 Resources
Resources 
Choosing the optimal GPU for deep learning and high-performance computing requires careful consideration of performance, efficiency, and cost. The NVIDIA RTX A5000 offers a compelling option for a wide range of use cases, but it is crucial to understand its strengths and best uses.
Built on the NVIDIA Ampere architecture, which provides significant performance improvements over previous generations, it is a powerful tool for designers, engineers, artists, and researchers. Unlike newer Hopper GPUs built specifically for Artificial Intelligence (AI), the A5000 is well-suited to a variety of HPC workloads.
In this article, we'll provide a detailed breakdown of the RTX A5000's specifications, benchmark performance, and value proposition.
NVIDIA A5000 specification
The NVIDIA RTX A5000 is built on the GA102 GPU, an NVIDIA's Ampere architecture component. The GA102 GPU in the A5000 is manufactured using an 8 nm process, packing a staggering 28.3 billion transistors into a die size of 628 mm². The density enables massive parallel processing in a relatively compact package.
While we've previously explored the general architecture of GPUs and the specifics of the Ampere GA10x family, this section will focus on the unique specifications and capabilities of the A5000.
The A5000 has 64 Streaming Multiprocessors (SMs), each containing 128 CUDA cores totaling 8,192 CUDA cores. These CUDA cores are the workhorses of the GPU, responsible for executing the vast majority of computations involved in graphics rendering, AI acceleration, and general-purpose computing tasks.
 Source: NVIDIA
Source: NVIDIA
What is the NVIDIA RTX A5000 used for?
The NVIDIA RTX A5000 is a powerful professional graphics card designed for demanding workloads such as 3D rendering, video editing, visual effects, and AI-powered applications. It is also used in scientific visualization, data science, and virtual reality environments.
The A5000 has 256 Tensor cores specifically designed to accelerate deep learning by doing the following:
- Handling multiple data points simultaneously, which is crucial for matrix multiplications (used in neural networks), allowing the GPU to process large volumes of data in parallel and significantly speeding up training and inference tasks.
- Supporting mixed-precision computing, where operations use a combination of high and low-precision calculations, helps maintain high accuracy while boosting performance and reducing the memory footprint, leading to faster computations and lower power consumption.
Tensor cores are optimized for throughput, meaning they can perform a high number of operations per second, which helps for deep learning training, where vast amounts of data need to be processed rapidly to adjust weights and biases in the neural networks.
Additionally, the GPU includes 64 RT cores dedicated to accelerating real-time ray tracing, which simulates the physical behavior of light to produce high-quality visual effects in 3D graphics. Here’s how they enhance efficiency:
- Ray-Tracing Acceleration: RT cores are designed to quickly compute the intersections of light rays with objects in the scene. This reduces the computational load on the CUDA cores, allowing for more complex scenes to be rendered in real-time without compromising on frame rates or visual fidelity.
- Efficient Light Simulation: By offloading the intensive calculations required for realistic lighting, shadows, and reflections to the RT cores, the GPU can handle more sophisticated visual effects better.
The NVIDIA A5000 also features 24GB of GDDR6 memory, ensuring smooth operation. Its memory capacity allows it to hold large datasets without frequent data swapping, which can slow down operations when working on AI projects.
In 3D rendering and simulations, having a large memory buffer means that detailed textures, models, and scenes can be loaded entirely into the GPU memory, reducing the need for constant data transfer from the system memory, thus speeding up the rendering process.
The memory is connected to the GPU via a 384-bit interface. This wide memory bus facilitates the transfer of large amounts of data between the memory and the GPU cores with a memory bandwidth of 768 GB/s.
This high bandwidth supports the smooth handling of real-time data processing, complex simulations, and extensive computational tasks.
| Specification | Details |
|---|---|
| GPU memory | 24GB GDDR6 |
| Memory interface | 384-bit |
| Memory bandwidth | 768 GB/s |
| Error-correcting code (ECC) | Yes |
| NVIDIA Ampere architecture-based CUDA Cores | 8,192 |
| NVIDIA third-generation Tensor Cores | 256 |
| NVIDIA second-generation RT Cores | 64 |
| Single-precision performance | 27.8 TFLOPS |
| RT Core performance | 54.2 TFLOPS |
| Tensor performance | 222.2 TFLOPS |
| NVIDIA NVLink | Low profile bridges connect two NVIDIA RTX A5000 GPUs |
| NVIDIA NVLink bandwidth | 112.5 GB/s (bidirectional) |
| System interface | PCIe 4.0 x16 |
| Power consumption | Total board power: 230 W |
| Thermal solution | Active |
| Form factor | 4.4” H x 10.5” L, dual slot, full height |
| Display connectors | 4x DisplayPort 1.4a |
| Max simultaneous displays | 4x 4096 x 2160 @ 120 Hz, 4x 5120 x 2880 @ 60 Hz, 2x 7680 x 4320 @ 60 Hz |
| Power connector | 1x 8-pin PCIe |
| Encode/decode engines | 1x encode, 2x decode (AV1 decode) |
| VR ready | Yes |
| vGPU software support | NVIDIA vPC/vApps, NVIDIA RTX Virtual Workstation |
| vGPU profiles supported | See the Virtual GPU Licensing Guide |
| Graphics APIs | DirectX 12 Ultimate, Shader Model 6.5, OpenGL 4.6, Vulkan 1.3 |
| Compute APIs | CUDA 11.6, DirectCompute, OpenCL 3.0 |
These features make the NVIDIA RTX A5000 efficient in handling demanding computational tasks. Now, let’s discuss its performance metrics.
A5000 performance analysis
The NVIDIA A5000 can be used for various applications, but we will focus on its performance in deep learning tasks in this article. In this study by Exxact, a deep-learning server was outfitted with 8 A5000 GPUs and benchmarked using the tf_cnn_benchmarks.py benchmark script found in the official TensorFlow GitHub.
The GPUs were tested on the ResNet50, ResNet152, Inception v3, and Googlenet networks, with the test being done using 1, 2, 4, and 8 GPU configurations with a batch size of 128 for FP32 and 256 for FP16.
The NVIDIA RTX A5000 demonstrates impressive performance across various neural networks and precision levels, as shown in the table below.
| Neural Network | Precision | 1 GPU | 2 GPUs | 4 GPUs | 8 GPUs |
|---|---|---|---|---|---|
| ResNet50 | FP16 | 1029.62 | 2059.24 | 4118.48 | 7585.89 |
| FP32 | 514.81 | 1029.62 | 2059.24 | 4118.48 | |
| ResNet152 | FP16 | 514.81 | 1029.62 | 2059.24 | 4118.48 |
| FP32 | 257.41 | 514.81 | 1029.62 | 2059.24 | |
| Inception v3 | FP16 | 384.62 | 769.24 | 1538.48 | 3076.96 |
| FP32 | 192.31 | 384.62 | 769.24 | 1538.48 | |
| GoogLeNet | FP16 | 257.41 | 514.81 | 1029.62 | 2059.24 |
| FP32 | 128.71 | 257.41 | 514.81 | 1029.62 |
Note: The numbers in the table represent throughput in images per second. Higher values indicate faster performance.
The performance of the A5000 varies depending on the complexity of the neural network architecture. More complex models, like ResNet50 and ResNet152, have more layers and parameters, requiring more computations and leading to lower throughput than simpler models like GoogLeNet. In simpler models, data can flow through the network faster, resulting in higher performance.
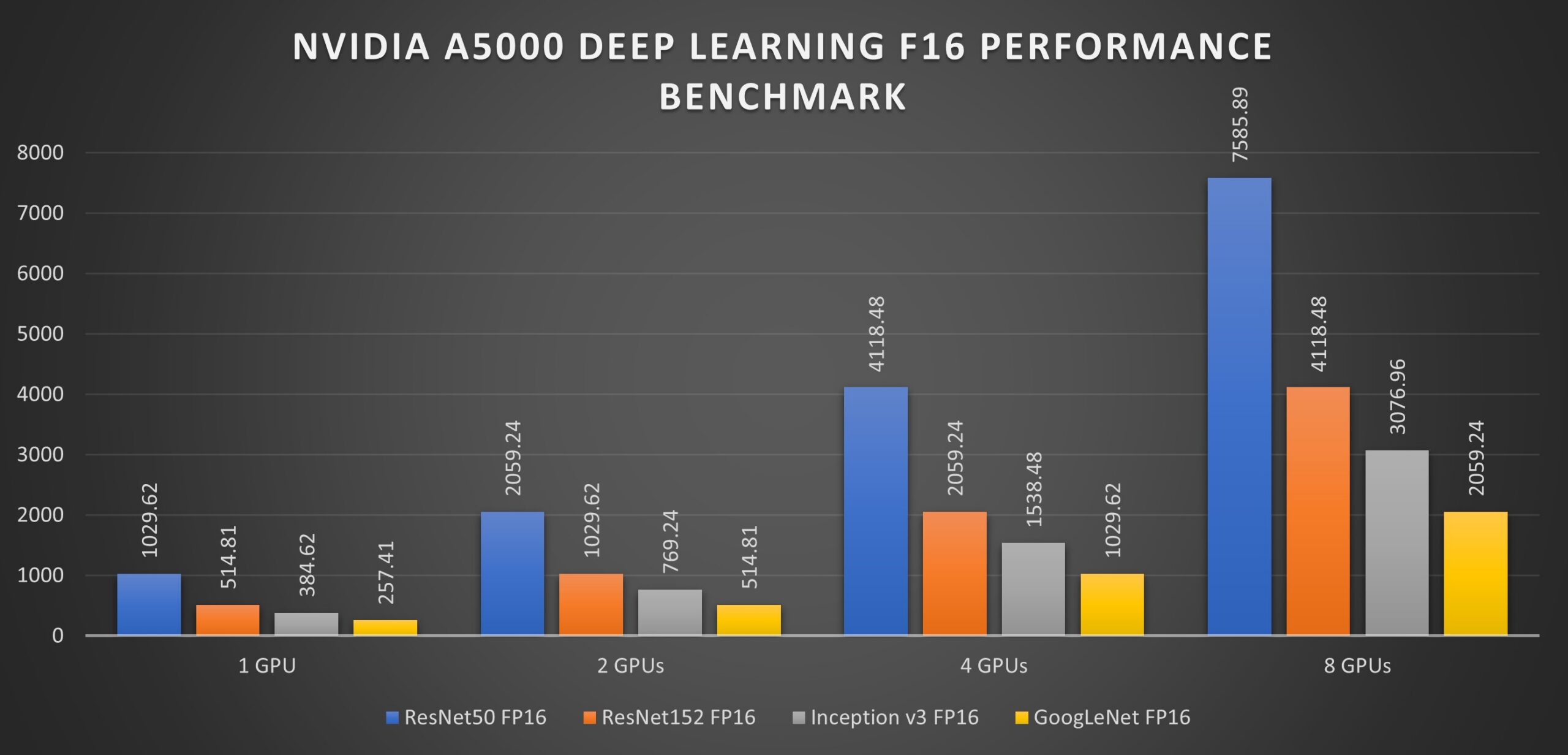
The A5000 exhibits near-linear scaling in performance as the number of GPUs increases. Adding more GPUs to your system generally results in a proportional increase in throughput, allowing you to train and process data sets much faster.
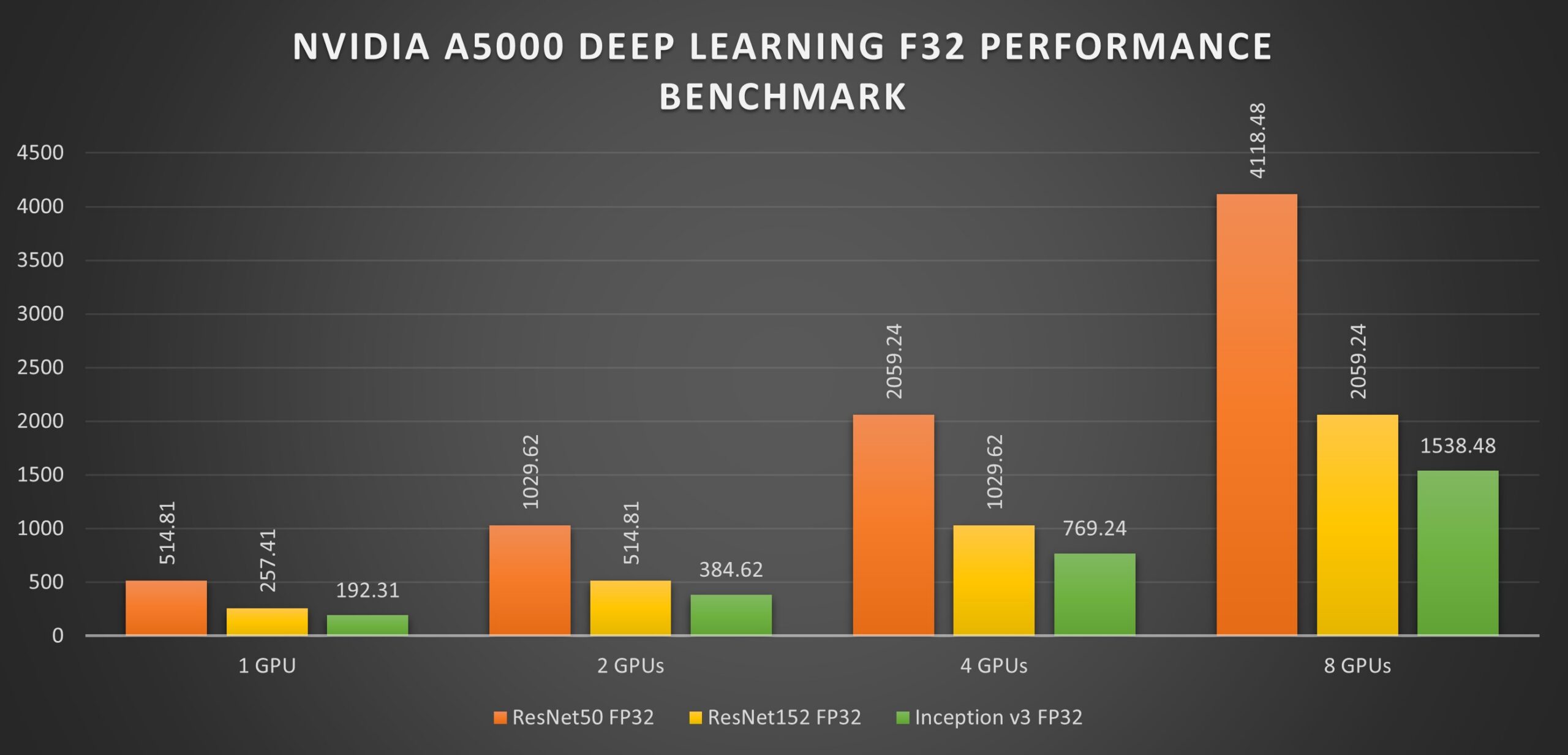
However, it's important to note that scaling isn't perfectly linear. There are diminishing returns as you add more GPUs to a system. Communication overhead and memory bandwidth limitations can become bottlenecks that hinder the ability of additional GPUs to contribute fully to the workload. Therefore, the ideal number of GPUs will depend on the specific workload and the balance between cost and performance.
Pricing
The NVIDIA A5000’s prices can vary depending on the retailer and region. However, due to its capable but more modest performance relative to newer processors, it offers good value for professionals seeking top-tier but more affordable performance.
Also, availability can be challenging due to high demand and global GPU shortage issues. It's advisable to check multiple retailers and sign up for notifications to stay informed about stock status.
You can access the NVIDIA RTX A5000 on demand at the lowest rates globally on CUDO Compute.
Here's a breakdown of CUDO Compute's pricing for NVIDIA A5000 GPUs. At the time of writing, pricing starts at:
$0.44 per hour
$321.42 per month
This makes the A5000 a more cost-efficient option for different applications. Get started now. Or Contact us to find out more about the pricing and configurations.
Is RTX A5000 good for deep learning?
The RTX A5000 excels at deep learning tasks due to its ample memory, tensor cores, and support for CUDA, a parallel computing platform. This makes it ideal for training and deploying complex deep learning models efficiently.
Other use cases and applications of the NVIDIA A5000
Other use cases where the A5000 can be applied include:

- Gaming: Gamers will easily appreciate the A5000's ability to handle 4K resolution, providing smooth gameplay and enhanced visuals through ray tracing. Games like Call of Duty and Battlefield V run exceptionally well, even at maximum settings. The A5000's support for DLSS technology further enhances gaming performance by using AI to upscale lower resolutions to 4K, providing better frame rates without compromising image quality.
- Professional applications: In architecture, engineering, and media production, the A5000's high memory capacity and processing power enable faster rendering and more complex simulations. Software such as Blender, SolidWorks, and DaVinci Resolve see marked performance improvements. The A5000's ability to handle large datasets and complex models makes it an invaluable tool for professionals working on high-resolution video editing, 3D rendering, and scientific simulations.
- VR and AR: The A5000's capabilities extend to virtual and augmented reality, providing the necessary power to run these applications smoothly. This is crucial for developers working on immersive experiences and simulations. The GPU's high frame rates and low latency ensure a seamless VR and AR experience, enhancing the realism and interactivity of these applications. The A5000's performance in VR and AR also makes it suitable for training simulations, medical applications, and virtual prototyping.
Follow our blog for in-depth analyses, comparisons, and performance insights on GPUs and CPUs that can accelerate your work.
