 Resources
Resources 
Supervised learning is one of the earliest and most widely adopted forms of machine learning, with widespread applications due to its ability to use labeled data for predictive tasks. In this approach, the model learns from datasets where each data point includes a correct output or ‘label,’ guiding the model during training.
The term ‘supervised’ reflects that the algorithm receives these correct answers, allowing it to learn relationships between input features and outputs and generalize these patterns to make predictions on new, unseen data.
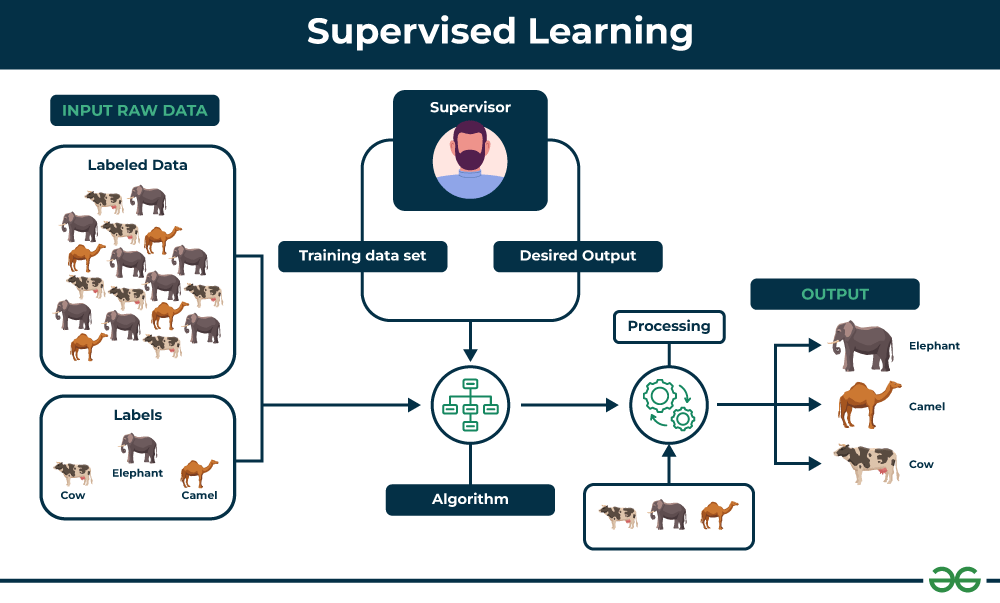
Source: Geek for geeks
Generalization is crucial; we want our model to accurately predict outcomes for data it hasn’t encountered before like a spam filter correctly identifying a new phishing email. To achieve this, techniques like cross-validation, where the data is split into training and testing sets, are used to evaluate the model’s performance on unseen data.
For easy scalability, you can build your supervised learning projects using the latest NVIDIA GPUs on CUDO Compute. Click here to get started.
In this article, we will explore the fundamentals of supervised learning and examine its most popular algorithms and applications. Let’s begin by discussing what supervised learning is.
What is supervised learning?
Supervised learning is essentially learning by example. Imagine a child learning to identify different fruits. They are shown an apple and told, “This is an apple.” They are shown a banana and told, “This is a banana.” By repeatedly observing examples and their corresponding labels, the child learns to distinguish between various fruits.
Similarly, in supervised learning, an algorithm is fed a dataset of labeled examples. Each example consists of:
- Features: These are the input variables that describe the data point. For the fruit example, features might include color, shape, and size.
- Label: This is the desired output or the “answer” associated with the input features. In our case, the label would be the name of the fruit (e.g., “apple,” “banana”).
These are some key components that enable supervised learning:
Key components in supervised learning:
- Input-Output Pairs: The input represents the features or attributes of the data points (e.g., size of the house, number of bedrooms, location), while the output is the label or target variable (e.g., the price of the house).
- Training Dataset: The dataset consists of input-output pairs where the relationship between inputs and outputs is already established, which is the core of the learning process.
- Model: The algorithm used to learn the mapping from input to output. These models can range from simple linear models to more complex decision trees or neural networks.
Supervised learning is named as such because the algorithm is essentially being “supervised” throughout the training process, relying on the correct answers provided by the labeled data. Without this supervision, the algorithm would have no guidance on the correct output.
There are different types of supervised learning algorithms. Let’s discuss them next.
Types of supervised learning algorithms
Supervised learning algorithms can be broadly categorized into classification and regression. Both involve learning from labeled data but serve different kinds of tasks. Let’s break them down:
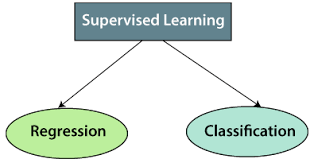
Source: Javatpoint
- Classification
Classification is a type of supervised learning that aims to predict a discrete label. These labels represent distinct categories, such as “spam” or “not spam” in an email classification task, or different classes like “cat,” “dog,” and “bird” in image classification.
In classification problems, the model is trained on labeled data, where each input corresponds to a specific label. After training, the model learns from this data and can assign new inputs to one of the predefined categories.
The key characteristic of classification is that the categories are predefined. For instance, in binary classification, there are only two possible outputs, while in multi-class classification, there can be more than two categories.
Some of the most common examples of classification include:
- Spam detection: Email services use supervised learning to classify incoming emails as “spam” or “not spam.”
- Image recognition: In image classification, the model is trained on labeled images and can classify new images into categories, such as identifying whether an image contains a dog, cat, or another object.
- Regression
In regression tasks, the goal is to predict a continuous variable that can be represented as an actual number, such as predicting house prices, stock market values, or temperatures. Unlike classification, where the output is a discrete category (like “dog” or “cat”), regression outputs are numerical and continuous.
For example, predicting the price of a house involves estimating a precise number rather than assigning it to a predefined category.
Regression is widely used in fields where modeling relationships between variables is necessary, such as economics, physics, and biology. Linear regression, for example, is one of the most commonly used algorithms for predicting continuous values based on input features.
Some examples of regression include:
- House Price Prediction: Given features like size, location, and number of bedrooms, the model predicts the price of the house.
- Stock Price Prediction: The model can predict future stock prices based on historical data.
Difference between classification and regression models
The distinction between classification and regression lies in the type of output the model predicts: classification is for categorical outputs, while regression is for continuous outputs.
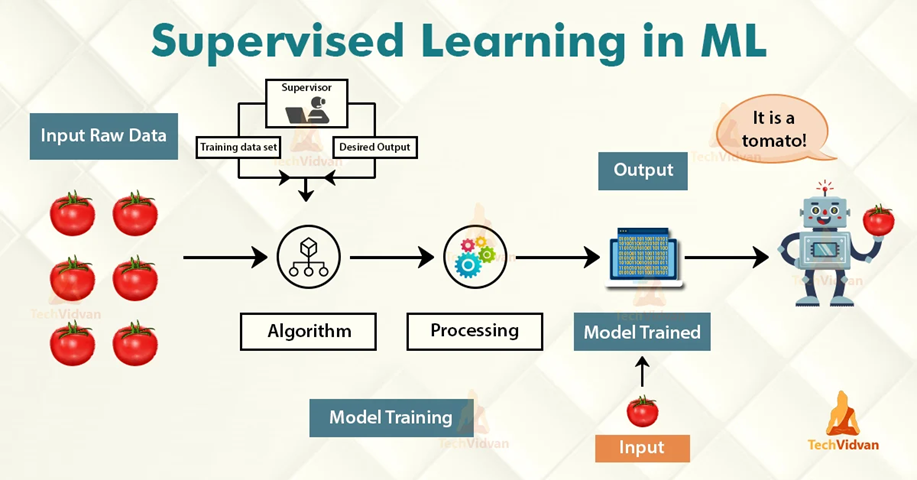
Source: TechVidan
Key differences:
- Output type: Classification outputs discrete labels (e.g., spam or not spam), while regression outputs continuous values (e.g., house prices).
- Evaluation metrics: Classification models often use metrics like accuracy, precision, and recall, while regression models use metrics like mean squared error (MSE) or mean absolute error (MAE).
- Decision boundaries: Classification models may create decision boundaries that separate different categories, while regression models fit a curve or line to the data.
Both classification and regression are foundational in supervised learning, and choosing between them depends on the nature of the prediction problem. In many real-world scenarios, determining whether the task is a classification or regression problem is the first step in selecting the right supervised learning model.
Applications of supervised learning
Supervised learning algorithms have numerous real-world applications across different industries. Some of the key areas include:
Healthcare
Supervised learning is transforming healthcare by enabling early disease detection, medical imaging analysis, and personalized treatment plans. For example, models can be trained to detect cancer in radiology images by learning from labeled datasets of images with known outcomes.
Finance
In finance, supervised learning is used for fraud detection, risk assessment, and predictive analytics. Credit scoring models, for instance, can predict the likelihood of a customer defaulting on a loan based on historical data about customers’ financial behavior.
Marketing
Marketers use supervised learning to segment customers and create personalized marketing campaigns. By learning from customer data, algorithms can predict which customers will most likely respond to in a particular advertisement or offer.
Natural Language Processing (NLP)
In NLP tasks such as sentiment analysis, supervised learning helps classify the emotional tone of text (e.g., positive, negative, or neutral) based on labeled examples. Another common application is machine translation, where models learn to translate sentences from one language to another by training on labeled pairs of translated text.
Next, we’ll discuss how supervised learning works.
How supervised learning works
Supervised learning involves a systematic process where a model learns from labeled data to make accurate predictions or decisions. Let’s break down this process step-by-step, using Python code examples to illustrate each stage:
- Data preparation:
The first step involves gathering a labeled dataset, where every input is paired with its corresponding output. For example, in image classification, you would collect images and label each with its correct category.
Then, you clean the data to ensure data quality by handling missing values, removing duplicates, and correcting any errors. Next is the preprocessing stage, where you transform the data into a suitable format for your chosen algorithm. This might involve:
- Feature scaling: Standardizing or normalizing the range of features.
- Encoding categorical variables: Converting categorical variables (e.g., “red,” “blue,” “green”) into numerical representations.
- Dimensionality Reduction: Reducing the number of features to improve efficiency and prevent overfitting.
Finally, you split the data into training and testing sets. The training set is used to train the model, and the testing set evaluates its performance on unseen data.
In our code, instead of collecting data, we generated data just to show how it can be done programmatically:
X, y = make_classification(
n_samples=1000, # Number of samples
n_features=10, # Number of features
n_informative=8, # Number of informative features
n_redundant=2, # Number of redundant features
n_classes=2, # Number of classes (binary classification)
random_state=42 # Random state for reproducibility
)
The synthetic dataset is created using make_classification(), which generates 1,000 samples with 10 features, 8 of which are informative (relevant to the target) and 2 redundant (linearly dependent on the informative features).
The data is split into features X (input) and labels y (target). Each sample belongs to one of two classes (binary classification problem), simulating a real-world dataset where each data point has multiple attributes, and the goal is to predict whether a data point belongs to Class 0 or Class 1.
# Step 2: Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
The data is split into training and testing sets using train_test_split(). Typically, 70% of the data is used to train the model, and 30% is reserved for testing. The purpose of the split is to evaluate how well the model generalizes to unseen data.
- Loss Function:
The loss function is a mathematical representation of the difference between the predicted values and the actual labels. Common loss functions for regression include mean squared error (MSE), while classification problems often use cross-entropy loss.
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
The model uses binary cross-entropy loss (BCELoss), which is appropriate for binary classification. The optimizer is stochastic gradient descent (SGD), which adjusts the model’s weights iteratively to minimize the loss.
To learn more about gradient descent, read: Neural networks: How to optimize with gradient descent
- Training Phase:
During training, the algorithm processes the input-output pairs to learn the mapping from inputs to outputs. The objective is to minimize the prediction error, which is quantified using a loss function. The model is trained iteratively to adjust its internal parameters (weights) so that its predictions become as close as possible to the actual outputs.
num_epochs = 100
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
y_train_pred = model(X_train_tensor)
loss = criterion(y_train_pred, y_train_tensor)
loss.backward()
optimizer.step()
The training loop iterates over the data for 100 epochs. Each epoch includes:
- A forward pass where the model predicts the outputs for the training data.
- Loss computation using binary cross-entropy.
- Backward pass to compute gradients.
- Updating the model parameters using the optimizer (optimizer.step())
Every 10 epochs, the loss is printed to track the model’s progress.
- Model Evaluation:
Once the model has been trained, it must be evaluated using unseen data, typically by splitting the dataset into training, validation, and testing sets. The validation set is used during training to prevent overfitting, while the testing set evaluates the model’s performance on completely unseen data.
model.eval()
y_test_pred = model(X_test_tensor).detach()
y_test_pred_class = (y_test_pred > 0.5).float()
The model is evaluated on the test set. The model outputs probabilities for each test sample, which are converted to class predictions (0 or 1) by applying a threshold of 0.5. The detach() method ensures that the gradients are not calculated during evaluation, speeding up the process.
Several metrics are used to evaluate the model’s performance:
-
- Accuracy: The proportion of correctly classified samples.
- Precision: The ratio of true positive predictions to all positive predictions (used to avoid false positives).
- Recall: The ratio of true positive predictions to all actual positives (used to avoid false negatives).
- Classification Report: A summary of each class’s precision, recall, and F1 score.
accuracy = accuracy_score(y_test_np, y_test_pred_np)
precision = precision_score(y_test_np, y_test_pred_np)
recall = recall_score(y_test_np, y_test_pred_np)
To learn more about these classification metrics, here: Accuracy, precision, and recall in deep learning
- Final Model:
After the training phase, the final model is used to make predictions on new, unseen data. The model’s generalization ability depends on how well it learned the patterns from the training data and how effectively it avoided overfitting.
Here is the entire code:
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, classification_report
import torch
import torch.nn as nn
import torch.optim as optim
# Step 1: Generate synthetic data
X, y = make_classification(
n_samples=1000, # Number of samples
n_features=10, # Number of features
n_informative=8, # Number of informative features
n_redundant=2, # Number of redundant features
n_classes=2, # Number of classes (binary classification)
random_state=42 # Random state for reproducibility
)
# Convert to DataFrame for better visualization
feature_columns = [f'feature_{i}' for i in range(X.shape[1])]
df = pd.DataFrame(X, columns=feature_columns)
df['target'] = y
# Step 2: Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Step 3: Convert data to PyTorch tensors
# Convert the training and testing data to PyTorch tensors for use in the neural network
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1) # Reshape to match expected dimensions
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1) # Reshape to match expected dimensions
# Step 4: Define a simple neural network model
class SimpleNN(nn.Module):
def __init__(self, input_size):
super(SimpleNN, self).__init__()
# First fully connected layer with 16 output nodes
self.fc1 = nn.Linear(input_size, 16)
# Second fully connected layer with 1 output node (for binary classification)
self.fc2 = nn.Linear(16, 1)
# Sigmoid activation function to output probabilities between 0 and 1
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# Apply ReLU activation to the first layer
x = torch.relu(self.fc1(x))
# Apply sigmoid activation to the output layer
x = self.sigmoid(self.fc2(x))
return x
# Step 5: Initialize the model, loss function, and optimizer
model = SimpleNN(input_size=X_train.shape[1]) # Initialize the model with the number of input features
criterion = nn.BCELoss() # Binary Cross-Entropy Loss for binary classification
optimizer = optim.SGD(model.parameters(), lr=0.01) # Stochastic Gradient Descent optimizer with learning rate 0.01
# Step 6: Train the model
num_epochs = 100 # Number of training epochs
for epoch in range(num_epochs):
model.train() # Set the model to training mode
optimizer.zero_grad() # Clear the gradients from the previous step
y_train_pred = model(X_train_tensor) # Forward pass: compute predicted y
loss = criterion(y_train_pred, y_train_tensor) # Compute the loss between predicted and actual values
loss.backward() # Backward pass: compute gradient of the loss with respect to model parameters
optimizer.step() # Update model parameters
# Print loss every 10 epochs
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# Step 7: Evaluate the model
model.eval() # Set the model to evaluation mode
y_test_pred = model(X_test_tensor).detach() # Forward pass on the test set and detach to avoid gradient tracking
# Convert predicted probabilities to binary class predictions (threshold of 0.5)
y_test_pred_class = (y_test_pred > 0.5).float()
# Step 8: Calculate evaluation metrics
# Convert predictions and true labels to NumPy arrays for metric calculation
y_test_pred_np = y_test_pred_class.numpy()
y_test_np = y_test_tensor.numpy()
# Calculate accuracy, precision, and recall
accuracy = accuracy_score(y_test_np, y_test_pred_np)
precision = precision_score(y_test_np, y_test_pred_np)
recall = recall_score(y_test_np, y_test_pred_np)
# Print evaluation metrics
print(f'Accuracy: {accuracy:.2f}')
print(f'Precision: {precision:.2f}')
print(f'Recall: {recall:.2f}')
print('nClassification Report:n')
print(classification_report(y_test_np, y_test_pred_np))
During the training phase, the model may encounter problems like overfitting (performing well on training data but poorly on new data) or underfitting (failing to capture the underlying patterns in the data). Techniques like cross-validation, regularization, and early stopping can help prevent these issues.
Popular supervised learning algorithms
Several algorithms are commonly used in supervised learning, each with its strengths, weaknesses, and application areas.
Linear Regression
Linear regression is a fundamental algorithm used for regression tasks. It assumes a linear relationship between the input variables and the output variable. Linear regression aims to find the line of best fit, which minimizes the error between predicted and actual values.
Logistic Regression
Despite its name, logistic regression is primarily used for classification tasks. It models the probability of an event belonging to a particular class using the logistic function, which outputs values between 0 and 1. Logistic regression is widely used in binary classification problems, such as predicting whether a tumor is malignant or benign.
Decision Trees
Decision trees are intuitive models that split the data into branches based on feature values, creating a tree-like structure. Each internal node represents a decision based on an attribute, while each leaf node represents the final prediction. Decision trees are easy to interpret but can overfit the data without proper tuning.
Support Vector Machines (SVM)
Support vector machines are powerful classification algorithms that attempt to find the optimal hyperplane that best separates data into classes. The points closest to the hyperplane, known as support vectors, play a crucial role in defining the decision boundary. SVMs are effective in high-dimensional spaces but can be computationally intensive.
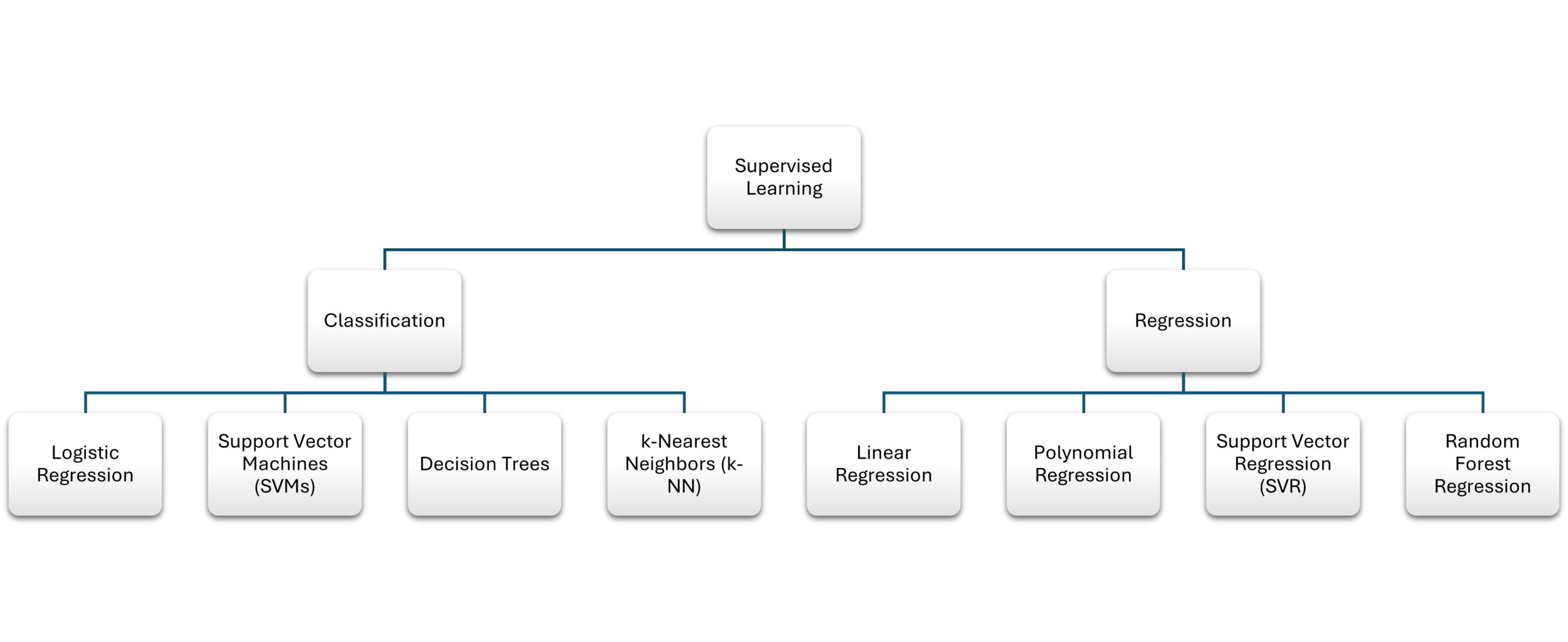
k-Nearest Neighbors (k-NN)
k-NN is a simple, instance-based algorithm that classifies data points based on the labels of their nearest neighbors. The model assigns a class label by looking at the k closest data points (usually in terms of Euclidean distance) and taking a majority vote. Despite its simplicity, k-NN can be powerful for specific types of problems but is computationally expensive for large datasets.
Conclusion
Supervised learning is a fundamental and widely used technique within the field of machine learning. By learning from labeled data, supervised algorithms can make accurate predictions and solve classification and regression problems.
You can build your supervised learning projects today using cost-effective cloud resources on CUDO Compute. CUDO Compute offers the best NVIDIA GPUs, like the NVIDIA A100, at affordable rates. Click here to get started, or contact us.
