 Resources
Resources 
By 2030, global data center capacity is projected to nearly triple, with AI workloads accounting for roughly 70% of total demand. General-purpose cloud is no longer the dominant design driver. High-performance AI infrastructure is drawing power, cooling, and floor space at a rate the market was not built to sustain.
That surge is colliding with a rigid supply chain. Utility transmission bottlenecks and permitting delays have effectively stalled rapid expansion, while lead times for key power equipment, such as backup generators, have stretched from months to years.
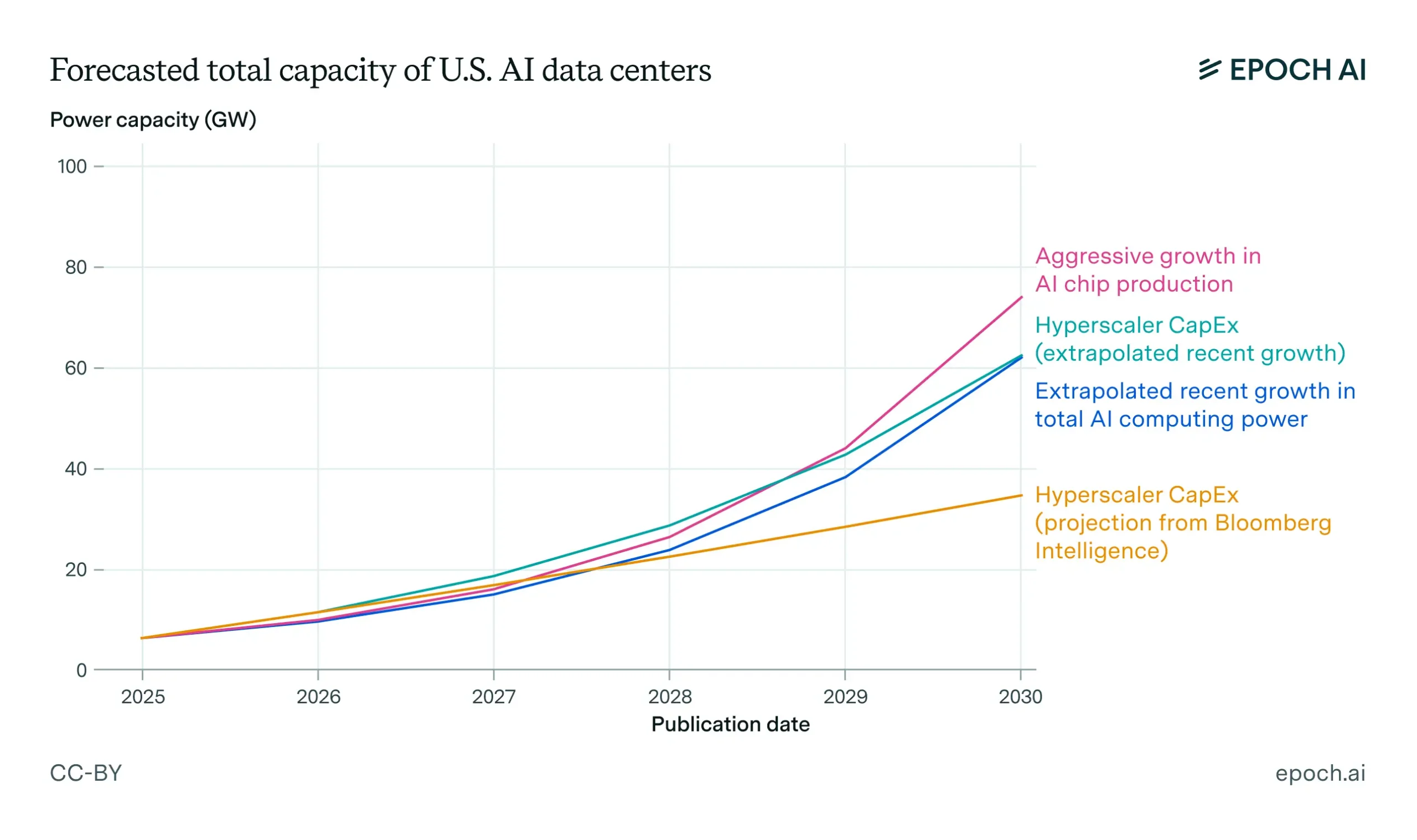
Projections of growth in total US AI data center capacity, based on several estimates or extrapolations from current trends, assuming the US maintains a 50% share of worldwide AI capacity. The current US baseline of 5 GW is an estimate. See the full report for details. Source: Article
Compounding this scarcity is the upward trajectory of thermal density. The Nvidia H100 pushed air-cooled infrastructure to its breaking point at roughly 40 kW per rack. The Blackwell architecture shatters that ceiling. With the GB200 NVL72, the industry is moving to 120 kW liquid-cooled racks as the new atomic unit of compute. This is not just a chip upgrade. It is a facilities overhaul that renders legacy cooling and power distribution obsolete.
Consequently, the traditional build-as-you-grow capacity model is broken. Operators can no longer incrementally add capacity when power activation timelines span 24 to 72 months. Instead, the industry requires rack-scale, multi-year planning that treats utility power, liquid-cooling loops, and GPU roadmaps as a single interdependent system from site selection onward.
The scale problem
The numbers no longer fit legacy planning assumptions. Training compute for frontier AI models has grown by 4–5x annually since 2010, with the most recent frontier models specifically accelerating at 5.3x per year. Power demand for these training runs follows a similarly aggressive curve, with the largest single jobs now exceeding 100 MW. This trajectory is not slowing; it is colliding with physical infrastructure that most operators have never had to provision.
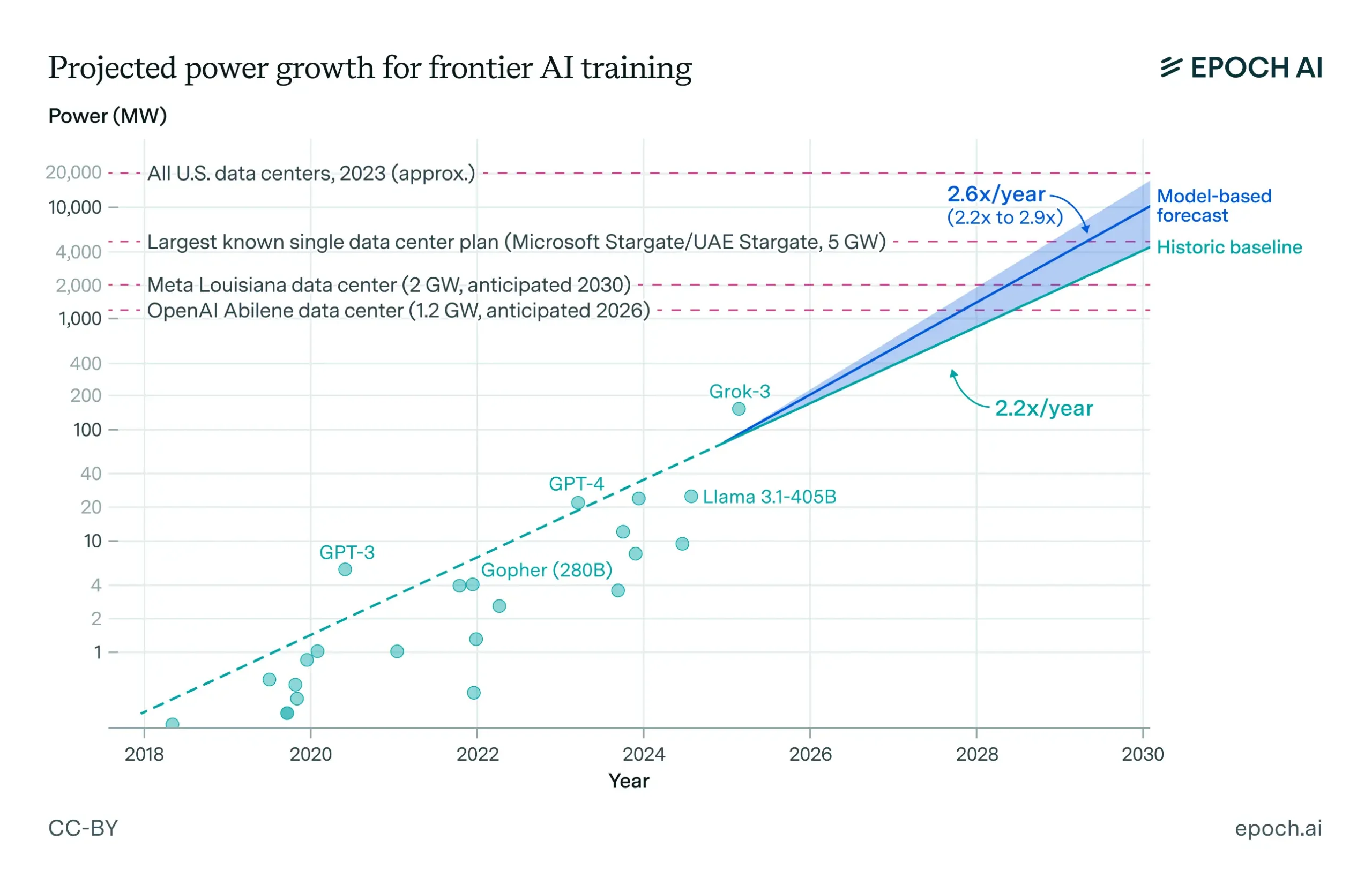
Historic trend and forecast for the power demand of the largest individual frontier training runs. The shaded interval is the 10th and 90th percentiles of our forecast based on trends in training compute, efficiency, and training run duration growth. The main source of upside uncertainty relative to the historic trend is whether limits to training duration motivate accelerated scaling in training hardware. Source: Article
Single model families now anchor multi-gigawatt build programs. OpenAI operates what is widely considered the world's largest single datacenter in Texas, with an IT load capacity of approximately 300 MW, and aims to reach gigawatt-scale by 2026. xAI's Colossus cluster in Memphis, which brought its initial 100k GPUs online in just 122 days, has already expanded to roughly 200,000 H100/H200 units drawing nearly 300 MW, with further expansion targeting gigawatt capacity. Meta's Prometheus project, slated for 2026, is a 1 GW supercluster designed to house up to 500,000 GPUs. These are not research clusters; they are production infrastructure dedicated to training and serving single model lineages.
Supply chain constraints persist across the stack. TSMC's CoWoS (Chip-on-Wafer-on-Substrate) capacity, which is critical for interconnecting HBM stacks with AI processors, remains the primary bottleneck, with orders fully allocated through the end of 2025. As discussed previously, the limiting factor is often interposer availability rather than raw GPU die yields, which causes supply chain timelines to lag by 6–12 months. NVIDIA's Blackwell series is already backlogged well into next year, with hyperscalers effectively monopolizing the early allocation.
Furthermore, rack density has become a deployment filter, as facilities unable to support 60–120 kW-per-rack liquid-cooling simply cannot deploy this hardware, even if they can procure it.
Expansion planning must therefore shift from "GPU count" to total system capacity. The relevant metrics are now MW per hall, coolant flow rates, and time-to-power—not just how many accelerators fit on an order sheet.
Modeling the capacity curve
Frontier AI infrastructure cannot be planned the way traditional datacenters were. The old model assumed steady, predictable growth—add a pod when utilization crosses 70%, provision transformers a year out, and lease additional space as needed. That model assumed the planning variables held still long enough to act on them. They no longer do.
The core tension is between lead time and rate of demand. The lead time for power transformers has historically been 6–8 months, but with supplies strained by the growing demand for AI data centers, new orders now have lead times of 3–4 years.
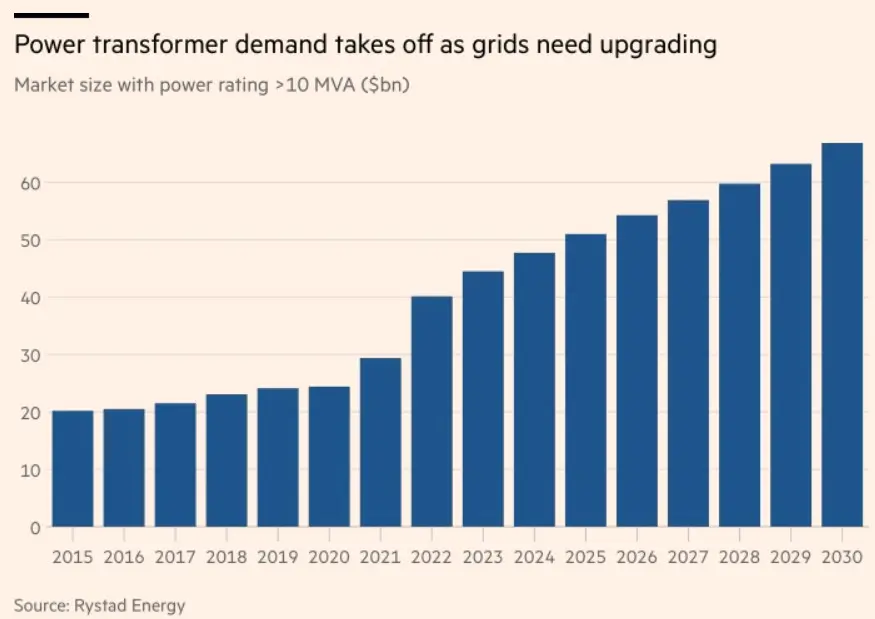
Source: Article
Power availability constraints are already extending data-center construction timelines by 2–4 years, and in some markets by as much as 6 years; when new substations or upgraded transmission lines are required, another 1–4 years of delay is common.
Meanwhile, NVIDIA now introduces new data-center GPU architectures roughly every year, and it is now aligning its roadmap around a yearly platform rhythm that alternates between a new architecture and an “Ultra” refresh (e.g., Blackwell → Blackwell Ultra → Rubin → Rubin Ultra). Across these cycles, deployments are pushing higher rack power densities, greater reliance on liquid cooling, and more rack-scale system designs.
Vendors are shipping Blackwell-class systems as turnkey, “plug-and-play” rack-scale AI systems, but the power and cooling envelopes for Rubin-era systems are expected to shift materially again. NVIDIA has already previewed Rubin Ultra NVL576 “Kyber” as a liquid-cooled rack on the order of ~800 kW per rack, a very different facility profile than today’s 120 kW-class racks.
In practice, the facility-level infrastructure you commit to today must be designed to accommodate future GPU generations that have not yet shipped. The problem is, GPU technology changes every year, but building the power grid to support it now takes five years.
This mismatch forces a choice between two capacity strategies. The first is elastic expansion, leasing colocation capacity, relying on cloud burst, and avoiding locking capital into fixed infrastructure until demand materializes. The second is deliberate overbuild, securing land, power, and cooling ahead of demand, accepting stranded capacity as the cost of optionality.
Neither approach is universally correct. Elastic models fail when colocation inventory is exhausted. Most existing colocation data centers are not ready for rack densities above 20 kW per rack, while AI superclusters require 60–120 kW per rack, creating a power density mismatch that leaves operators flat-footed. Fixed overbuild fails when GPU roadmaps shift faster than facilities can adapt. This locks capital into designs that are incompatible with industry shifts.
The historical record is not reassuring. For instance, Meta had the worst datacenter design in terms of power density among the hyperscalers, but halted development of planned datacenter projects and rescoped them for AI workloads. Hyperscaler facilities currently have an estimated average rack density of 36 kW, projected to reach 50 kW by 2027, yet the GB200 NVL72 ships at 120 kW today. The gap between planning assumptions and deployed hardware has consistently run 2–3× in the wrong direction.
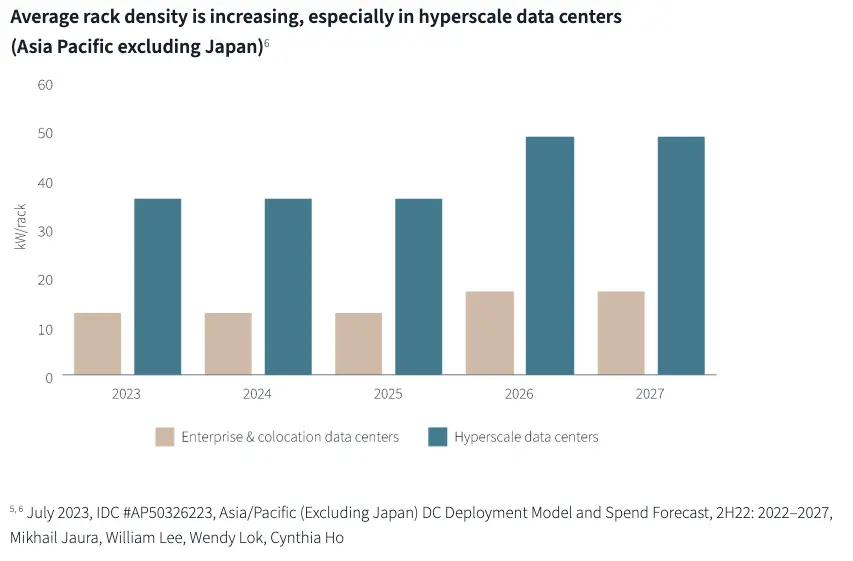 Source: Article
Source: Article
Effective capacity modeling must therefore blend two approaches. The first is top-down demand forecasting driven by model roadmaps and training schedules. The second is bottom-up infrastructure modeling that maps MW per hall, coolant flow rates, and logistics constraints. Sensitivity analysis should stress-test against the variables that actually gate deployment, such as grid connection timelines, transformer procurement windows, and GPU release cadence. The goal is not a single forecast but a decision framework that identifies when to commit capital, when to hold optionality, and what infrastructure bets are reversible versus locked in.
The power constraint
Power has become the binding constraint on AI infrastructure. Not compute, not real estate, not even GPU supply—power access now determines where datacenters can be built and how quickly they can scale.
The demand curve is unambiguous. Demand for datacenter power will increase by 160% by 2030. But the supply side cannot keep pace. There's currently a 7-year wait for some requests to connect to the grid. Traditional utility interconnection was designed for gradual industrial growth, not facilities that require hundreds of megawatts on day one. Data center operators are beginning to assume roles traditionally held by utilities themselves—funding substations, managing grid interconnections, and experimenting with on-site generation.
The response has been a fundamental shift in power acquisition strategy. Data center developers are rethinking their approach by adopting behind-the-meter configurations, where power generation and consumption occur on the same site. More than 35 GW of datacenter power will be self-generated by 2030. Major AI builders now negotiate direct grid access at the substation level to bypass legacy distribution networks entirely. CyrusOne, for example, is partnering closely with utilities and taking financial responsibility for substation infrastructure projects—designing, funding, and delivering solutions that utilities simply connect into.
The economics of power sourcing are shifting in parallel. The 1-GW fuel cell deal between AEP and Bloom Energy would set a new record, marking the largest utility-scale fuel cell procurement in U.S. history and enabling faster deployment compared to traditional grid upgrades. Renewable-backed PPAs, on-site natural gas generation, and microgrids define long-term resilience for operators unwilling to wait years for utility timelines.
The implications for site selection are severe. A single AI training cluster can demand 50–100 MW on its own, while wholesale campuses regularly request 200 MW or more from utilities. Securing multi-decade power commitments is no longer optional; it is the prerequisite for every major project. Markets that once dominated—Northern Virginia, Dublin, Singapore—now face moratoriums on new connections. The next generation of AI infrastructure will be built where power exists, not where datacenters have historically clustered.
Cooling: keeping up with exascale thermals
Thermal management has shifted from an operational detail to an architectural constraint. As rack densities climb past 100 kW and approach 150 kW for frontier clusters, the physics of heat removal dictate what can be deployed and where.
Liquid cooling adoption is gaining traction rapidly, with high-density power architectures evolving rapidly—racks are expected to reach 600 kW soon, and 1 MW configurations are already under consideration. Air cooling, which once handled the full thermal load of enterprise datacenters, now cannot manage even a single GPU node without supplemental liquid-cooling systems.
The efficiency gains from liquid cooling are substantial and well-documented. A typical liquid-cooled datacenter consumes almost 50% less energy than its air-cooled counterpart. Liquid-cooled datacenters also enable much more compact designs—more than three times the density of their air-cooled counterparts. Traditional datacenter infrastructure using air cooling accounts for around 35–40% of total facility power. Liquid cooling eliminates the need for hot and cold aisles, raised floors, and CRAC units.
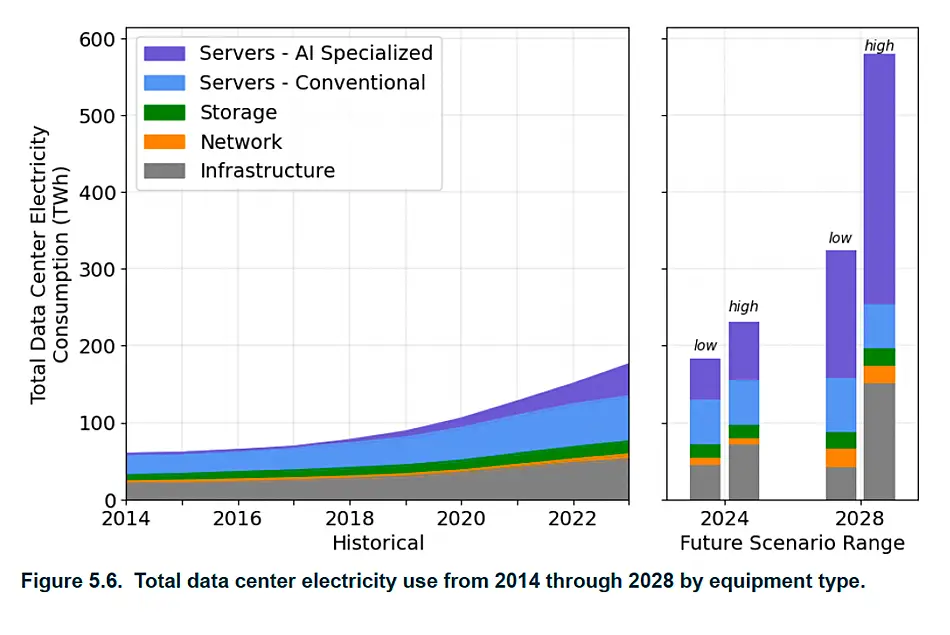 Source: Article
Source: Article
Direct-to-chip liquid cooling has become the baseline for high-density deployments. Direct-to-chip cold plates featuring microchannels attached directly to processors operate with supply water at 40°C and return at 50°C, removing 70–75% of rack heat through liquid while maintaining a partial PUE of 1.02–1.03. But even these systems face limits as GPU TDPs continue to rise.
The frontier is microfluidics—cooling that operates inside the silicon itself. Microsoft's lab-scale tests showed that microfluidics performed up to 3 times better than cold plates at removing heat, depending on workload and configuration. Microfluidics also reduced the maximum temperature rise of the silicon inside a GPU by 65%. The technology dissipates more than 1 kW/cm², handling 2–3 times the heat flux of standard cold plates. Some executives have publicly referenced dissipation targets of 4-10 kW per device, highlighting that in-chip cooling could sustain next-generation GPU power levels without throttling.
Multi-loop cooling architectures will become standard for pods exceeding 1 MW. These systems segregate primary chip cooling from secondary facility loops, allowing finer thermal control and enabling waste heat capture at temperatures useful for district heating or industrial processes.
Real estate and location strategy
The traditional heuristics for datacenter siting—proximity to population centers, fiber density, tax incentives—have been subordinated to a single variable: power availability. AI facilities are power-bound, not space-bound.
Markets like Northern Virginia, Dublin, and Singapore illustrate the risk of relying on overburdened grids. Utilities in these regions have imposed moratoriums on new connections, forcing developers to look elsewhere. Currently, the smartest site selection strategies prioritize markets with uncongested grids and expandable utility capacity.
The result is geographic dispersion to regions that would have been unthinkable five years ago. Some hyperscalers have entered non-traditional datacenter markets in Indiana or Mississippi, where capacity was available, as well as other rural areas in the central U.S.
Latency considerations differ by workload type. Training clusters, which run long synchronous jobs across thousands of GPUs, remain sensitive to interconnect latency and benefit from proximity to talent and data sources. Inference workloads, by contrast, are increasingly decentralized, deployed closer to end users with less stringent interconnect requirements. This split enables a hub-and-spoke model: centralized training in power-rich regions, distributed inference at the edge.
Factory-built power modules, skid-mounted cooling plants, and standardized hall "blocks" of 50–100 MW each will enable deployments to ramp rapidly while reducing site-specific engineering friction. At this scale, modular isn't just proof of concept; it becomes the backbone of how these campuses are built. The emerging pattern is modular campuses—multiple 25–50 MW pods rather than monolithic 200 MW builds—allowing operators to phase deployment as power becomes available and GPU roadmaps evolve.
Grid-optional strategies are gaining momentum because they offer speed to market, scalability, and location freedom. Deploying power and IT infrastructure concurrently can reduce time-to-go-live by up to two years compared to grid-reliant builds. Facilities can be sited based on business and operational priorities, rather than being constrained by grid capacity.
Supply-chain resilience
The GPU is no longer the gating factor for AI infrastructure deployment. The constraint has shifted upstream—to wafer packaging, memory substrates, and datacenter build materials that now determine whether compute can actually be installed and powered.
TSMC's CoWoS packaging is critical for stacking HBM alongside AI processors. Demand for this advanced integration technique has exploded in the past year, and capacity was already fully booked through the end of 2025. While TSMC planed to double CoWoS capacity in 2025, demand is projected to surge 113% year over year. The constraint on advanced packaging is structural and likely to persist well through 2026.
Memory allocation is equally constrained. SK Hynix, Samsung, and Micron—the three dominant producers of HBM chips—are currently reporting lead times of 6 to 12 months amid a backlog of orders. HBM3 pricing has already risen 20–30% year-over-year, a trend that has persisted throughout 2025 as demand continues to outpace capacity expansion. SK Hynix said in May 2024 that its 2024 allocation was fully booked and that "2025 is almost sold out." Meaningful HBM4 volume isn't expected until late 2026.
The physical infrastructure stack faces parallel bottlenecks. As stated earlier, transformer lead times have extended from 6–8 months historically to 3–4 years. Switchgear, chillers, and backup generators all have 12–24-month procurement windows. Due to the surge in demand for advanced CoWoS packaging driven by AI applications, even upstream materials such as T-glass fiber for substrates are falling short, with manufacturers unable to secure sufficient supply. Some substrate manufacturers have rented offices near Resonac's factory to closely monitor material availability.
For supply chain leaders navigating the web of AI hardware availability, reacting to new variables is no longer sufficient. The intersection of capacity constraints, geopolitical volatility, and escalating demand requires a structural rethink of procurement strategies. Surviving this cycle will depend on the ability to rapidly shift from transactional buying to long-horizon planning. Long-term procurement partnerships—with foundries, memory suppliers, and electrical equipment manufacturers—are now as critical as energy planning.
How to design datacenters for modular growth
Traditional datacenter design assumed a stable end-state: build a facility to target capacity, commission it, and operate. AI infrastructure planning inverts this model. Demand speed, GPU roadmap, and supply chain volatility all favor architectures that can scale incrementally without stranding capital or disrupting operations.
A data center pod is a modular unit within a data center, designed to simplify and scale the deployment and maintenance of essential IT infrastructure. At its core, a pod is a self-contained unit that includes all necessary components, such as power, cooling, networking, and IT infrastructure. This modularity enables easier scaling by adding more pods as needed.
Pod-based design treats each unit as an independent power and cooling domain. Power skids are scalable, flexible, and can be built as on-site construction proceeds, accelerating time to compute and allowing for phased data center growth. Prefabricated, self-contained modules integrate MV switchgear, transformers, main LV switchboards, UPS systems, and cooling solutions with interconnecting busbars for easy-to-manage critical power delivery.
Instead of taking up to 5 years to bring a site online, the average development cycle is down to 18–24 months for a first facility, with aggressive expansion thereafter. The solution is increasingly seen as lying in prefabricated modules, which are assembled off-site and delivered ready for in-situ installation.
The operational benefits compound over time. When data centers are built with modularity in mind, expansion or upgrades can often be done without interrupting existing operations, ensuring continuous availability. Modular data centers are often designed with energy efficiency in mind, featuring optimized power distribution and cooling systems tailored to each module's specific needs.
Modular growth also aligns capital deployment with supply availability. Rather than committing to 200 MW of infrastructure that may sit partially stranded waiting for GPU allocation, operators can deploy 25–50 MW pods as hardware becomes available—matching CapEx to actual deployment velocity and reducing the risk of thermal or power architecture obsolescence.
Economics: translating infrastructure to $/token
Infrastructure investment reduces to a single metric: the cost to produce useful AI output. For frontier training, the unit of account is compute-hours or FLOP-seconds. For inference, it is tokens. Both depend on the same underlying economics.
The basic formula is straightforward: Effective $/token = (CapEx + OpEx) / (Model Throughput × Utilization × Time)
However, the variables driving this equation are locked in years in advance. In a standard colocation model, power accounts for roughly 90% of the facility cost, while physical space is just 10%. When viewed through the lens of Total Cost of Ownership (TCO), the contrast is even sharper. Since ~80% of TCO stems from the GPU hardware itself, the cost of physical floor space accounts for only 2–3% of the total investment.
This dictates the strategy. Optimization should not focus on minimizing square footage, but on maximizing power. The economic equation is dominated by cooling efficiency, grid access delays, and energy pricing—the real variables that determine if your expensive hardware can actually run.
As AI becomes increasingly central to business operations, leaders should begin evaluating infrastructure not just by power cost or capacity, but by how many useful AI outputs (tokens) are produced per watt. That's the future of responsible, performance-driven AI deployment.
Cooling and energy efficiency directly translate into economic benefits. Immersion systems that achieve a PUE of 1.03, compared with air-cooled facilities at 1.4–1.5, deliver 25–30% lower effective power cost per token. Grid delays that strand GPU inventory inflate cost per token by the carrying cost of idle capital—potentially 20–30% over a multi-year deployment window.
48V architectures have become critical for powering artificial intelligence. By streamlining power distribution and reducing conversion steps, 48V systems can lower costs, improve scalability, and enable dense server configurations. Unlike the traditional 12V DC power distribution historically utilized in data centers, 48V systems reduce currents and minimize resistive losses throughout the rack.
Transparent cost modeling—linking infrastructure decisions to token economics—helps justify proactive buildouts. When the cost of waiting (stranded GPUs, delayed revenue, competitive disadvantage) exceeds the cost of overbuilding, the calculus favors aggressive expansion. Without clear $/token visibility, organizations default to reactive capacity planning that consistently arrives late.
Designing for the next decade
AI compute growth is not slowing. The question is not whether infrastructure will need to scale further, but whether today's architectural decisions will accommodate the scale that emerges.
Research estimates that there will be around 122 GW of data center capacity online by the end of 2030—more than double today's 59 GW. The mix of this capacity is expected to skew even further towards hyperscalers and wholesale operators. AI workload is expected to more than triple between 2025 and 2030, and the incremental AI capacity added per year is expected to be 124 gigawatts by 2030.
The hardware trajectory points toward further density increases. Technologies such as chip-on-wafer-on-substrate packaging promise to enhance computational density by up to 40 times. Wafer-scale processors, by reducing internal data traffic, consume far less energy per task. Future wafer-scale AI computers will integrate even greater memory capacity, enabling large numbers of concurrent users to share the same machine. This raises a fundamental question: how should systems be designed to manage such massive architectures?
Planning must anticipate 2–3× density jumps within the useful life of facilities being commissioned today. A datacenter designed for 50 kW racks will be obsolete before its lease expires if the market moves to 150 kW. Cooling architectures must support liquid-to-chip pathways that do not yet exist in production. Electrical distribution must accommodate 48V and potentially 400V rack-level power delivery.
Regulatory evolution adds another variable. Carbon reporting requirements, water usage restrictions, and grid interconnection policies are all tightening. Facilities that optimize solely for today's rules may face retrofit costs or operational constraints as standards evolve.
By 2026, electricity, water resources, advanced packaging capacity, and optical interconnect capability will all be repriced. The winners will be those who can convert bandwidth engineering into productivity and pricing leverage. This is not merely a technological race—it is a reorganization of power across the supply chain and infrastructure layers.
The organizations that succeed over the next decade won't be those with the most GPUs today. They will be those with the most foresight in power acquisition, cooling architecture, and supply-chain positioning—the organizations that treated infrastructure not as a support function but as a strategic weapon.
