 Resources
Resources 
The race to deploy ever-larger language models has pushed infrastructure budgets sky-high, but where those workloads run now matters more than ever. A 2025 survey of 1,000 IT leaders found that 88.8% believe no single cloud provider should control their entire stack, and 45% say vendor lock-in has already hindered their ability to adopt better tools.
Hidden network charges are a major culprit. Gartner estimates that data-egress fees consume 10–15% of a typical cloud bill, while IDC research puts the figure at roughly 6% of total storage spend, even for well-managed teams.
To put egress economics in perspective: AWS charges $0.09/GB for data transfer beyond the first 100 GB. Moving a 1 PB training corpus out of AWS costs approximately $92,000 in egress alone—before accounting for the engineering time to execute the migration. At hyperscaler scale, these charges compound.
The impact on AI roadmaps is stark, with 65% of enterprises planning GenAI projects saying soaring egress costs are a primary driver of their multicloud strategy. Those dollars represent training runs that never happen and product features that ship late.
In this article, we discuss the technical, economic, and competitive downsides of vendor lock-in and demonstrate how an open, on-demand platform enables AI teams to stay agile and reduce per-token costs.
Spin up a dedicated GPU cluster on CUDO Compute in minutes—no contracts, no egress penalties. Request a demo
The real cost of vendor lock-in
When you scale the 10-15% data egress fees we discussed earlier to real-world figures for transferring petabytes of AI datasets, the numbers can explode exponentially. Apple reportedly paid $50 million in a single year just to extract data from AWS. Every unexpected egress charge represents a training run that will never happen and a feature that ships late.
Moreover, commit-discount contracts can exacerbate the cost of vendor lock-in, as multi-year agreements bind workloads to specific GPU SKUs and regional pricing. When next-generation accelerators like Blackwell arrive, teams face steep penalties for jumping ship or resigning themselves to last-generation hardware until their contracts expire. These long-term deals are one of the most overlooked financial risks in IT sourcing.
A cloud provider with proprietary services, such as managed AutoML pipelines, bespoke vector databases, and custom accelerators, makes lock-in even more challenging. Switching means weeks of refactoring and thousands of engineering hours. The resulting cycle of dependence becomes a drag on long-term growth and resilience, especially for data-intensive AI workloads.
When a single vendor doesn’t offer GPUs in every geographical location, it can turn into a latency tax as requests hop across regions, adding 5–20ms per extra leg and eroding real-time inference SLAs. For recommendation engines and conversational agents, those milliseconds translate directly into lower engagement and revenue.
Taken together, these costs don’t just inflate OpEx—they slow iteration, inflate per-token economics, and sap budgets.
The hidden cost stack
Beyond egress, several items inflate cloud GPU bills without appearing in headline pricing:
| Cost category | Typical impact | Why it matters |
|---|---|---|
| Data egress | $0.08–$0.12/GB | Moving 10 TB = $800–$1,200; moving 1 PB = $80K–$120K |
| Cross-region transfer | $0.02/GB | Multi-region training or failover multiplies transfer costs |
| Storage tiers | $0.02–$0.10/GB/month | Hot storage for active datasets adds up at petabyte scale |
| Reserved instance lock-in | 40–70% "savings." | Requires 1–3 year commitment; strands you on last-gen GPUs |
| Quota approval delays | Days to weeks | Hyperscalers require approval for GPU quotas—slowing project starts |
| Idle instance charges | 100% of hourly rate | Paying for GPUs during data loading, debugging, or overnight |
Teams often discover these costs only after the first invoice. A GPU that costs $3/hour on paper can reach $5–6/hour in practice once storage, networking, and idle time are factored in.
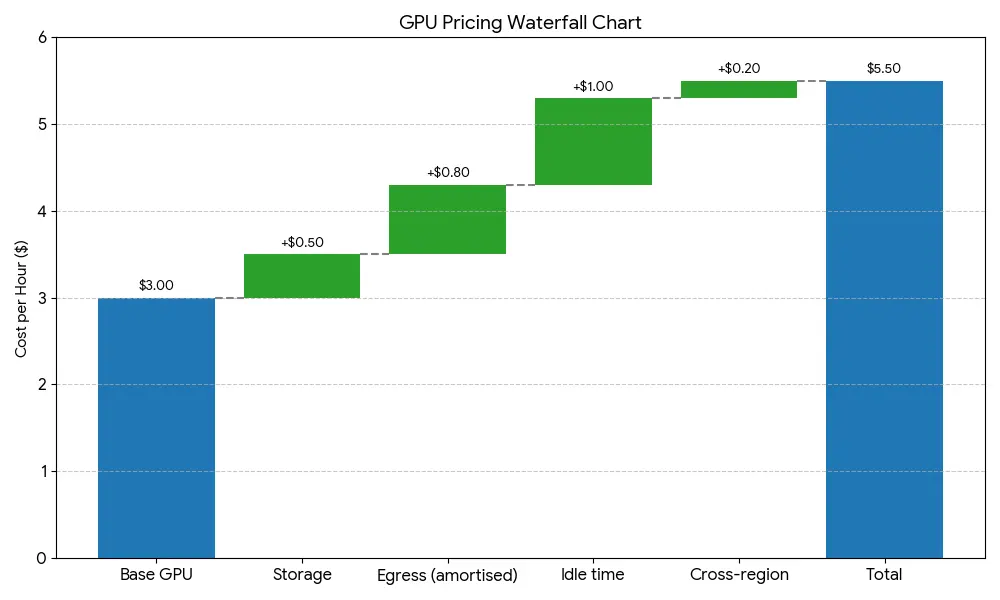 Alt text: Waterfall chart showing hidden cloud GPU costs adding 80% to the base hourly rate
Alt text: Waterfall chart showing hidden cloud GPU costs adding 80% to the base hourly rate
How vendor lock-ins stop AI development
Beyond the headline costs, vendor lock-in erodes the very speed and agility that keep AI teams competitive. Here’s how it derails rapid deployment cycles:
Capacity gridlock stalls iteration:
When a single provider’s GPU inventory is oversubscribed, which is common during new‑model hype cycles, projects queue behind other users' jobs. Teams that could have burst to an alternative cloud are then forced to wait, turning what should be a 24-hour hyperparameter sweep into a week-long wait.
The opportunity cost compounds into slower training loops, resulting in fewer model revisions, slower error discovery, and ultimately a slower path from proof of concept to production.
Proprietary APIs freeze your tech stack in time:
Lock‑in often arrives disguised as convenience. Managed vector‑search services or AutoML pipelines accelerate a first release, but the bespoke SDKs they require become concrete once you embed them in hundreds of scripts and notebooks.
Migrating even a modest‑sized codebase away from a vendor‑specific API surface usually means weeks of refactoring, duplicated CI pipelines, and re‑testing—time that should be spent on model innovation, not plumbing.
Data gravity keeps research isolated:
In large-scale language modelling, dataset curation and augmentation are continuous processes. When your training corpus is stranded in a single object store because egress is punitive, you cannot easily copy subsets to specialised compute—say, GPU nodes with larger HBM for efficient sequence-to-sequence fine-tuning.
The economics can be stark: transferring 100 TB from AWS to run experiments on a cheaper provider costs approximately $9,000 in egress fees alone. That's before compute, before engineering time. At that price, researchers self-censor. Promising side projects die in planning because every additional terabyte costs thousands to move.
Zero-egress providers like CUDO Compute eliminate this friction. When moving a 1 PB corpus costs hours of transfer time rather than six figures in fees, experimentation becomes economically rational again.
Hardware mismatch locks you out of next‑gen accelerators:
Commit discounts can tie workloads to last-generation GPUs long after faster, more energy-efficient ones are shipped elsewhere. Missing a hardware refresh cycle is more than a 20‑30 % throughput hit—it can force architectural compromises such as shorter context windows and smaller batch sizes that degrade final model quality. Meanwhile, competitors training on the latest GPUs converge sooner and iterate faster, widening the lead.
The math is unforgiving. An H100 delivers roughly 2–3x the training throughput of an A100 for transformer workloads. Teams locked into 3-year A100 reserved instances signed in 2023 are now paying similar hourly rates for half the performance, while competitors on flexible contracts have already migrated to H100s and are evaluating H200 and Blackwell availability. The contract that saved 40% on paper now costs 100% in a competitive position.
Compliance and sovereignty roadblocks:
As AI regulation tightens, teams must relocate data and compute resources to jurisdictions that align with new rules or customer contracts. If a provider lacks sovereign regions—or if moving petabytes out incurs seven‑figure penalties—compliance projects stall. The engineering hours diverted to legal firefighting and audit prep are hours not spent on model‑level improvements.
Strategic myopia at the executive level:
Finally, lock‑in encourages incremental, provider‑defined roadmaps. When every new feature must fit within one vendor’s service catalogue and pricing model, bold bets—such as spinning up a transient, spot‑only GPU fleet for aggressive exploratory research—never reach the planning stage. The organisation optimises locally to meet its contract constraints rather than globally to maximise product impact.
Net effect: vendor lock‑ins don’t just raise costs; they place a hard cap on the pace and scope of innovation. AI teams that remain portable—able to shift data, code, and compute at will—capture outsized learning cycles, ship features sooner, and adapt fluidly as both hardware and regulations evolve.
In the next section, we’ll examine the architectural patterns that make portability a reality, from container-native pipelines to storage layers that follow your workloads, not the other way around.
Cost efficiency with vendor‑neutral GPU clouds
Lock-in might be tolerable if it also guaranteed the best price-performance, but the public numbers suggest otherwise.
On Google Cloud’s H100 VM, the standard on‑demand rate is around $11.06 per GPU‑hour. Third-party trackers indicate that the big three clouds span roughly $9–$13 per H100 hour, once regional uplifts and mandatory support tiers are factored in. At those prices, a single week‑long fine‑tune of a 70 B‑parameter model breaks six figures before the first inference token is served.
CUDO offers the H100 on demand at $2.25 per hour, which is a 70–80% discount with a long-term commitment. A recent benchmark study demonstrated how those lower prices can make a difference to your workloads.
Read more here: Real-world-gpu-benchmarks
SemiAnalysis’ report concludes that plural‑vendor “neo‑clouds” already beat hyperscalers by 30–50% on $/PFLOP for training, and predicts further declines as Blackwell‑class GPUs hit the market. In other words, today’s $10‑plus hyperscaler rate isn’t just expensive—it’s structurally unsustainable.
Hyperscaler vs. vendor-neutral pricing (H100, on-demand)
| Provider type | H100 $/hour | Egress fees | Contract required |
|---|---|---|---|
| AWS (p5.48xlarge) | ~$3.90/GPU* | $0.09/GB | No (but reserved = 1–3 yr) |
| Azure (ND H100 v5) | ~$3.50–$4.00/GPU | $0.08/GB | No (but reserved = 1–3 yr) |
| GCP (A3) | ~$3.00/GPU | $0.12/GB | No (but CUDs = 1–3 yr) |
| CUDO Compute | $2.25/GPU | $0.00 | No |
- AWS cut H100 prices 44% in June 2025; prices reflect post-cut rates.
Vendor‑neutral, on‑demand GPU clouds convert every dollar of budget into FLOPs and feedback cycles instead of egress charges and depreciation schedules. AI teams that stay portable run more experiments, converge faster, and keep runway for the next breakthrough—advantages we’ll focus on during the next section, where we show you how to design a lock‑in‑free stack from orchestration to data layer.
Designing a lock‑in‑free AI stack
A portable architecture isn’t a single product—it’s a set of design choices that together let data, code, and compute move wherever economics or compliance dictate.
1. Portable orchestration layer
Kubernetes remains the de facto scheduler for containerised AI, precisely because clusters can run on laptops, on‑prem bare metal, or any public cloud with near‑zero refactoring. A review of containerisation research notes that multi‑cloud Kubernetes facilitates workload portability and optimised resource utilisation across heterogeneous hardware. Recent analyses rank Kubeflow as the most mature open-source ML pipeline orchestrator for deep-learning, time-series, and LLM use cases.
2. Idempotent infrastructure‑as‑code
Terraform (or Pulumi) abstracts away vendor-specific APIs, allowing the same module to target CUDO Compute today and a sovereign Kubernetes cluster tomorrow. Teams that bake IaC drift checks into CI pipelines report 83 % higher success rates when switching clouds.
3. Neutral data plane
S3-compatible object storage avoids proprietary metadata layers that can trap datasets. Pair it with open table formats (e.g., Iceberg/Delta Lake) so that metadata can also travel. Because CUDO Compute charges zero egress on object storage, the cost of migrating a 1 PB corpus is measured in hours, not millions.
4. Observability that travels
Prometheus, Grafana, and OpenTelemetry emit standard metrics you can scrape anywhere. When latency spikes, you need to know whether to burst a second region or re‑shard a vector index, without opening multiple vendor consoles.
5. Cost‑aware scheduling
Research on DRL-based resource scheduling shows that dynamic placement—choosing the cheapest or least-loaded cluster in real-time—cuts task latency and improves utilisation. Feed live CUDO spot‑price APIs into a scheduler and let the model chase the best $/TFLOP each hour.
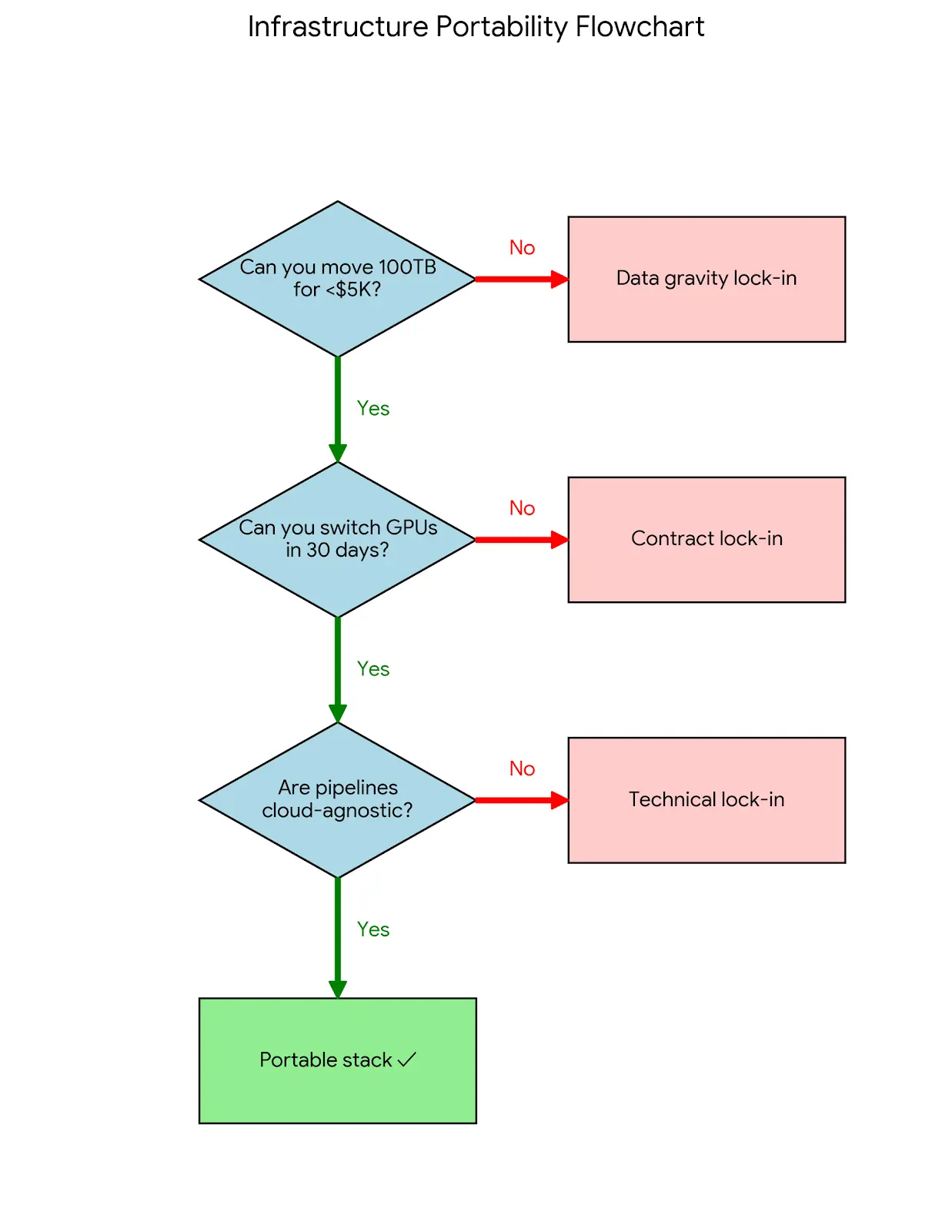
Portability self-assessment
Before your next infrastructure decision, ask:
- Can we move 100 TB to another provider in under a week without exceeding $5,000?
- Could we switch GPU providers within 30 days if our current vendor raised prices 50%?
- Are our ML pipelines defined in Kubernetes/Kubeflow manifests that run anywhere?
- Do we have exit terms documented in our cloud contracts?
- Is our training data in S3-compatible storage with open table formats?
If you answered "no" to two or more, you're likely locked in.
How CUDO Compute makes portability pragmatic
| Capability | What does it mean for your team? |
|---|---|
| On‑demand H100 clusters at public rates | H100 $2.25 / hr per GPU (70‑80 % below hyperscaler rate). |
| Zero egress fees | Shift terabytes between research, prod, and archival without a “cloud tax.” |
| Terraform provider & REST API | Drop‑in modules slot into existing IaC; no proprietary SDK required. |
| Bare‑metal or Kubernetes clusters in 15+ regions | Train where capacity is abundant; serve inference where users live—no latency tax. |
| Marketplace supply model | New GPU SKUs appear weeks—not quarters—after launch so that you can adopt Blackwell on day one. |
While vendor lock‑in once felt like the price of convenience, it’s now a strategic liability—ballooning costs, stalling iteration loops, and boxing teams out of next‑gen hardware. A portable stack, anchored by open tooling and supported by cost‑efficient providers like CUDO Compute, flips that script. You pay for compute, not captivity, and turn budget into faster models and more ambitious research.
Launch a lock‑in‑free cluster today
Spin up a dedicated GPU cluster on CUDO Compute in minutes—no contracts, no egress penalties. Contact us to learn more.
