 Resources
Resources 
The efficient utilisation of Graphical Processing Units (GPUs) is crucial in accelerating training and inference processes in Deep Learning (DL) and Artificial Intelligence (AI). GPUs are highly parallel processors that excel at performing the matrix calculations required by deep learning algorithms. Optimising GPU efficiency can significantly reduce training times, enabling faster model development and experimentation.
One GPU that stands out in optimising TensorFlow GPU performance is the NVIDIA RTX A5000. This high-end professional GPU, built on the Ampere architecture, offers exceptional performance and power efficiency. With its specifications, the A5000 is well-suited for demanding deep learning workloads.
In this article, we will explore the importance of GPU efficiency in deep learning and AI and delve into the capabilities of the NVIDIA RTX A5000 GPU. We will discuss how the A5000 can optimise TensorFlow GPU performance, enabling developers to harness the full potential of their deep-learning models.
NVIDIA RTX A5000 GPU overview
We have previously discussed that the NVIDIA RTX A5000 is a high-end professional GPU designed for high-performance computing tasks, including machine learning, deep learning, and AI. While NVIDIA's gaming-oriented GPUs, such as the RTX 3080 or RTX 3090, offer exceptional performance, the A5000 is optimised for professional applications. It provides features and optimisations that cater to the unique requirements of machine learning and deep learning tasks.
The A5000's high memory capacity allows for the processing of large datasets, while its extensive CUDA core count enables efficient parallel processing of complex deep learning models. These features make the A5000 ideal for professionals who require optimal performance and reliability in their AI and deep learning workflows.
These are some key performance benchmarks for the RTX A5000:
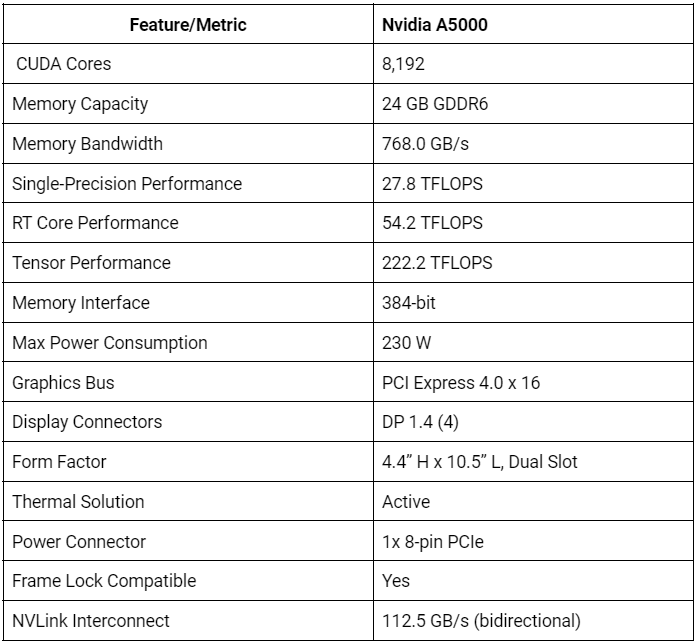
Furthermore, the A5000 supports advanced features like mixed precision training and Tensor Cores. Mixed precision training combines single-precision (FP32) and half-precision (FP16) floating-point formats, allowing faster computations without sacrificing accuracy. Tensor Cores, specialised hardware units, accelerate matrix operations commonly used in deep learning workloads, further enhancing performance.
How do I limit GPU memory usage in TensorFlow?
To limit GPU memory usage in TensorFlow, use the tf.config.experimental.set_memory_growth method. This dynamically allocates memory as needed, preventing excessive memory allocation.
TensorFlow GPU utilisation
TensorFlow is an open-source machine learning framework developed by Google. It provides a comprehensive ecosystem for building and deploying machine learning models across various applications. TensorFlow offers a high-level API that simplifies the process of designing, training, and deploying deep learning models.
One of the key advantages of TensorFlow is its ability to leverage GPU acceleration for computationally intensive operations. GPUs are highly parallel processors that excel at performing matrix calculations, which are fundamental to deep learning algorithms. TensorFlow can significantly speed up training and inference processes by offloading computations to the GPU.
GPU acceleration in TensorFlow is particularly significant for deep learning tasks due to the massive matrix operations involved. Deep neural networks have numerous layers with millions or even billions of parameters. Training these models on CPUs alone can be time-consuming. However, using GPUs, TensorFlow can distribute the workload across thousands of cores, enabling parallel processing and dramatically reducing training times.
In addition, GPUs offer substantial memory bandwidth, allowing efficient data transfer between the CPU and GPU. This is crucial when working with large datasets, as it minimises the time spent on data transfer and maximises the time spent on actual computations.
TensorFlow's ability to harness GPU acceleration is crucial in machine learning. Using GPUs' parallel processing power and memory bandwidth, TensorFlow can significantly speed up training and inference processes, enabling developers to iterate and experiment with their models more efficiently. GPU acceleration in TensorFlow is key to achieving high-performance deep learning workflows.
How do I speed up my TensorFlow GPU?
Speed up your TensorFlow GPU performance by optimising your code and utilising parallel processing. Use GPU-accelerated operations, batch processing, and efficient data-loading techniques.
Optimising TensorFlow Performance with the NVIDIA RTX A5000 GPU
To optimise TensorFlow performance, you can utilise various strategies and features that harness the power of the NVIDIA RTX A5000 GPU. Here are a few of them:
- Utilise Tensor Cores: As stated earlier, the A5000 GPU is equipped with Tensor Cores, specialised hardware units that accelerate matrix operations commonly used in deep learning workloads. By enabling mixed precision training, Tensor Cores can significantly speed up computations without sacrificing accuracy by enabling mixed precision training. This feature can be enabled in TensorFlow using the appropriate APIs and configurations.
- Utilise NVIDIA's CUDA toolkit and cuDNN libraries: NVIDIA provides the CUDA toolkit and cuDNN libraries specifically designed to enhance GPU performance. The CUDA toolkit provides a programming model and tools for GPU-accelerated computing, while cuDNN offers highly optimised deep neural network primitives. Developers can optimise TensorFlow performance on the A5000 GPU by utilising these libraries and following best practices.
- Parallelize computations: TensorFlow supports parallel execution across multiple GPUs, allowing for even more significant performance gains. By distributing the workload across multiple A5000 GPUs, developers can achieve faster training and inference times.
- Monitor and optimise GPU utilisation: It is important to monitor GPU utilisation during training and inference to ensure efficient utilisation of the A5000 GPU. TensorFlow provides tools like TensorBoard and GPU profiling APIs to help identify bottlenecks and optimise GPU usage.
In addition to these strategies, cloud services are another effective approach to optimising TensorFlow performance with the NVIDIA RTX A5000 GPU. Cloud platforms like CUDO Compute offer the flexibility and scalability needed to utilise the GPU's capabilities efficiently. Using cloud services, developers can quickly provision and scale GPU instances per their requirements, eliminating the need for upfront hardware investments and only paying for what they use. Cloud providers also offer pre-configured environments with the necessary software and libraries, simplifying the setup process.
Furthermore, cloud services often provide additional features like auto-scaling, load balancing, and data storage, enabling seamless integration with TensorFlow workflows. By leveraging cloud services, developers can maximise the potential of the A5000 GPU and achieve optimal TensorFlow performance without the hassle of managing hardware infrastructure.
The NVIDIA RTX A5000 GPU offers immense potential for optimising TensorFlow GPU efficiency. Its high core counts, large memory capacity, and support for Tensor Cores enable faster computations, efficient data transfer, and improved performance in deep learning tasks. This significantly impacts AI and machine learning, empowering researchers and developers to tackle complex problems and achieve breakthroughs in various domains.
Ready to harness the power of the NVIDIA RTX A5000 GPU for your AI and machine learning tasks? Take advantage of its capabilities on CUDO Compute, a powerful cloud computing platform. Sign up now and unlock the full potential of the A5000 GPU to accelerate your TensorFlow operations and achieve faster, more efficient results. Get started with CUDO Compute and the A5000 GPU today!
About CUDO Compute
CUDO Compute is a fairer cloud computing platform for everyone. It provides access to distributed resources by leveraging underutilised computing globally on idle data centre hardware. It allows users to deploy virtual machines on the world’s first democratised cloud platform, finding the optimal resources in the ideal location at the best price.
CUDO Compute aims to democratise the public cloud by delivering a more sustainable economic, environmental, and societal model for computing by empowering businesses and individuals to monetise unused resources.
Our platform allows organisations and developers to deploy, run and scale based on demands without the constraints of centralised cloud environments. As a result, we realise significant availability, proximity and cost benefits for customers by simplifying their access to a broader pool of high-powered computing and distributed resources at the edge.
