 Resources
Resources 
In machine learning (ML), Graphics Processing Units (GPUs) have become indispensable. GPUs have revolutionised ML by accelerating training and inference processes, enabling researchers and practitioners to tackle complex problems more efficiently. However, with many GPU options, selecting the right one for ML tasks can take time and effort.
Choosing the right GPU for ML is crucial as it directly impacts the speed and efficiency of training and inference processes. GPUs are designed to handle parallel computations, making them ideal for ML tasks that involve massive amounts of data and complex mathematical operations. The selection process requires careful consideration of factors such as architecture, memory capacity, power consumption, and price.
Two prominent GPUs in the market, the NVIDIA A40 and V100 have garnered significant attention for their exceptional performance and capabilities. This article will comprehensively compare these GPUs, focusing on their specifications, performance, and suitability for various ML workloads.
Overview of the NVIDIA A40
The NVIDIA A40 is a powerful GPU built on the Ampere architecture. It boasts impressive specifications that make it a compelling choice for ML workloads. We discussed the NVIDIA A40’s enhanced tensor cores in a previous article. These tensor cores deliver exceptional performance for mixed-precision calculations, enabling faster training and inference without compromising accuracy.
The NVIDIA A40 GPU is a powerful and versatile tool for machine learning and artificial intelligence applications which offers excellent performance, large memory capacity, and high bandwidth. The A40 is also well-supported by NVIDIA's software ecosystem, which includes the CUDA Toolkit, cuDNN, and TensorRT.
Is NVIDIA A40 good for deep learning?
The NVIDIA A40 is well-suited for deep learning tasks. Its larger memory capacity and enhanced tensor cores allow for larger batch sizes and faster convergence, making it ideal for working with complex models and large datasets. Its cost efficiency makes it an attractive option for organisations with budget constraints.
Overview of the NVIDIA V100
The NVIDIA V100 GPU is a high-end graphics processing unit for machine learning and artificial intelligence applications. It was released in 2017 and is still one of the most powerful GPUs on the market. The V100 is based on the Volta architecture and features 5,120 CUDA cores, 640 Tensor Cores, and 16 GB of HBM2 memory. It has a boost clock of 1,455 MHz and a TDP of 300W.
The V100 is well-suited for deep learning, natural language processing, and computer vision tasks. The V100 is also compatible with various software frameworks, including TensorFlow, PyTorch, and Caffe2.
The V100’s exceptional parallel processing capabilities and tensor cores make it an excellent choice for tasks that demand high computational power, such as training complex models, running large-scale simulations, and performing advanced data analytics.
In summary, the NVIDIA A40 andV100 GPUs offer impressive specifications and performance for ML workloads. The A40's larger memory capacity and enhanced tensor cores make it suitable for deep learning tasks. In contrast, the V100's high CUDA core count and tensor cores excel in parallel processing and computationally intensive ML tasks. The choice between the two ultimately depends on the ML project's specific requirements and budget constraints.
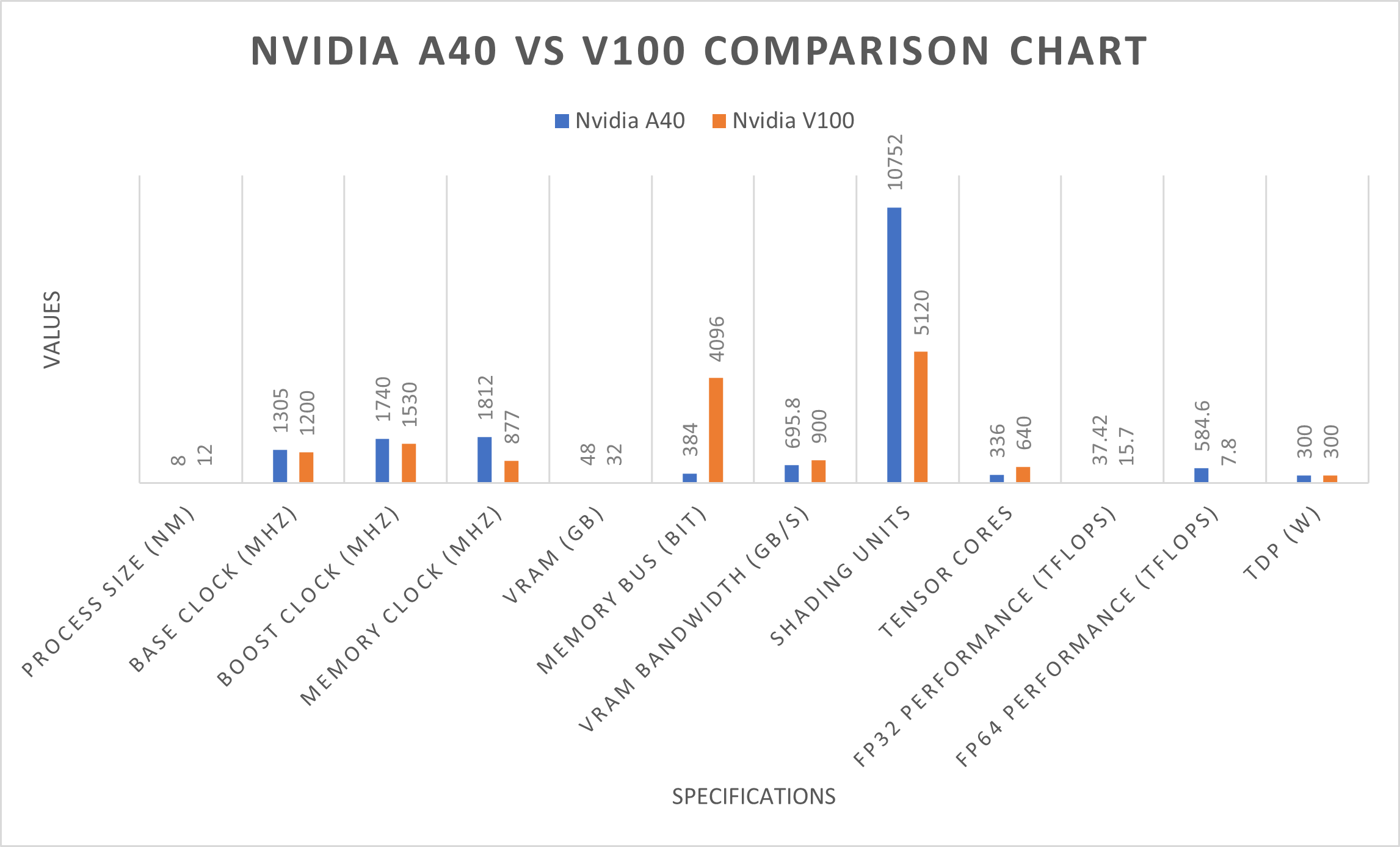
Here is a table summarising the key differences between the NVIDIA A40 and V100 GPUs:
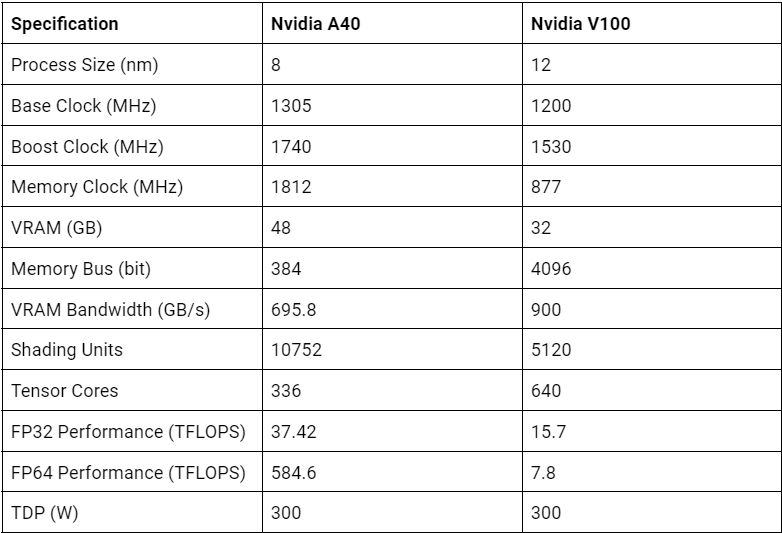
Here is how they compare in real-world scenarios:
A40 vs V100 performance comparison
Several factors come into play when comparing the computational capabilities of the NVIDIA A40 and V100 GPUs. These include TFLOPS (trillions of floating-point operations per second) and memory bandwidth, which directly impact the speed and efficiency of ML workloads.
- TFLOPS: the A40 offers 19.2 single-precision and 7.6 double-precision TFLOPS, while the V100 provides 14 single-precision and 7 double-precision TFLOPS. This indicates that the A40 has a higher computational capacity for single-precision calculations, commonly used in many ML tasks. However, both GPUs offer similar capabilities for double-precision calculations, which are more relevant for scientific computing and certain ML applications.
- Memory bandwidth: the A40 features a memory bandwidth of 696 GB/s, thanks to its GDDR6 memory, while the V100 offers a higher memory bandwidth of 900 GB/s with its HBM2 memory. The V100's higher memory bandwidth allows for faster data transfer between the GPU and memory, which can be advantageous in scenarios where large datasets need to be processed quickly.
Benchmark results in ML tasks can provide valuable insights into the performance differences between the A40 and V100. While specific benchmark results may vary depending on the ML framework, dataset, and model architecture, it is worth noting that the A40's Ampere architecture and enhanced tensor cores contribute to its superior performance in certain ML workloads.
In typical ML workloads, such as training deep learning models, the A40's larger memory capacity can be advantageous. It allows for larger batch sizes, reducing the time required for model convergence. The A40's tensor cores also deliver higher performance for mixed-precision calculations, enabling faster training without sacrificing accuracy. This makes the A40 well-suited for deep learning tasks that involve working with large datasets and complex models.
On the other hand, the V100's higher CUDA core count makes it a strong contender for parallel processing tasks and training large-scale convolutional neural networks (CNNs). Its parallel processing capability allows for efficient computation of matrix operations, which are fundamental to many ML algorithms. This makes the V100 an excellent choice for ML workloads that heavily rely on parallelism and require high computational power.
It is important to note that the performance differences between the A40 and V100 may vary depending on the specific ML workload and the optimisations implemented in the ML framework being used.
Conclusion: Which GPU is right for you?
Several key points have emerged in this comparison of the A40 and V100 GPUs for machine learning (ML) workloads. The A40 has a larger memory capacity, enhanced tensor cores for mixed-precision calculations, and cost efficiency. On the other hand, the V100 stands out with its higher CUDA core count, superior parallel processing capabilities, and higher memory bandwidth.
The A40's larger memory capacity and enhanced tensor cores make it a compelling choice for ML tasks that involve working with large datasets and complex models. It allows for larger batch sizes and faster convergence, making it suitable for deep learning workloads. The A40's cost efficiency makes it an attractive option for budget-constrained organisations.
On the other hand, the V100's higher CUDA core count and superior parallel processing capabilities make it ideal for ML workloads that heavily rely on parallelism and require high computational power. It is well-suited for training large-scale convolutional neural networks (CNNs) and computationally intensive tasks.
Ultimately, the choice between the A40 and V100 depends on the project's specific ML needs and budget constraints. For organisations and users with large-scale training requirements and a need for high computational power, the V100 may be the preferred option. However, for those focusing on cost efficiency and deep learning workloads, the A40 can provide a compelling solution. To leverage the power of these GPUs, consider using CUDO Compute for seamless and efficient GPU computing.
CUDO Compute offers a user-friendly platform that allows you to harness the full potential of NVIDIA A40 and V100 GPUs for your machine-learning tasks. With CUDO Compute, you can easily deploy and manage your GPU workloads, optimise resource allocation, and maximise efficiency. Take advantage of our robust infrastructure and advanced features to accelerate your deep learning projects. Sign up for CUDO Compute today and unlock the true potential of NVIDIA A40 and V100 GPUs for your machine learning needs.
About CUDO Compute
CUDO Compute is a fairer cloud computing platform for everyone. It provides access to distributed resources by leveraging underutilised computing globally on idle data centre hardware. It allows users to deploy virtual machines on the world’s first democratised cloud platform, finding the optimal resources in the ideal location at the best price.
CUDO Compute aims to democratise the public cloud by delivering a more sustainable economic, environmental, and societal model for computing by empowering businesses and individuals to monetise unused resources.
Our platform allows organisations and developers to deploy, run and scale based on demands without the constraints of centralised cloud environments. As a result, we realise significant availability, proximity and cost benefits for customers by simplifying their access to a broader pool of high-powered computing and distributed resources at the edge.
