 Resources
Resources 
Recurrent Neural Networks (RNNs) are a class of artificial neural networks specifically designed to handle sequential data, making them highly effective for tasks where the order of data points is important, such as forecasting, natural language processing (NLP), speech recognition, and other sequence-related tasks.
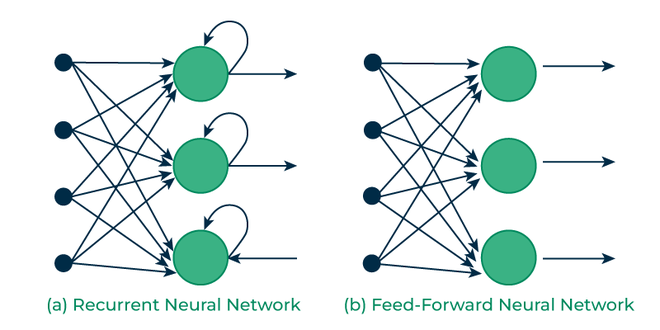
Traditional neural networks, such as feedforward neural networks, operate under the assumption that each input is independent of others. These models process data points individually without considering any inherent order or relationship between them.
 Source: Geeks for geeks
Source: Geeks for geeks
The independence assumption makes them unsuitable for tasks where the sequence and context of the data are needed, such as time series or any scenario where prior data influences the current decision.
CUDO Compute offers the infrastructure for your entire deep learning project pipeline. We offer cost effective cloud GPUs like the NVIDIA H100 on demand. Click here to get started.
In this article, we will explore RNNs, their architecture, working principles, and applications, aiming to provide a comprehensive understanding of deep learning models.
Let’s begin by discussing what RNNs are.
What are recurrent neural networks?
Recurrent neural networks handle sequential data by maintaining a ‘memory’ of previous inputs, achieved through loops within the network, allowing information to persist. In simple terms, RNNs can remember previous steps and use this contextual information to make decisions, which is useful in time-dependent tasks.
RNNs differ from traditional neural networks because they have connections that loop back on themselves, creating cycles in the network architecture. Its looping mechanism enables the RNN to retain information over time and process input sequences of varying lengths, which is impossible with standard feedforward networks.
An RNN processes each element in a sequence, considering both the current input and the 'hidden state'—a representation of the information gleaned from previous elements. The hidden state acts as the network's memory, carrying contextual information forward and enabling the RNN to make informed predictions or decisions based on the entire sequence rather than isolated inputs.
For example, in predicting the next word in a sentence, an RNN would consider not just the immediately preceding word but also the entire sentence structure up to that point.
Let's delve a bit deeper into the core components of an RNN.
Components of recurrent neural networks
While RNNs share fundamental building blocks with other neural networks like Convolutional Neural Networks (CNNs), such as input and output layers, the recurrent unit is the core component that makes RNNs different. Unlike traditional neurons in feedforward networks, recurrent units have connections that loop back to themselves.
Its self-loop allows it to maintain an internal state, often referred to as the "hidden state" or "memory,” which captures information from previous time steps and enables the unit to consider the context of the current input.
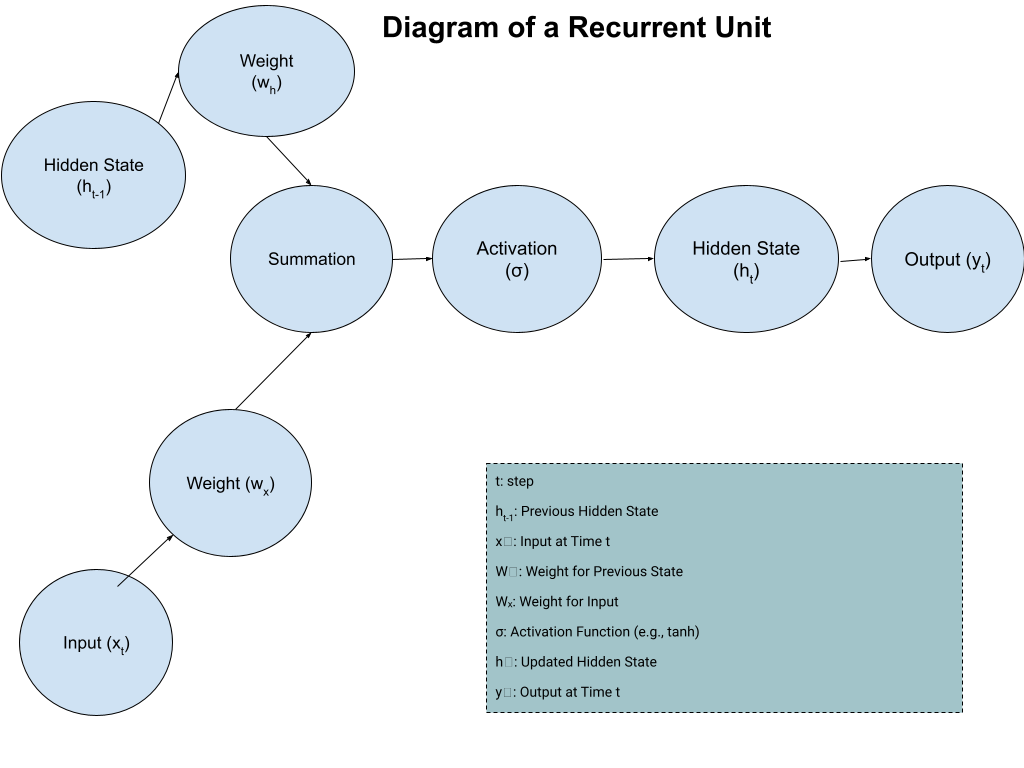
Within each recurrent unit lies a complex network of weights and activation functions. These internal mechanisms process the current input in conjunction with the hidden state from the previous time step, producing a new hidden state and an output. The specifics of these mechanisms can vary depending on the type of recurrent unit used (e.g., Basic RNN, LSTM, GRU).
Beyond recurrent units, RNNs may incorporate other components to enhance their capabilities. In more advanced RNN variants like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), gating mechanisms control the flow of information within the recurrent unit. They selectively allow or block information from the previous hidden state, mitigating issues like vanishing gradients that can hinder learning in basic RNNs.
Some RNNs may include attention mechanisms that enable them to focus on specific parts of the input sequence when making predictions or generating outputs, which is useful in tasks like machine translation, where different parts of the input sentence may be more relevant to varying points in the translation process.
To better visualize how an RNN processes sequential data, it's helpful to 'unfold' it across time. Imagine each time step as a separate layer in the network, with the hidden state being passed from one layer to the next.
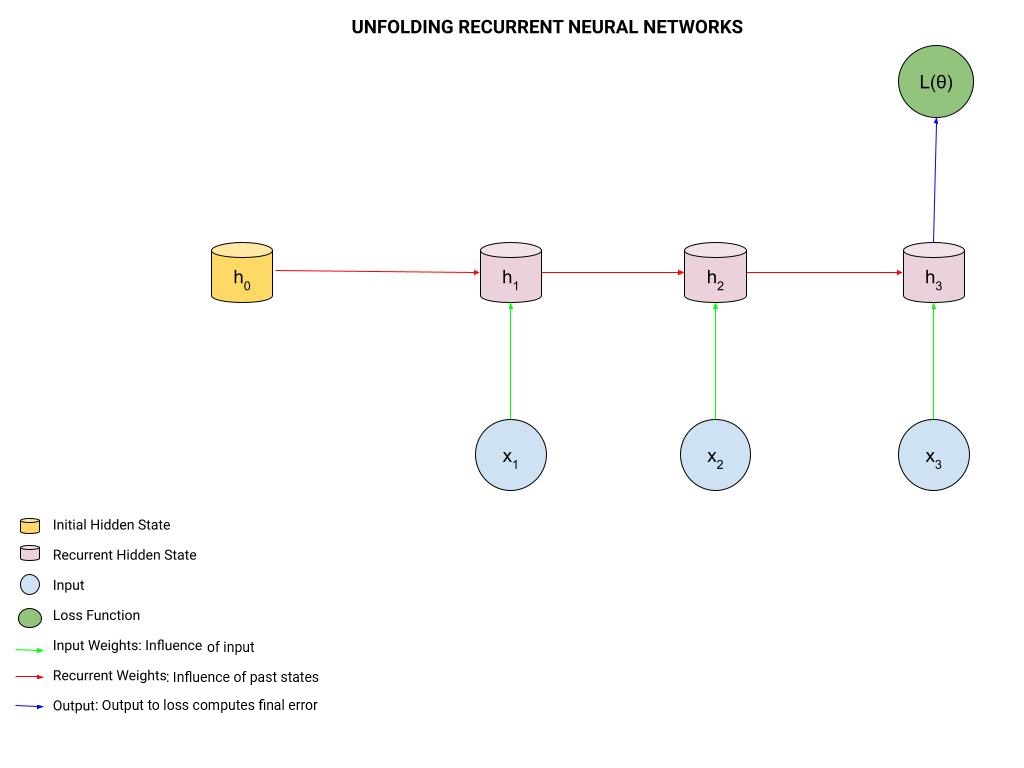
This unfolded representation reveals the recurrent nature of the network and how information flows through it over time.
These specialized components help RNNs model complex temporal dependencies and generate meaningful outputs from sequential data. While RNNs' basic structure may seem simple, the intricacies of these components contribute to their remarkable capabilities in a wide range of applications.
Note: For a detailed explanation of the basic layers in a neural network, read What is a Neural Network?
In the next section, we will explore the mathematical representation of RNNs and how these components interact to process sequential data.
Mathematical representation of recurrent neural networks
RNNs use the recurrent unit's update rule, which governs how the hidden state evolves at each time step. Let's break down this rule:
- Hidden State Update: The hidden state at time step 't', denoted as ht, is computed using the current input xt and the hidden state from the previous time step h(t-1), which can be expressed as:
ht = f(Wxh * xt + Whh * h(t-1) + bh)
Where:
- f is the activation function (e.g., tanh, ReLU)
- Wxh are the weights connecting the input to the hidden layer
- Whh are the recurrent weights connecting the hidden layer to itself
- bh is the bias term for the hidden layer
- Output Calculation: The output at time step 't', denoted as yt is computed using the current hidden state ht, which can be expressed as:
yt = g(Why * ht + by)1
where:
- g is the activation function for the output layer (often softmax for classification tasks)
- Why are the weights connecting the hidden layer to the output layer
- by is the bias term for the output layer
To visualize the flow of information through time, consider the unrolled representation of an RNN. Each time step is depicted as a separate layer, with the hidden state being passed from one layer to the next.
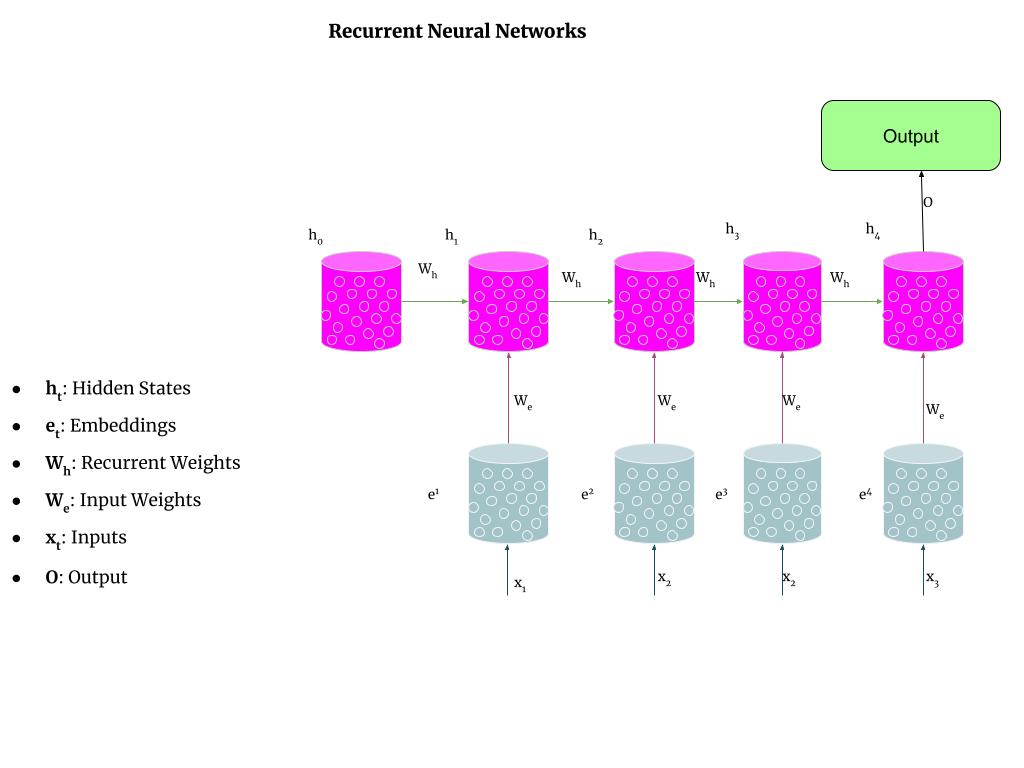
This reveals a chain-like structure in which computations at each step depend on both the current input and the accumulated context from previous steps.
Moreover, RNNs can learn the optimal values for the weight matrices and bias terms through a process called backpropagation through time (BPTT). BPTT adapts traditional backpropagation to accommodate the recurrent connections, allowing the network to adjust its parameters to minimize the error between its predicted outputs and the true labels in the training data.
For instance, if an RNN is used to predict the next word in a sentence, as it processes each word, the RNN updates its hidden states using weight matrices. Through BPTT, the network learns by adjusting these weights based on the errors in its predictions—like predicting “apple” when it should be “banana.” BPTT backtracks through the sequence, correcting the weights to improve future predictions by minimizing these errors.
Having learned the mathematics behind RNNs, let’s explore a simple RNN project to see the logic programmatically.
Code logic of RNNs
We created a simple RNN model for translating English sentences to French. Let's break down how it embodies the core RNN principles we've discussed:
- Data Preparation:
The code starts by loading sample English-French sentence pairs and tokenizing them. Tokenization converts words into numerical representations (indices) that the model can understand.
# Sample data: English to French sentence pairs`
data = {
'english': ['hello', 'how are you', 'good morning', 'thank you', 'good night'],
'french': ['bonjour', 'comment ça va', 'bonjour', 'merci', 'bonne nuit']
}
# Create a DataFrame
df = pd.DataFrame(data)
# Tokenize the English and French sentences
english_tokenizer = Tokenizer()
french_tokenizer = Tokenizer()
Padding ensures that all sequences have the same length, which is necessary for batch processing in neural networks.
# Pad the sequences to ensure uniform length
english_padded = pad_sequences(english_sequences, padding='post')
french_padded = pad_sequences(french_sequences, padding='post')
- Model Architecture:
An Embedding layer is used to convert token indices into dense vectors, capturing semantic relationships between words. The SimpleRNN layer processes the input sequence one word at a time, maintaining an internal hidden state that carries information from previous words.
# Define the RNN model architecture
model = Sequential()
model.add(Embedding(input_dim=english_vocab_size, output_dim=64))
# Removed input_length as it's deprecated
model.add(SimpleRNN(128, return_sequences=True)) # Output sequences to match target shape
model.add(Dense(french_vocab_size, activation='softmax'))
The Dense layer with softmax activation produces probabilities for each French word in the vocabulary, allowing the model to predict the most likely translation for each English word.
- Training:
The model is compiled with the 'adam' optimizer and 'sparse_categorical_crossentropy' loss, suitable for sequence-to-sequence tasks.
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Display the model summar
model.summary()
During training, the model iteratively adjusts its weights to minimize the difference between its predicted French translations and the actual French translations in the training data.
- Inference:
The translate function takes an English sentence, tokenizes and pads it, and feeds it to the trained model.
# Define a function to translate English text to French using the trained model
def translate(sentence):
sequence = english_tokenizer.texts_to_sequences([sentence])
padded_sequence = pad_sequences(sequence, maxlen=english_padded.shape[1], padding='post')
prediction = model.predict(padded_sequence)
predicted_sentence = ' '.join(
french_tokenizer.index_word.get(idx, '') for idx in np.argmax(prediction, axis=-1)[0] if idx
!= 0
)
return predicted_sentence
The model predicts the French translation and the translate function converts the predicted token indices back into French words.
Key RNN concepts used:
- Sequential Processing: The SimpleRNN layer processes the input sequence word by word, demonstrating the sequential nature of RNNs.
- Hidden State: The internal state of the SimpleRNN layer acts as the model's memory, allowing it to consider the context of previous words when predicting the next French word.
- Learning from Data: The training process exemplifies how RNNs learn from data, adjusting their internal parameters to improve their translation capabilities.
While this is a simplified example, it effectively demonstrates the core principles of RNNs in a practical application. More complex RNN architectures, such as LSTMs and GRUs, build upon these foundations to tackle more challenging sequence-to-sequence tasks.
This is the entire code below:
# Import necessary libraries
import numpy as np
import pandas as pd
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense
# Sample data: English to French sentence pairs
data = {
'english': ['hello', 'how are you', 'good morning', 'thank you', 'good night'],
'french': ['bonjour', 'comment ça va', 'bonjour', 'merci', 'bonne nuit']
}
# Create a DataFrame
df = pd.DataFrame(data)
# Tokenize the English and French sentences
english_tokenizer = Tokenizer()
french_tokenizer = Tokenizer()
english_tokenizer.fit_on_texts(df['english'])
french_tokenizer.fit_on_texts(df['french'])
# Convert text to sequences
english_sequences = english_tokenizer.texts_to_sequences(df['english'])
french_sequences = french_tokenizer.texts_to_sequences(df['french'])
# Pad the sequences to ensure uniform length
english_padded = pad_sequences(english_sequences, padding='post')
french_padded = pad_sequences(french_sequences, padding='post')
# Define vocabulary sizes
english_vocab_size = len(english_tokenizer.word_index) + 1
french_vocab_size = len(french_tokenizer.word_index) + 1
# Define the RNN model architecture
model = Sequential()
model.add(Embedding(input_dim=english_vocab_size, output_dim=64)) # Removed input_length as
it's deprecated
model.add(SimpleRNN(128, return_sequences=True)) # Output sequences to match target shape
model.add(Dense(french_vocab_size, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Display the model summary
model.summary()
# Train the model with the correct target shape
model.fit(english_padded, french_padded, epochs=100, verbose=2)
# Define a function to translate English text to French using the trained model
def translate(sentence):
sequence = english_tokenizer.texts_to_sequences([sentence])
padded_sequence = pad_sequences(sequence, maxlen=english_padded.shape[1], padding='post')
prediction = model.predict(padded_sequence)
predicted_sentence = ' '.join(
french_tokenizer.index_word.get(idx, '') for idx in np.argmax(prediction, axis=-1)[0] if idx
!= 0
)
return predicted_sentence
# Example translation
print(translate('hello'))
With this practical illustration in mind, let's explore the different types of recurrent neural networks.
Types of recurrent neural networks
Recurrent Neural Networks (RNNs) come in various types, each designed to address specific challenges associated with sequential data processing and to improve performance in different applications. Here are some of the most common types of RNNs:
- Basic RNNs: These are the simplest form of RNNs where each neuron’s output is connected back to itself, allowing information to persist across time steps. However, basic RNNs often struggle with learning long-term dependencies due to issues like vanishing and exploding gradients.
- Long Short-Term Memory Networks (LSTMs): LSTMs are an advanced type of RNN designed to handle the vanishing gradient problem by using a more complex architecture with gating mechanisms. LSTMs have a cell state, input gate, forget gate, and output gate, allowing them to retain information over long sequences and selectively forget or update information, making them highly effective for tasks that require long-term memory.
- Gated Recurrent Units (GRUs): GRUs are a simplified version of LSTMs that merge the forget and input gates into a single update gate and have fewer parameters. GRUs are computationally more efficient than LSTMs while still handling the problem of long-term dependencies effectively, making them popular for real-time applications.
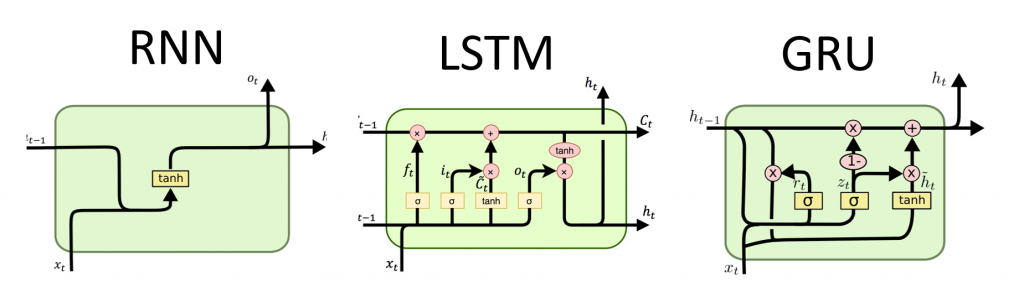 Source: dProgrammer Lopez
Source: dProgrammer Lopez
- Bidirectional RNNs: These RNNs process data in both forward and backward directions, capturing information from both past and future contexts simultaneously. Bidirectional RNNs are particularly useful in tasks like language processing, where understanding the full context of a sequence is essential.
- Echo State Networks (ESNs): These are a type of RNN that uses a sparsely connected reservoir of neurons with fixed weights, and only the output weights are trained. ESNs are designed to be efficient and work well for temporal pattern recognition tasks.
- Neural Turing Machines (NTMs) and Differentiable Neural Computers (DNCs): These advanced architectures combine RNNs with external memory components, allowing them to read from and write to memory, effectively enabling them to learn complex algorithms and solve problems that involve long-term sequential dependencies.
These different types of RNNs are tailored to specific use cases, addressing limitations of basic RNNs and enhancing the ability of neural networks to manage sequential data efficiently.
Applications of RNNs
There are numerous applications of Recurrent Neural Networks. Here are some of the most prominent applications of RNNs:
Natural Language Processing (NLP)
RNNs are used in NLP tasks such as language modeling, machine translation, and text generation. They are adept at processing sequential text data, allowing them to understand context and produce coherent outputs.
Speech Recognition
In speech recognition, RNNs help model sequences of audio data, enabling the conversion of spoken language into text. The recurrent structure allows the network to maintain context, which is important for accurately transcribing spoken words.
Time Series Prediction
RNNs are widely used in time series forecasting, such as stock price prediction, weather forecasting, and energy consumption analysis. Their ability to learn from past data points and predict future trends makes them invaluable.
Other Applications
- Image Captioning: RNNs can generate descriptive captions for images by processing visual features extracted by CNNs.
- Anomaly Detection: RNNs can monitor sequences for irregular patterns, making them useful in fraud detection and network security.
Conclusion
Recurrent Neural Networks have played a transformative role in sequence modeling, enabling advancements in language processing, speech recognition, and time series forecasting. RNNs remain an important tool in deep learning, particularly when combined with other innovations.
Understanding their workings provides a solid foundation for using them in various applications. Stay updated with our docs and resources, try different recurrent neural network architectures, and contact us to get access to the latest NVIDIA GPUs at low rates.
