 Resources
Resources 
Neural networks have become a cornerstone of modern artificial intelligence (AI), powering innovations across various domains, from voice assistants like Siri and Alexa to self-driving cars. But what exactly is a neural network, and why is it important?
Neural networks are inspired by the structure and function of biological neural networks. Its inspiration is rooted in how neurons in the brain process information through synapses. Artificial neural networks (ANNs) mimic this process by using interconnected nodes (neurons) that transmit signals.
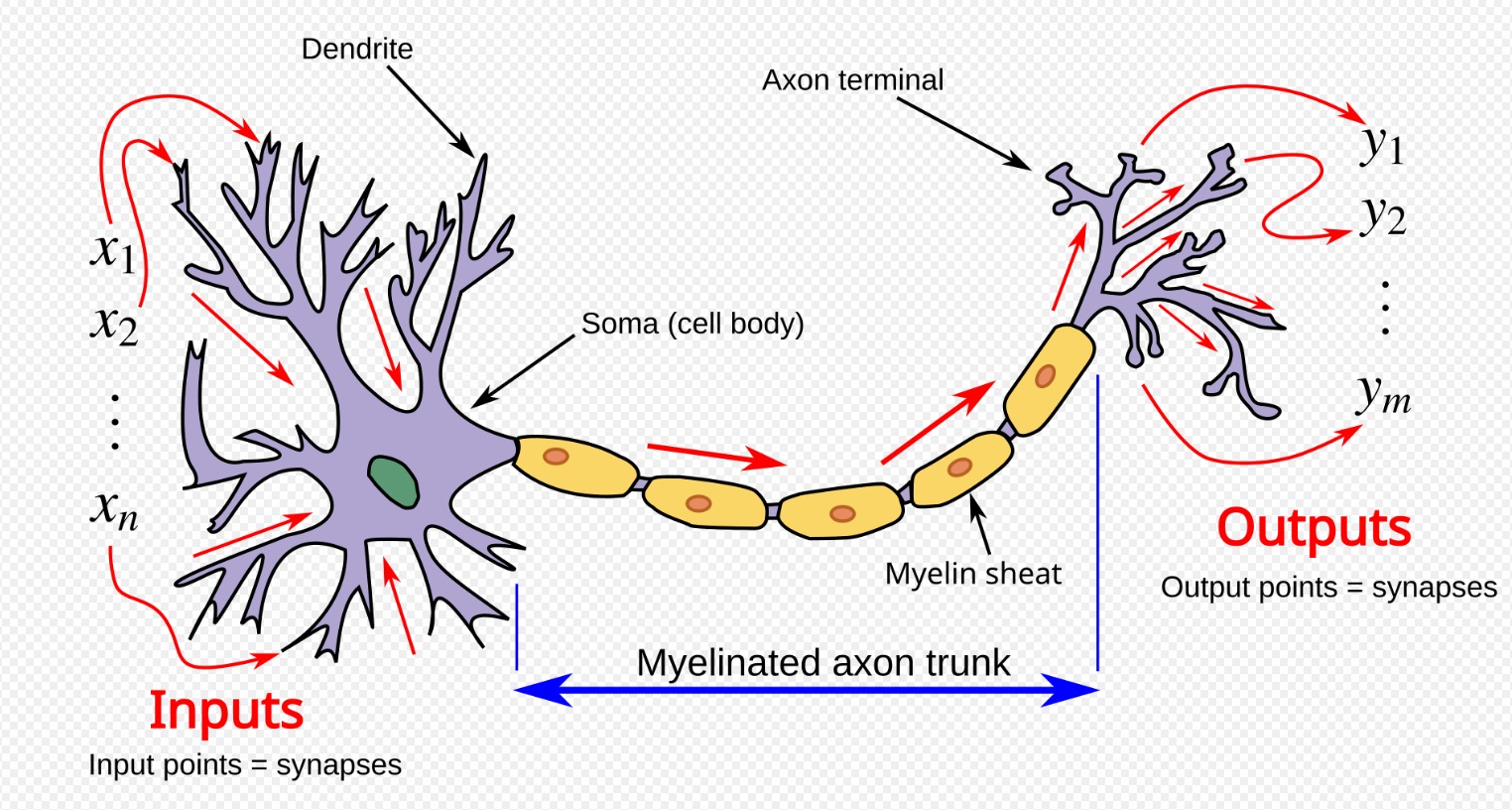 Source: Wikipedia
Source: Wikipedia
The architecture of artificial neural networks typically consists of layers of nodes. Each node in one layer is usually connected to nodes in the subsequent layer, allowing for complex data transformations as it moves through the network.
A neural network is designed to recognize patterns in data and learn from examples through training. In this article, we will explore the fundamentals of neural networks, delve into their workings, and discuss their applications.
Basic concepts of neural networks
The concept of neural networks dates back to the 1940s. The earliest model was the McCulloch-Pitts neuron, introduced by Warren McCulloch and Walter Pitts in 1943. This model laid the foundational theory for the mathematical modeling of biological neurons.
Before the late 20th and early 21st centuries, neural networks were limited by computational resources and the need for more sufficient data. However, the practical application of neural networks gained momentum with the advent of powerful computing resources, such as GPUs, and the availability of large datasets.
You can get access to the lates NVIDIA GPUs for AI development on CUDO Compute at a competitive rate. CUDO Compute offers the NVIDIA H100 on demand starting from $3.49/hour. Get started today!
These factors enabled the training of deep networks, making them viable for complex tasks like image and speech recognition. To understand how neural networks function, let us discuss their basic building blocks.
Layers
Neural networks consist of multiple layers of interconnected nodes. These layers play distinct roles in processing and transforming data as it flows through the network. There are three primary types of layers:
- Input Layer: The input layer is the initial layer in a neural network. It is responsible for receiving raw data directly from the external environment. This layer doesn't perform any computations itself; instead, it passes the data to the next layer for processing.
Each node (or neuron) in the input layer typically corresponds to a feature or attribute of the input data. This mapping allows the network to understand and process each input component separately.
For instance, In image recognition tasks, each node in the input layer can represent a pixel value from the image. For a grayscale image, this could be a single intensity value, while for a color image, each pixel might be represented by multiple values (e.g., RGB channels).
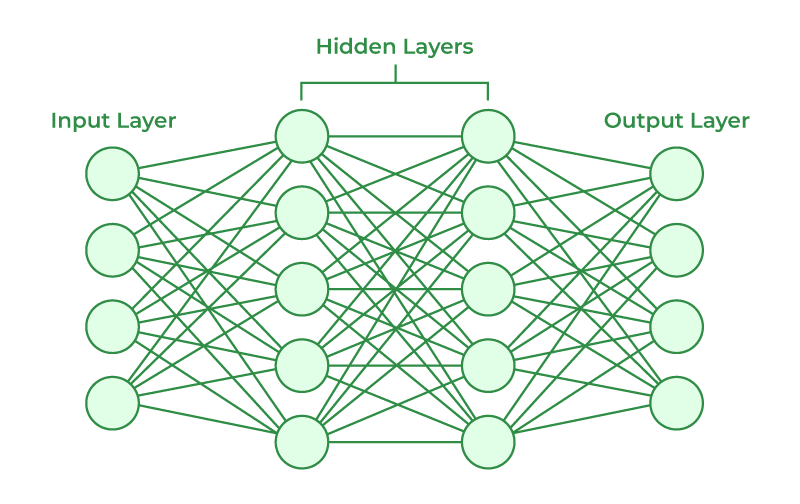 Source: Geekforgeeks
Source: Geekforgeeks
- Hidden layers: Hidden layers are between the input and output layers. They are responsible for most of the computation and transformation within the network. Neural networks can have one or more hidden layers, with deeper networks having multiple hidden layers.
The number of hidden layers and nodes in each layer can significantly impact the network's ability to learn complex patterns. Deep learning focuses on training neural networks with many hidden layers to achieve high performance on tasks like image and speech recognition.
- Output layer: The network's final layer produces the network's prediction or output. The structure of the output layer depends on the nature of the task. For example, in a classification task, the output layer might have multiple nodes, each representing a different class, and the node with the highest activation would indicate the predicted class.
Neurons and Perceptrons
The basic computational unit of a neural network is a neuron. Neurons receive inputs from other neurons or directly from the input data, process those inputs, and then produce an output. Think of a neuron in a neural network as a tiny decision-maker. Its job is to take in information, process it, and then decide whether to pass along a signal to other neurons.
A layer in a neural network is composed of multiple neurons. Each neuron within a layer typically receives input from all or a subset of the neurons in the previous layer and sends its output to all or a subset of the neurons in the next layer.
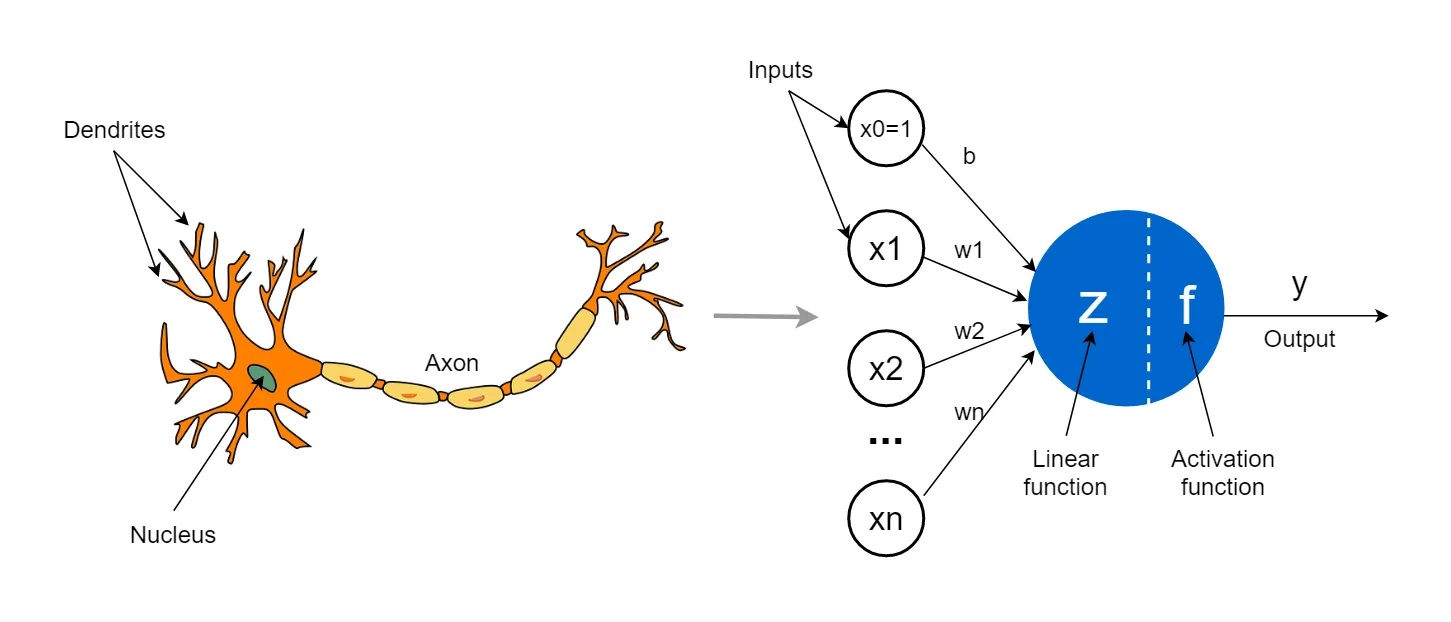 Source: Towards Data Science
Source: Towards Data Science
The number of neurons in a layer can vary depending on the specific architecture and the complexity of the task the network is designed to handle. In general, hidden layers often have more neurons than the input or output layers, as they are responsible for learning and representing complex features within the data.
A perceptron is the simplest type of neuron and is typically used in single-layered neural networks. These networks are primarily suited for tasks involving linear classification and are limited to solving problems where the data is linearly separable.
Weights
Weights are components in neural networks that control and adjust the strength of connections between neurons. Each connection between two neurons has an associated weight, which determines how much influence the output of one neuron has on the input of another neuron.
Positive weights indicate a positive or excitatory connection, meaning the output of one neuron increases the likelihood of the next neuron firing (sending a signal). Conversely, negative weights indicate a negative or inhibitory connection, meaning the output of one neuron decreases the likelihood of the next neuron firing.
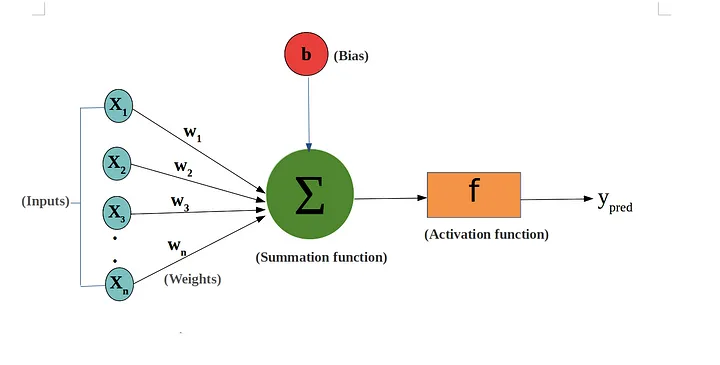 Source: Towards Data Science
Source: Towards Data Science
The absolute value of a weight represents the strength of the connection. Larger weights have a more significant impact on the next neuron's input.
During a neural network's training, these weights are adjusted iteratively. The network learns by finding the optimal set of weights that allow it to make accurate predictions or classifications based on the input data.
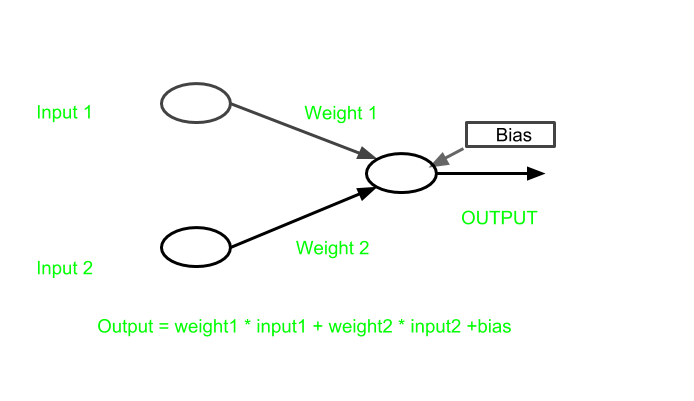
Bias
Bias is an additional parameter within a neuron that acts like an internal threshold or a constant input value. It can be thought of as a neuron's predisposition or inherent preference. The bias value shifts the activation function curve to the left or right, effectively adjusting how easily the neuron activates.
- Positive Bias: Makes the neuron more likely to fire (output a '1').
- Negative Bias: Makes the neuron less likely to fire (output a '0').
 Source: GeeksforGeeks
Source: GeeksforGeeks
The bias allows a neuron to fire even when all its inputs are zero. It provides flexibility in the neuron's decision-making process, helping the network model more complex relationships in the data.
Activation functions
Activation functions are mathematical functions that determine whether a neuron should fire (output a '1') or not (output a '0') based on the weighted sum of its inputs and the bias. They introduce non-linearity into the network, which helps the model learn complex patterns in data. Common activation functions include:
- Step function: This is a simple threshold-based function used in perceptrons. It outputs '1' if the input is above the threshold and '0' otherwise.
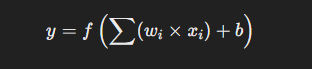
The step function was used in early neural networks, like perceptrons, to simulate binary neuron firing. However, it is rarely used in modern networks because it doesn't work well with gradient-based learning, as it provides no gradient (the derivative is zero) except at the threshold point.
- Sigmoid function: This function produces a smooth, S-shaped curve that maps the input to a value between 0 and 1. It's often used in the output layer for binary classification tasks.
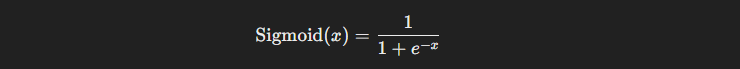
Sigmoid functions are often used in the output layer for binary classification tasks where probabilities are needed, as they output a probability-like value. However, they can suffer from the vanishing gradient problem, where gradients become too small for effective learning in deep networks.
- ReLU (Rectified Linear Unit): Outputs the input if it's positive and '0' if it's negative. ReLU is widely used in hidden layers due to its computational efficiency and ability to mitigate the vanishing gradient problem.
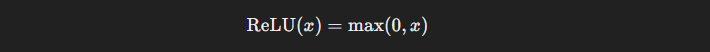
ReLU is widely used in hidden layers of neural networks due to its computational efficiency and ability to mitigate the vanishing gradient problem by allowing gradients to pass through when inputs are positive.
It can suffer from the "dying ReLU" problem, where neurons output zero for all inputs if they get stuck in the negative region.
- Tanh (hyperbolic tangent): This function is similar to the sigmoid function but outputs values between -1 and 1. It's commonly used in hidden layers because its zero-centered output provides better gradient flow than the sigmoid function.
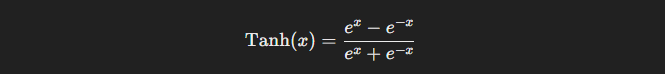
Although better than sigmoid, it can still suffer from vanishing gradients, especially in very deep networks.
Now that we know the basics of a neural network let’s discuss how it works.
How neural networks work
To understand how neural networks work, we will examine their learning process, which is primarily based on forward propagation for generating predictions and backward propagation for updating weights to improve model accuracy. Let’s break that down.
Forward Propagation
The process begins with input data being fed into the neural network's input layer. As data progresses through each layer of the network, neurons in a layer compute the weighted sum of their inputs by multiplying each input by a corresponding weight and adding them together along with a bias term.
The weighted sum is then passed through an activation function, which introduces non-linearity and determines the neuron's output and the output from each neuron is passed as input to the next layer. The forward propagation process continues through all layers until it reaches the output layer.
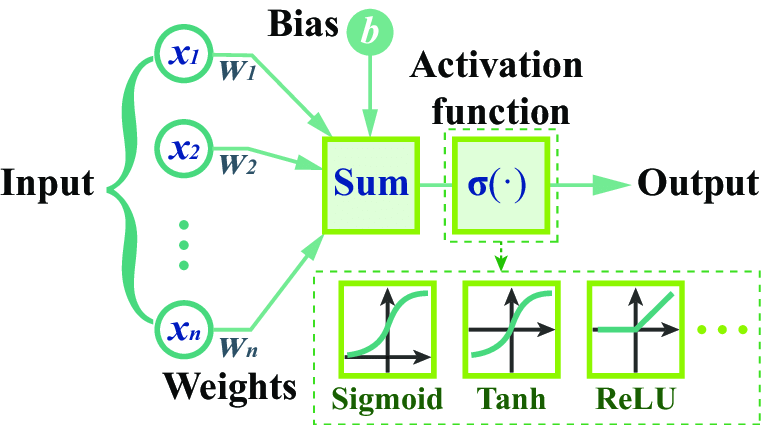 Source: Paper
Source: Paper
The neurons in the output layer generate the final predictions or outputs based on the processed inputs, which could be class probabilities for classification tasks or numerical values for regression tasks.
Forward propagation is primarily concerned with predicting outputs from given inputs based on the current state of the network's weights and biases, and by applying activation functions at each layer, the network can model complex, non-linear relationships in the data.
While forward propagation generates predictions, neural networks need a way to learn from their mistakes and improve over time, which is why the loss function and optimization are necessary.
Loss function and optimization
The primary goal of a neural network is to make predictions that closely match the actual target values. During training, the network adjusts its parameters (weights and biases) to minimize prediction errors. To achieve high accuracy, the network must be optimized to generalize well from training data to unseen data, reducing bias and variance.
The loss function, also known as the cost or objective function, quantifies the difference between the predicted outputs and the actual target values. It provides a scalar value representing the error, which is used to guide the optimization process during training. Lower loss indicates better performance.
Common loss functions include mean squared error (MSE) for regression tasks and cross-entropy loss for classification tasks. MSE calculates the average of the squares of the differences between predicted and actual values, while cross-entropy loss measures the dissimilarity between the true distribution and the predicted distribution of classes.
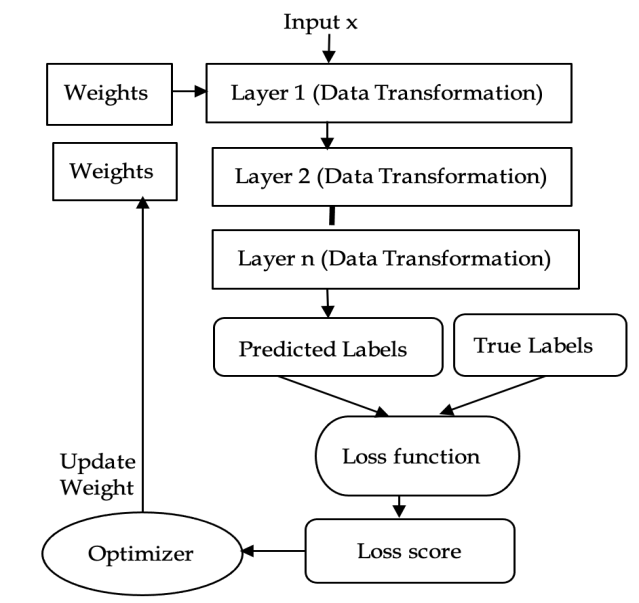 Source: Paper
Source: Paper
Optimization algorithms are used to find the set of weights and biases in a neural network that minimizes the loss function, thus improving the network's performance. These algorithms iteratively update the network parameters to reduce the error between predicted outputs and actual target values.
Gradient Descent is a popular optimization algorithm that updates the weights and biases of a network based on the gradient of the loss function. The algorithm computes the gradient of the loss function for each weight and bias using partial derivatives that indicate how much the loss would change with a slight change in each parameter.
The core idea of gradient descent is to use the gradient information to make incremental adjustments to the weights, steering them toward values that minimize the loss function. The process is repeated iteratively until convergence is achieved, meaning the changes in loss are minimal, indicating that the optimal (or near-optimal) weights have been found.
Several variations of gradient descent exist, including stochastic gradient descent (SGD), mini-batch gradient descent, momentum-based methods, and adaptive learning rate methods (e.g., Adam, RMSprop) that improve convergence speed and stability.
Backpropagation
Backpropagation is a fundamental algorithm used in training neural networks. Its primary purpose is to update the network's weights and biases to minimize error or loss. The process begins with calculating the error using a loss function, quantifying the difference between the predicted output and the target.
Backpropagation calculates the gradient of the loss function for each weight and bias in the network, which is achieved using the chain rule of calculus, which allows the computation of derivatives of complex, multi-layer functions. The chain rule helps determine how each weight contributes to the final error, thereby enabling the calculation of partial derivatives of the loss function for each weight.
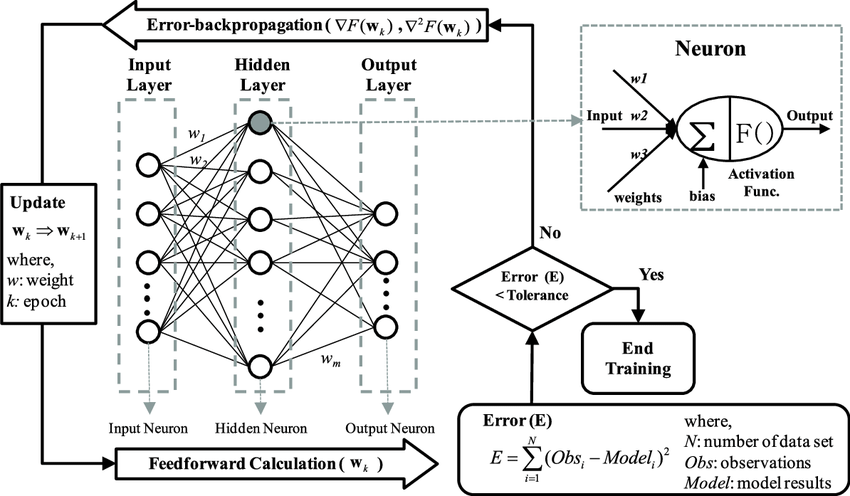 Source: Paper
Source: Paper
Once the gradients are calculated, the weights are adjusted in the opposite direction of the gradient because the gradient points in the direction of the steepest increase in loss, so moving in the opposite direction reduces the loss. The size of the weight update is controlled by the learning rate, a hyperparameter that determines how far the weights are adjusted during each update step.
The goal of backpropagation is to iteratively adjust the weights and biases to minimize the loss function, thereby improving the accuracy of the network's predictions over time.
The combination of forward propagation and backpropagation enables the neural network to learn from data and improve its performance over time.
Types of neural networks
Neural networks come in various architectures, each suited to specific tasks and data types. Here are some of the most prominent types:
Feedforward neural networks
Feedforward neural networks are the simplest form, where data flows unidirectionally from input to output without cycles. They are commonly used for tasks like classification and regression.
Convolutional neural networks (CNNs)
CNNs are designed to process grid-like data, such as images. They employ convolutional layers that apply filters to capture spatial features and patterns, making them effective for image recognition and object detection.
Recurrent neural networks (RNNs)
RNNs are specialized for sequential data, such as time series and natural language. They have connections that form cycles, allowing information to persist and be reused across different steps in the sequence. Variants like Long Short-Term Memory (LSTM) networks address the issue of vanishing gradients, enabling them to learn long-range dependencies.
Other specialized networks
Generative Adversarial Networks (GANs): Consist of two networks, a generator and a discriminator, which work together to produce realistic data samples.
Autoencoders: Used for unsupervised learning, these networks compress data into a lower-dimensional representation and then reconstruct it.
Applications of neural networks
Neural networks have revolutionized various industries by providing solutions to complex problems. Here are some key applications:
Image and speech recognition
Neural networks have dramatically improved the accuracy of image and speech recognition systems. CNNs are widely used in image classification tasks, powering applications like facial recognition and medical image analysis. In speech recognition, neural networks enable voice-activated assistants and transcription services.
Natural language processing (NLP)
In NLP, neural networks are used to process and understand human language. Tasks like sentiment analysis, machine translation, and text summarization benefit from models like transformers, which capture contextual relationships in text
Healthcare and diagnosis
In healthcare, neural networks assist in diagnosing diseases, predicting patient outcomes, and personalizing treatment plans. They analyze medical images, patient records, and genetic data to provide valuable insights for clinicians.
Conclusion
Neural networks are a fundamental component of modern AI. They are capable of solving complex problems and driving technological advancements. These models have become indispensable in various fields because they mimic the human brain's ability to learn and adapt.
As we progress, the continued development and application of neural networks can reshape industries, improve decision-making, and unlock new possibilities in artificial intelligence. Stay updated with our docs and resources, try different neural network architectures, and contact us to get access to the latest NVIDIA GPUs on demand and on reserve at CUDO Compute.
