 Resources
Resources 
Developing deep learning and AI models efficiently has driven the need for more powerful Graphic Processing Units (GPUs). As discussed previously, GPUs have significantly changed the Deep Learning landscape due to their parallel processing capabilities. PyTorch is a deep learning framework highly dependent on the computational power of Graphics Processing Units (GPUs) for efficient model training and inference.
PyTorch leverages the computational power of GPUs to accelerate deep learning models' training and inference processes. GPUs are particularly well-suited for handling the intensive calculations demanded in machine learning tasks.
In this article, we will compare the NVIDIA A6000 and A100, assessing their suitability for PyTorch workloads. The NVIDIA A6000 and A100 are two powerful GPUs used for deep learning. Both are part of NVIDIA's Ampere architecture. These GPUs have been designed for high-performance computing workloads and advanced AI applications. The A6000, aimed at professionals requiring substantial GPU power, and the A100, built with data centres in mind, represent the cutting edge of current GPU technology.
What is PyTorch?
PyTorch is an open-source machine learning library based on the Torch library, widely used for applications such as natural language processing and artificial neural networks. PyTorch has gained popularity due to its ease of use, flexibility, and efficient memory usage.
What sets PyTorch apart is its dynamic computational graph, also known as a define-by-run graph. This allows developers to change the way the network behaves on the fly. The graph is created on the go as operations are created, providing more flexibility in building complex architectures. This dynamic nature makes PyTorch particularly suited for research and prototyping.
However, this flexibility comes with heavy computational demands, which is where GPUs come into play. GPUs can handle multiple computations simultaneously, making them ideal for the large-scale matrix operations underpinning deep learning algorithms. For PyTorch users, the GPU's performance can significantly impact the speed of training models, the size of the models that can be trained, and, ultimately, the kind of problems that can be solved.
In essence, the right GPU can unlock PyTorch's full potential, enabling researchers and developers to push the boundaries of what's possible in AI.
Is RTX A6000 good for deep learning?
Yes, the RTX A6000 is effective for deep learning. It offers a high CUDA core count and 48GB of memory, suitable for medium-sized deep learning models in tasks like image classification and natural language processing
Overview of NVIDIA A6000 vs A100 GPUs
The NVIDIA RTX A6000 is a powerful, professional-grade graphics card. It is designed to deliver high-performance visual computing for designers, engineers, scientists, and artists.
The A6000 comes with 48 Gigabytes (GB) of ultra-fast GDDR6 memory, scalable up to 96 GB with NVLink. This large memory capacity makes it ideal for data-intensive tasks like those needed for deep learning applications.

The A6000 is built on an 8 nm process and based on the GA102 graphics processor. In terms of performance, the A6000 delivers a smooth experience, even in demanding visual applications. It combines 84 second-generation RT Cores, 336 third-generation Tensor Cores, and 10,752 CUDA® cores, making it a powerhouse for AI computation.
On the other hand, the NVIDIA A100 GPU is a high-end graphics card specifically designed for AI and high-performance computing workloads. We have comprehensively discussed the A100 GPU. Read more on it here.
The A6000 and A100 GPUs are instrumental in AI and machine learning due to their high computational power and large memory capacities. They can handle complex tasks such as training large neural networks, running simulations, processing large datasets, and supporting advanced research in AI.
Performance benchmarks and analysis of A6000 and A100
When evaluating the performance of GPUs for PyTorch tasks, it is essential to consider their benchmarks and capabilities in training and inference.
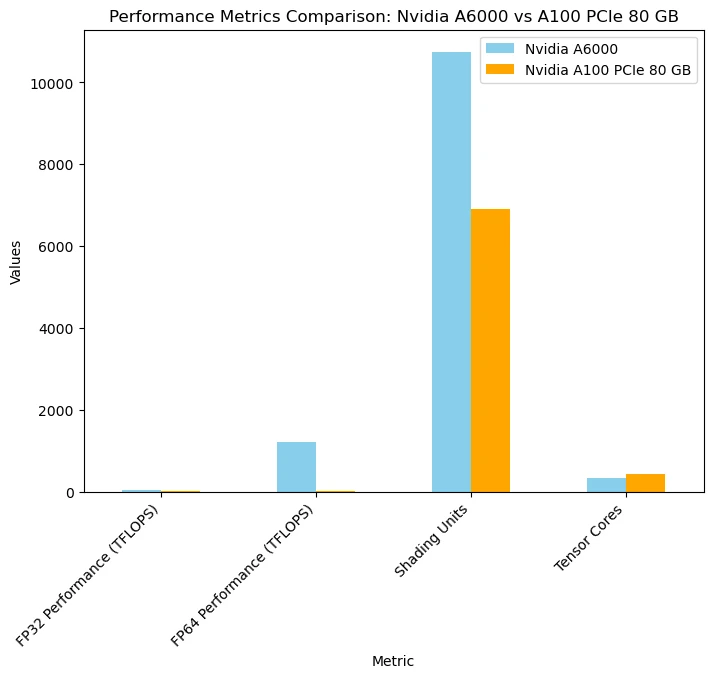
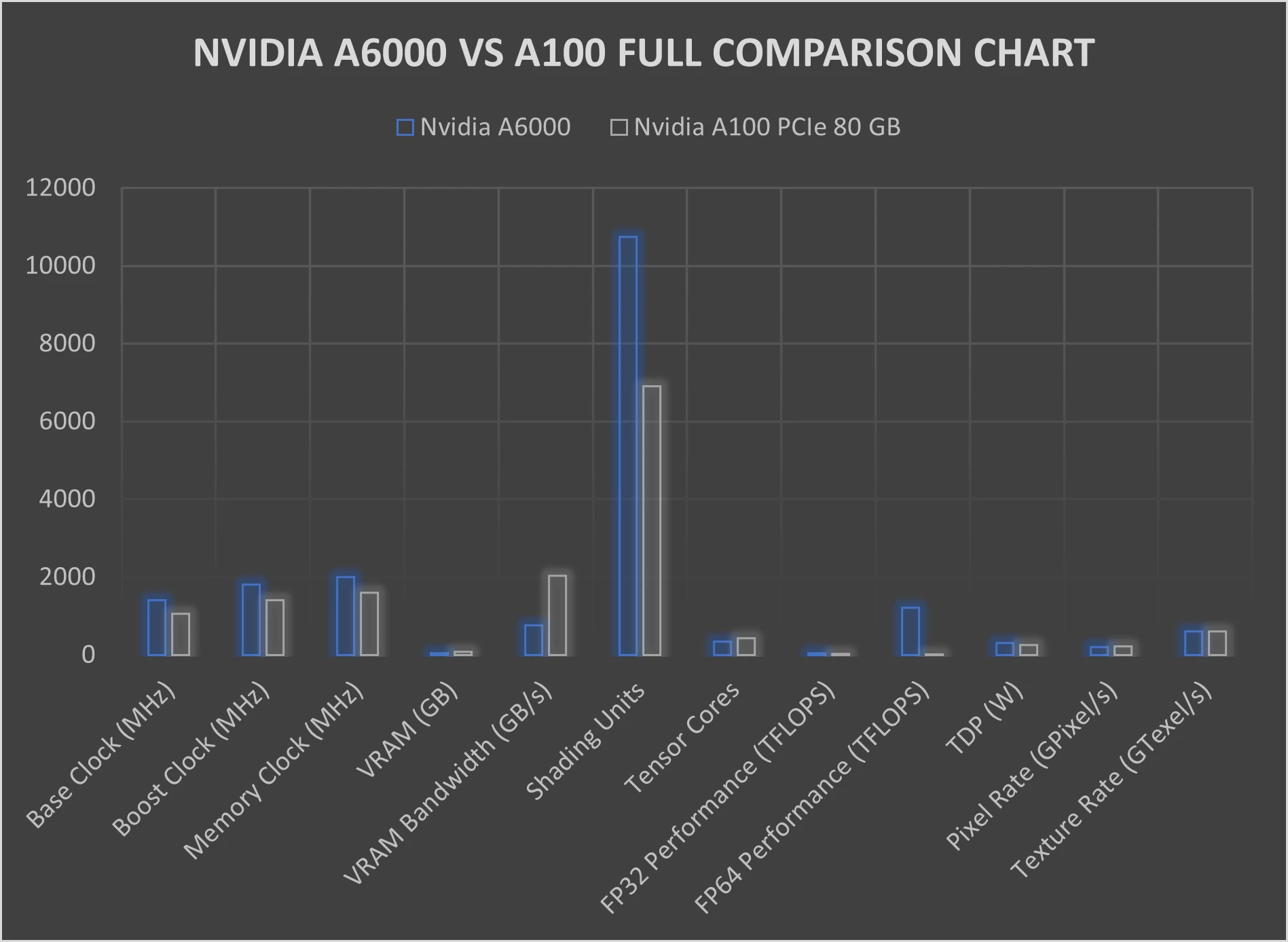
These are the benchmarks for The NVIDIA A6000 and A100 GPUs:
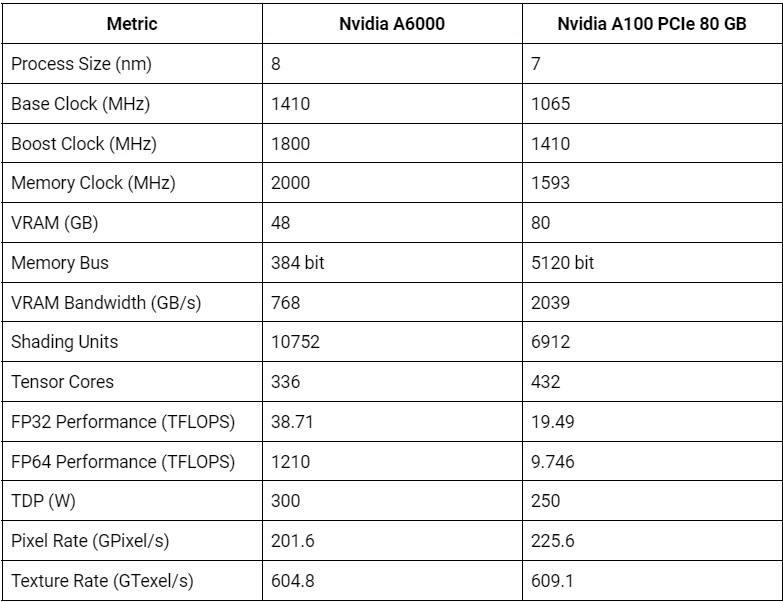
Let's analyse the performance of the A6000 and A100 GPUs in these typical PyTorch tasks backed by real-world use cases:
1. Training Performance:
Training deep learning models requires significant computational power and memory bandwidth. The A100 GPU, with its higher memory bandwidth of 1.6 TB/s, outperforms the A6000, which has a memory bandwidth of 768 GB/s. This higher memory bandwidth allows for faster data transfer, reducing training times.
Benchmarks have shown that the A100 GPU delivers impressive training performance. For example, in image classification tasks using popular datasets like ImageNet, the A100 has demonstrated faster training times than previous-generation GPUs. This is particularly evident when training large-scale models that require extensive memory bandwidth and computational power.
Real-world use cases also highlight the A100's prowess in training tasks. For instance, in natural language processing (NLP) tasks such as training transformer-based models for language translation or sentiment analysis, the A100's higher memory bandwidth and Tensor Cores contribute to faster convergence and improved training times.
What are A100 GPUs used for?
A100 GPUs can be used for high-performance computing and advanced deep-learning tasks. They excel in training complex neural networks and mixed-precision computations, ideal for cutting-edge AI applications and large-scale model training.
2. Inference Performance:
Inference, or using a trained model to make predictions on new data, is another crucial aspect of deep learning. The A100 GPU's Tensor Cores significantly enhance inference performance, particularly for mixed-precision calculations. These Tensor Cores enable faster computations, resulting in improved inference times.
Benchmarks have demonstrated that the A100 GPU delivers impressive inference performance across various tasks. For example, in object detection tasks using popular datasets like COCO, the A100 has shown faster inference times than previous-generation GPUs. This is particularly beneficial in real-time applications that require quick and accurate object detection, like self-driving cars or video surveillance.
Real-world use cases further emphasise the A100's superiority in inference tasks. For instance, in speech recognition tasks, the A100's Tensor Cores enable faster processing of audio data, leading to improved real-time transcription accuracy. Similarly, in generative modelling tasks, such as training generative adversarial networks (GANs) for image synthesis, the A100's enhanced performance allows for faster generation of high-quality images.
While the A100 GPU generally outperforms the A6000 in PyTorch training and inference tasks due to its superior memory bandwidth and Tensor Cores, the A6000 remains effective for medium-sized models, particularly in applications like image classification and object detection. The decision between the two GPUs hinges on the application's specific needs.
The A6000's higher CUDA core count and memory capacity make it suitable for tasks that do not extensively require mixed-precision calculations. Conversely, for large-scale deep learning tasks demanding faster data transfer and improved mixed-precision performance, the A100 is the optimal choice. Selecting the right GPU requires understanding each unique strength to align with the requirements of the intended PyTorch application.
To use NVIDIA A6000 and NVIDIA A100 GPUs for your deep learning project, take advantage of CUDO Compute's impressive selection of GPUs available on demand. With CUDO Compute, you can seamlessly access and utilise the NVIDIA A6000 and A100 GPUs, unlocking their full potential for your PyTorch applications.
Whether you need to train large-scale models, perform real-time inference, or tackle complex deep-learning tasks, CUDO Compute provides the infrastructure and resources you need. Take advantage of the opportunity to accelerate your deep learning workflows with the A6000 and A100 GPUs on CUDO Compute. Sign up today and experience the power and efficiency of these GPUs in the cloud. Take your PyTorch applications to new heights with CUDO Compute and NVIDIA's A6000 and A100 GPUs. Get started now and unlock the full potential of deep learning.
About CUDO Compute
CUDO Compute is a fairer cloud computing platform for everyone. It provides access to distributed resources by leveraging underutilised computing globally on idle data centre hardware. It allows users to deploy virtual machines on the world’s first democratised cloud platform, finding the optimal resources in the ideal location at the best price.
CUDO Compute aims to democratise the public cloud by delivering a more sustainable economic, environmental, and societal model for computing by empowering businesses and individuals to monetise unused resources.
Our platform allows organisations and developers to deploy, run and scale based on demands without the constraints of centralised cloud environments. As a result, we realise significant availability, proximity and cost benefits for customers by simplifying their access to a broader pool of high-powered computing and distributed resources at the edge.
