 Resources
Resources 
Machine learning has various learning approaches, each offering unique advantages and addressing different challenges. The three main types are supervised learning, unsupervised learning, and the often-overlooked semi-supervised learning (SSL). While supervised and unsupervised learning are well-known, SSL is a valuable bridge between the two, offering unique benefits.
As stated previously, machine learning thrives on data, but labeled data is costly and time-consuming to create, while unlabeled data is plentiful but needs more specific guidance for models.
SSL combines these resources using a small set of labeled data and a large volume of unlabeled data, often making it a highly accurate approach in various fields. In this article, we will provide a comprehensive introduction to semi-supervised learning, exploring its concepts, algorithms, applications, advantages, and challenges.
CUDO Compute provides the scalable and cost-effective computing resources you need to train and deploy your SSL models. With CUDO Compute, you can access a global network of powerful GPU to accelerate your SSL training and inference. Get started today!
Traditional learning approaches in machine learning
To understand the role of SSL, let’s first examine how it compares to traditional learning methods:
- Supervised Learning: In supervised learning, models are trained using labeled data. A model learns from labeled inputs associated with a correct output, such as “cat” or “dog” in an image classification task. While this approach is highly accurate, it heavily depends on labeled data, making it costly in large-scale projects.
Read more about supervised learning here: Introduction to supervised learning.
- Unsupervised Learning: Unsupervised learning works with only unlabeled data, identifying patterns and relationships without predefined categories. It’s useful for tasks like clustering and anomaly detection but lacks the task-specific guidance of labeled data.
Read more about unsupervised learning here: Introduction to unsupervised learning.
SSL serves as a midpoint between these approaches, combining the labeled data required for task specificity with the abundance of unlabeled data to reduce costs and improve learning.
What is semi-supervised learning?
Semi-supervised learning (SSL) is a machine learning approach where a model is trained on a combination of labeled and unlabeled data. The primary goal is to use the unlabeled data to compensate for the small labeled dataset, enhancing the model’s generalization capabilities without incurring high labeling costs.
In practice, SSL uses a small, labeled dataset to kick-start the learning process. The model then uses its predictions on the unlabeled data to refine its learning, allowing SSL to achieve near-supervised performance levels with a fraction of the labeled data required by traditional supervised learning models.
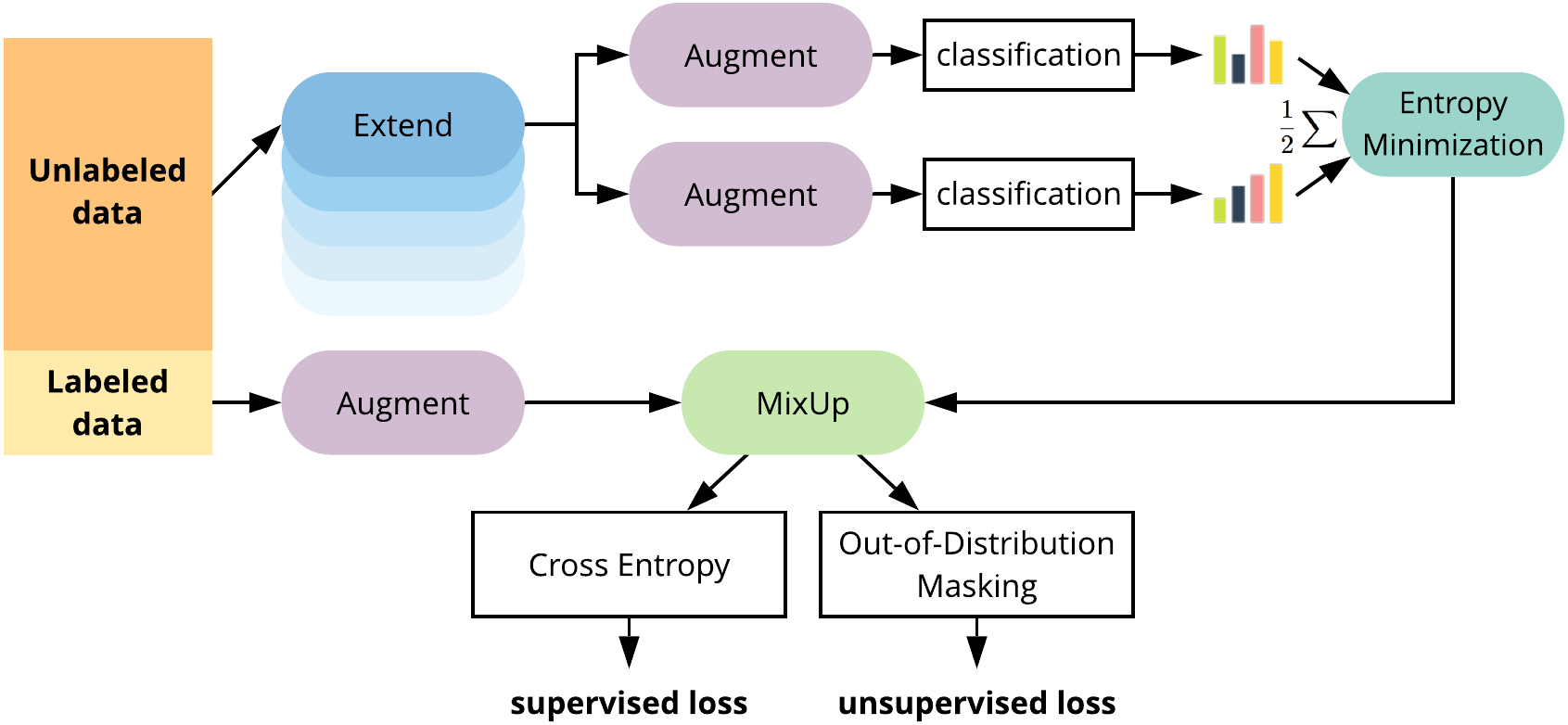
Source: Paper
For instance, imagine a scenario where you want to train a machine to recognize objects in images—such as identifying dogs, trees, and cars. With only a small set of labeled images (images where each object has been identified and tagged) but a vast collection of unlabeled images, SSL can use both to create a robust model, requiring less manual intervention while achieving high accuracy.
Semi-supervised learning works best when labeled and unlabeled data are similar, sharing common structures or distributions. By allowing models to learn from these similarities, SSL often produces results that closely match those of fully supervised models but with significantly reduced labeling requirements.
This unique approach has opened doors to more accessible and scalable machine learning solutions.
Applications of semi-supervised learning across industries
SSL has found applications across various industries. Some notable examples include:
- Healthcare: Medical imaging for disease diagnosis often uses SSL, as acquiring labeled images can be costly and requires expert knowledge. SSL models can utilize a small set of labeled scans alongside thousands of unlabeled scans to detect patterns in X-rays or MRIs, improving diagnostic accuracy.
- Natural Language Processing (NLP): In sentiment analysis, SSL can classify reviews, social media posts, or customer feedback with minimal labeled data, efficiently capturing the general sentiment using unlabeled data.
- Computer Vision: SSL assists in object detection, face recognition, and other computer vision tasks by using unlabeled images, reducing the extensive labeling typically required.
- Autonomous Vehicles: Autonomous driving systems use SSL to identify pedestrians, road signs, and vehicles with minimal labeled data, allowing manufacturers to train models without exhaustive manual labeling efforts.
These applications demonstrate SSL’s versatility, making it a critical component in fields where labeled data is scarce or expensive
Key techniques of semi-supervised learning
Several techniques enable SSL to make the most of labeled and unlabeled data. Let’s explore some of the most common SSL methods:
Self-Training
Self-training is a semi-supervised learning technique where a model is first trained on an initial labeled dataset. Once it reaches a specified accuracy or confidence level, it starts labeling its own predictions on the unlabeled data, effectively creating more training data to refine and improve itself over multiple iterations.
While conceptually straightforward, this method requires careful oversight to prevent the propagation of errors—if the model makes mistakes on the unlabeled data, these errors can reinforce themselves as the model continues to train on its self-generated labels.
Co-Training
Co-training is a semi-supervised learning method where two or more models are trained on different, often complementary, subsets of features or “views” of the same dataset. Co-training relies on the idea that separate models can learn distinct information about the data, effectively cross-validating each other’s predictions and providing pseudo-labels for additional training iterations.
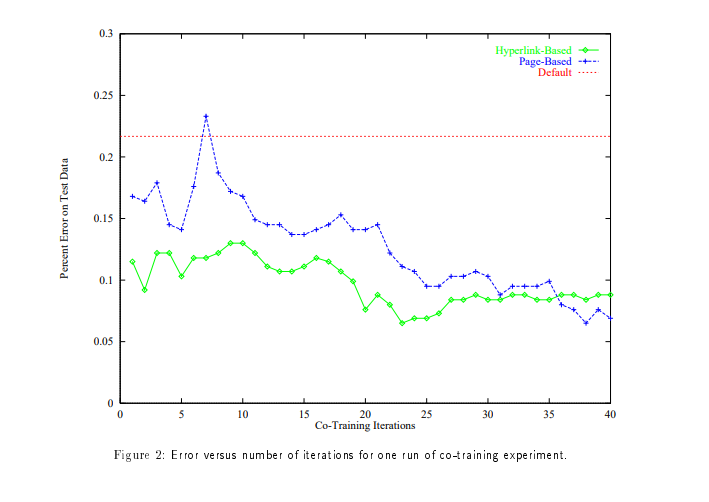
Source: Paper
Co-training is useful for tasks where data can be naturally divided into multiple feature sets (e.g., text and images in multimodal learning or different sensor inputs in robotics). By learning from independent perspectives, each model helps the other avoid overfitting, improving overall accuracy and robustness.
Graph-Based Methods
Graph-based methods in semi-supervised learning represent data points as nodes within a graph structure. Edges between these nodes indicate the similarity or connection strength between them. This approach uses the graph to capture relationships between labeled and unlabeled data points, enabling a process called “label propagation.” Essentially, known labels from labeled nodes are spread to their nearby unlabeled neighbors.
The fundamental assumption in this technique is that similar or neighboring data points within the graph likely share the same or similar labels, making graph-based methods well-suited for data with clearly defined relationships.
Examples include social networks, where users are connected based on interactions, or image datasets, where clusters of nodes represent similar visual features. The model can effectively learn from labeled and unlabeled data to improve accuracy by propagating labels through these connections.
Generative Models
Generative models, including Generative Adversarial Networks (GANs), are used to model the underlying distribution of data and can generate new, realistic data points. In semi-supervised learning (SSL), generative models contribute by directly generating labeled samples or incorporating an auxiliary classifier to help distinguish between real and generated data, thus enhancing the primary model’s robustness when labeled data is scarce.
Read more about generative adversarial networks here: Neural networks: Introduction to generative adversarial networks.
Consistency Regularization
Consistency regularization is a semi-supervised learning technique that makes model predictions stable and consistent when minor perturbations are applied to the input data. The core idea is that small changes, like adding noise or slight transformations, should not lead to significant differences in the model’s output. This approach encourages the model to learn robust features and generalize better across varied but similar data.
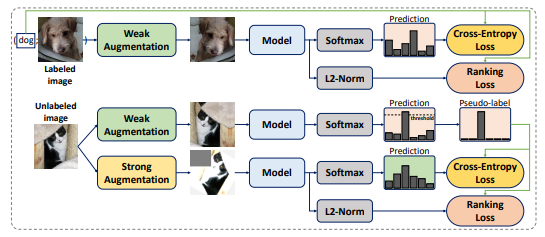
Source: Paper
The model is given slightly modified versions of the same input and trained to produce consistent predictions across these modified inputs. By focusing on consistent outputs for similar inputs, the model becomes less sensitive to variations in the data, leading to better generalization.
Consistency regularization allows models to use large amounts of unlabeled data. Since minor variations should not change the fundamental meaning or classification of the data, the model uses the structural patterns within the unlabeled data to refine its predictions without explicit labeling.
Each technique uses unlabeled data to improve model performance, capitalizing on patterns within the data to refine predictions without relying solely on manual labeling. Now, let’s discuss how it works.
How Semi-Supervised Learning Works
Let’s see semi-supervised learning in action with a practical example. Imagine you’re a retail store manager wanting to identify “high-value” customers using data on their age and monthly spending. You have some labeled data, but labeling every customer is impractical.
By combining your limited labeled data with a larger set of unlabeled customer information, you can train a model to predict which unlabeled customers are likely to be high-value. We’ll use Python code to simulate this scenario and demonstrate how to train a model, make predictions, and iteratively refine its accuracy using both labeled and unlabeled data.
Step 1: Gather Labeled and Unlabeled Data
Imagine you’re a retail store trying to identify your “high-value” customers. You have some data on customer age and monthly spending, and you’ve labeled a small portion of your customers as high-value or not. However, you have a much larger set of customer data without labels.
import numpy as np
# Simulate customer data for a retail store (labeled and unlabeled)
np.random.seed(0)
labeled_data = np.random.rand(20, 2) # 20 samples, 2 features (e.g., age and monthly spending)
labeled_labels = (labeled_data[:, 0] * 30 + labeled_data[:, 1] * 1000 > 500).astype(int) # Binary labels: 1 if high-value customer, 0 otherwise
unlabeled_data = np.random.rand(80, 2) # 80 samples, 2 features (age and monthly spending)
In this code, we simulate some customer data. labeled_data represents the 20 customers with known labels (labeled_labels), while unlabeled_data represents the 80 customers without labels.
Step 2: Train an Initial Model with Labeled Data
Now, let’s train a simple classifier using our labeled data:
# Define a simple linear classifier
def train_classifier(data, labels):
# Here we use a very basic linear model: y = w1 * x1 + w2 * x2 + b
# Using normal equation to calculate weights (this is for demonstration, not optimal for real-world tasks)
X = np.c_[data, np.ones(data.shape[0])] # Add bias term
y = labels.reshape(-1, 1)
weights = np.linalg.pinv(X.T @ X) @ X.T @ y # Pseudo-inverse solution for linear regression
return weights
# Initial training on labeled data
weights = train_classifier(labeled_data, labeled_labels)
Here, we define a function train_classifier that creates a simple linear model and trains it on the labeled data to find the optimal weights.
Step 3: Make Predictions on Unlabeled Data
Using the trained model, we can predict labels for the unlabeled customers:
def predict(data, weights):
X = np.c_[data, np.ones(data.shape[0])] # Add bias term
linear_output = X @ weights
return (linear_output > 0.5).astype(int).flatten()
The predict function uses the trained model (weights) to predict labels for the unlabeled_data.
Step 4: Combine Labeled and Pseudo-Labeled Data
Now, we combine our labeled data with the unlabeled data and their predicted (pseudo) labels:
# Semi-supervised training loop
for iteration in range(10):
# Predict labels for the unlabeled data
pseudo_labels = predict(unlabeled_data, weights)
# Combine labeled data with newly pseudo-labeled data
combined_data = np.vstack((labeled_data, unlabeled_data))
combined_labels = np.hstack((labeled_labels, pseudo_labels))
Our code snippet shows how to combine the labeled_data and unlabeled_data with their corresponding labels (including the pseudo_labels) into combined_data and combined_labels.
Step 5: Train a New Model on the Combined Data
Finally, we retrain our classifier on the combined dataset:
# Re-train the classifier on the combined data
weights = train_classifier(combined_data, combined_labels)
# Print the updated weights for each iteration
print(f"Iteration {iteration + 1}: Weights: {weights.flatten()}")
# Final predictions
final_predictions = predict(unlabeled_data, weights)
print("Final pseudo-labels for unlabeled data:", final_predictions)
This code retrains the classifier using the combined_data and combined_labels, effectively utilizing both the original labeled data and the information learned from the unlabeled data. This process can be repeated for multiple iterations to refine the model further.
This example demonstrates a simplified version of semi-supervised learning. In real-world scenarios, more sophisticated algorithms and techniques are used to handle complexities like noisy data and ensure pseudo-labels’ quality. However, the fundamental principles remain the same: leverage unlabeled data to improve the performance of a model trained on limited labeled data.
Here is the entire code:
import numpy as np
# Simulate customer data for a retail store (labeled and unlabeled)
np.random.seed(0)
labeled_data = np.random.rand(20, 2) # 20 samples, 2 features (e.g., age and monthly spending)
labeled_labels = (labeled_data[:, 0] * 30 + labeled_data[:, 1] * 1000 > 500).astype(int) # Binary labels: 1 if high-value customer, 0 otherwise
unlabeled_data = np.random.rand(80, 2) # 80 samples, 2 features (age and monthly spending)
# Define a simple linear classifier
def train_classifier(data, labels):
# Here we use a very basic linear model: y = w1 * x1 + w2 * x2 + b
# Using normal equation to calculate weights (this is for demonstration, not optimal for real-world tasks)
X = np.c_[data, np.ones(data.shape[0])] # Add bias term
y = labels.reshape(-1, 1)
weights = np.linalg.pinv(X.T @ X) @ X.T @ y # Pseudo-inverse solution for linear regression
return weights
def predict(data, weights):
X = np.c_[data, np.ones(data.shape[0])] # Add bias term
linear_output = X @ weights
return (linear_output > 0.5).astype(int).flatten()
# Initial training on labeled data
weights = train_classifier(labeled_data, labeled_labels)
# Semi-supervised training loop
for iteration in range(10):
# Predict labels for the unlabeled data
pseudo_labels = predict(unlabeled_data, weights)
# Combine labeled data with newly pseudo-labeled data
combined_data = np.vstack((labeled_data, unlabeled_data))
combined_labels = np.hstack((labeled_labels, pseudo_labels))
# Re-train the classifier on the combined data
weights = train_classifier(combined_data, combined_labels)
# Print the updated weights for each iteration
print(f"Iteration {iteration + 1}: Weights: {weights.flatten()}")
# Final predictions
final_predictions = predict(unlabeled_data, weights)
print("Final pseudo-labels for unlabeled data:", final_predictions)
Benefits of Semi-Supervised Learning
Semi-supervised learning offers several advantages, especially in practical applications:
- Reduced Labeling Cost: Labeling data can be a significant expense in machine learning projects, often requiring human expertise or time-consuming manual annotation. SSL drastically reduces the labeled data needed, leading to substantial cost savings.
- Improved Model Accuracy: SSL allows models to learn more generalizable features and patterns, which often results in improved accuracy, sometimes even approaching the performance of fully supervised models trained on significantly larger labeled datasets.
- Adaptability Across Domains: SSL can be applied in various fields, such as medical imaging and NLP, where labeled data is difficult to acquire. For instance, SSL can enhance disease diagnosis models using limited expert-labeled data and vast amounts of unlabeled medical images, making healthcare more accessible and data-efficient.
Semi-supervised learning offers a practical and efficient way to overcome the limitations of relying solely on labeled data, opening up new possibilities for building high-performing machine learning models in various applications.
Challenges and limitations of semi-supervised learning
While semi-supervised learning offers compelling advantages, it’s essential to be aware of its potential challenges and limitations:
- Dependency on Data Quality: SSL assumes that the unlabeled data is relevant to the task and representative of the overall data distribution. The model may learn incorrect patterns if the unlabeled data contains significant noise, outliers, or irrelevant samples, leading to poor generalization and inaccurate predictions. Careful data preprocessing and selection of unlabeled data are crucial for successful SSL.
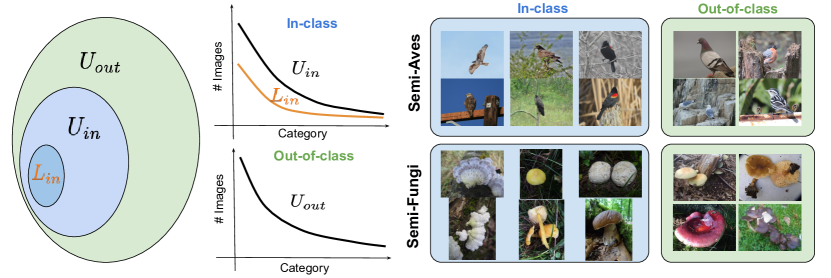
Source: Paper
- Model Complexity: Some SSL techniques, particularly graph-based methods, and co-training, can be computationally complex and require careful fine-tuning of hyperparameters to achieve optimal performance. This can increase the training time and require more computational resources than simpler supervised learning approaches.
- Scalability Issues: As the size of the dataset grows, the computational requirements of SSL, especially for graph-based models, can become a significant bottleneck. Building and processing large graphs can be memory-intensive and computationally expensive, making applying SSL to massive datasets challenging.
- Risk of Error Amplification: In SSL, errors in the initial labeling or the pseudo-labels generated by the model can propagate through the dataset during training, leading to a phenomenon called “error amplification,” where the model reinforces incorrect patterns and becomes increasingly biased. Addressing this requires careful quality control of pseudo-labels, using techniques like confidence thresholds or incorporating active learning to label uncertain instances selectively.
- Choosing the Right Algorithm: The success of SSL depends on selecting the appropriate algorithm for the specific task and data characteristics. Different SSL methods have different strengths and weaknesses, and choosing the wrong algorithm can lead to suboptimal performance.
Despite these limitations, semi-supervised learning remains a valuable and practical choice in many fields.
Conclusion
Semi-supervised learning is a valuable approach that bridges the gap between supervised and unsupervised learning. SSL offers cost-effective and highly accurate solutions across various fields using labeled and unlabeled data.
You can build your semi-supervised learning projects today using cost-effective cloud resources on CUDO Compute. CUDO Compute offers the best NVIDIA GPUs, like the NVIDIA H100 and H200, at affordable rates. Click here to get started, or contact us.
