during checkpointing.
- The trade-off: It introduces significant complexity. You must ensure data consistency and have enough system memory and CPU resources to manage the background copy without interfering with the main training loop.
- Incremental or differential checkpointing
- What it is: Saving only the changes (deltas) in the model's state since the last full checkpoint, rather than the entire state every time.
- The benefit: Can reduce the size of intermediate checkpoints by 50-90%, drastically lowering the amount of data written.
- The trade-off: Recovery is more complex, as it may require replaying a full checkpoint plus several subsequent deltas, which can slow down resumption time.
There is no single "best" strategy. The right combination of storage architecture and optimization techniques is a strategic decision that depends entirely on your specific environment. The choice is a balancing act between cluster size, reliability (MTBF), I/O performance, engineering complexity, and, ultimately, your budget priorities.
How to plan your storage
Effective storage planning is a strategic enabler for large-scale AI. Viewing it as a mere backend detail introduces hidden costs and risks that can undermine the entire return on investment in compute. Making the right architectural and policy decisions requires understanding the full economic impact of checkpointing.
The budget impact of checkpointing extends far beyond the price per terabyte. It’s composed of two parts, and the less obvious one is often the most expensive.
- Direct storage costs: The daily accumulation of multi-terabyte checkpoints creates a significant storage footprint. In the cloud, this translates to a growing monthly bill—a 500 TB requirement, for example, can easily exceed $10,000 per month. On-premises, it demands costly and complex expansions of high-performance parallel filesystems.
- Indirect compute costs: This is the hidden financial drain. Every minute the cluster is paused writing a checkpoint, hundreds or thousands of expensive GPUs sit idle. Consider a 512-GPU cluster where a checkpoint takes 10 minutes. At a conservative $2/GPU-hour, that single pause costs over $170 in wasted compute. If checkpoints are hourly, that translates to over $4,000 per day and can quietly consume 10-20% of the total training budget over the long run.
The crucial insight is that the indirect cost of inefficient checkpointing often dwarfs the direct cost of the storage itself. Addressing this challenge requires moving beyond ad-hoc solutions. A forward-looking storage strategy for AI is built on four pillars:
1. Budget holistically by coupling storage and compute investments: Treat storage performance as a core component of the compute budget, not a separate line item. For every dollar spent on adding GPUs, allocate a corresponding investment in storage throughput and capacity. This ensures the storage infrastructure can keep the compute resources productive, maximizing the ROI of your most expensive hardware.
2. Balance performance and cost: Embrace a hybrid storage model as a deliberate architectural choice. Utilize high-performance NVMe for the "hot tier" to instantly absorb checkpoints and minimize GPU stalls. Then, offload those checkpoints to cost-effective object storage for long-term retention and durability. This tiered approach offers the best of both worlds: optimal performance where it matters and cost-effective scalability at scale.
3. Define policies based on risk appetite: The decision of how often to checkpoint is a risk management policy, not just a technical setting. Frame the conversation around the business question: "What is the acceptable cost of lost compute if a failure occurs?" This will help define a checkpoint frequency that aligns with your cluster's reliability and your project's financial stakes, rather than relying on arbitrary defaults.
4. Make checkpointing a KPI: Elevate checkpoint efficiency from an operational metric to a Key Performance Indicator (KPI) for the entire cluster. Actively monitor checkpoint duration, I/O throughput, and the resulting GPU idle time. Tracking these metrics will reveal hidden inefficiencies and provide a clear business case for future investments in storage infrastructure.
Best practices and recommendations
An effective checkpointing strategy is not just a technical detail—it’s an operational and financial decision that bridges engineering and infrastructure planning. Success depends on a coordinated approach to architecture, implementation, and governance. The following recommendations provide a unified framework for managing checkpoints efficiently at any scale.
1. Proactive planning and architecture
Before a single training job is launched, foundational decisions about budget and architecture must be made to prevent bottlenecks later on.
- Budget Holistically: Treat storage as a core component of the compute budget. A practical rule of thumb is to plan for 3–5 times the final model size in active checkpoint storage capacity for each concurrent training run.
- Architect a hybrid, tiered model: Design a storage system that balances performance and cost. Use extremely fast local NVMe as a "hot" tier to absorb checkpoint writes instantly, minimizing GPU stalls. In the background, offload these checkpoints to a durable and cost-effective persistent tier, such as a parallel filesystem or an object store, for long-term retention.
- Benchmark early and often: Do not wait for a full-scale training run to discover I/O limitations. Measure checkpoint write times and storage throughput during smaller pilot runs to model performance at scale and validate your architecture.
2. Efficient implementation and optimization
During implementation, the focus shifts to minimizing the I/O footprint and reducing the time spent on each save operation.
- Parallelize the write path: Use sharded checkpoints, a standard feature in modern distributed frameworks, to split a large checkpoint into smaller pieces that can be written in parallel by multiple GPUs or nodes. This dramatically reduces the wall-clock time for each save.
- Reduce the data volume: Whenever possible, use incremental or differential checkpointing to save only the changes since the last full save. Additionally, consider lightweight compression algorithms to shrink checkpoint size by 20-40%, keeping in mind the trade-off with CPU overhead.
- Automate data lifecycle management: Implement automated retention policies to manage storage growth effectively. A common strategy is to prune older checkpoints intelligently—for example, keeping every complete checkpoint from the last 24 hours, then one per day for a week, and one per week for long-term archival.
3. Smart governance and operations
Ongoing success requires treating checkpointing as a core operational process governed by business logic and continuous improvement.
- Define policies based on business risk: Frame the checkpoint frequency not as a technical setting, but as a risk management policy. Calculate the cost of idle GPUs during a save versus the potential financial loss of restarting a job from an older checkpoint. This allows you to select a frequency that aligns with your organization's risk tolerance.
- Monitor, measure, and iterate: Treat checkpoint efficiency as a Key Performance Indicator (KPI) for your cluster. Actively track metrics like average save duration, I/O throughput, and time to recovery. Use this data to revisit and refine your policies as cluster size, model scale, and hardware reliability evolve.
- Embrace the trade-off: Recognize that there is no universal "best" strategy. The ideal balance between performance, cost, and resilience is a dynamic target that depends on your specific infrastructure, budget, and project goals. Acknowledge this trade-off and make conscious decisions rather than relying on defaults.
How to get the best out of your storage
The journey to large-scale AI is paved with powerful GPUs, but its success is often determined by a component too frequently overlooked: storage. As we've seen, the seemingly simple act of checkpointing evolves from a manageable background task on small clusters into a critical performance and cost-efficiency bottleneck at scale. The challenge is not just about capacity; it's about throughput, concurrency, and the immense financial cost of idle compute.
By understanding the forces at play—from the multiplicative cost of I/O stalls to the trade-offs of different optimization strategies—organizations can transform storage from a hidden risk into a strategic advantage. Architecting a hybrid storage model, defining policies based on business risk, and treating efficiency as a key performance indicator are no longer niche optimizations; they are essential practices for success in production AI.
While the principles are clear, designing, provisioning, and managing this ideal infrastructure is a significant engineering challenge in itself. For teams that want to focus on training world-class models, not on fighting I/O bottlenecks, a purpose-built environment is key.
At CUDO Compute, our GPU clusters are built to your exact specifications, including the tiered, high-performance storage required to handle the most demanding checkpointing workloads. Contact us today to design a GPU cluster with a storage architecture built for your AI needs.
