 Resources
Resources 
An important element that has led to the success of neural networks is optimization. Optimization in neural networks directly influences how well the network learns and generalizes from data. A core component of neural network training is the optimization of weights to minimize a loss function, which quantifies the difference between the network’s predictions and the actual target values.
Gradient descent is one of the most popular and effective techniques used in the optimization process. In this article, we will provide a detailed exploration of how gradient descent can be used to optimize your neural networks.
We'll start by understanding the fundamentals of gradient descent, delve into various gradient descent algorithms, and explore strategies for effectively using these methods to enhance the performance of your neural networks.
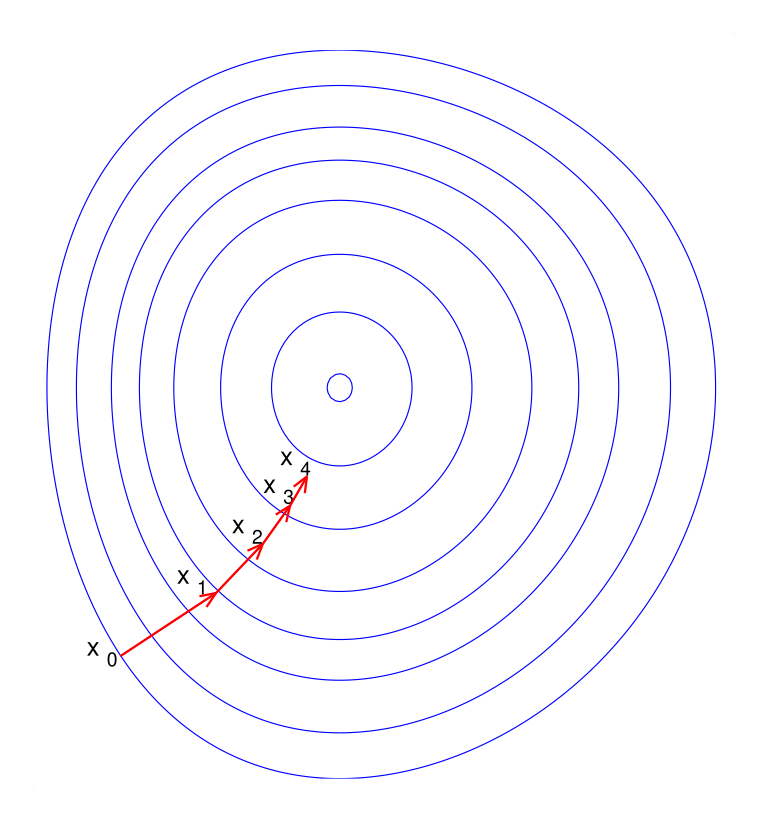 Source: Wikipedia
Source: Wikipedia
Before we discuss gradient descent, let’s give a high-level overview of optimization algorithms.
What are optimization algorithms?
Optimization algorithms are a class of algorithms designed to find the best possible solution to a given problem, typically by systematically adjusting variables or parameters to minimize or maximize a specific objective function.
Their core components include:
- Objective function: The mathematical function that quantifies the "goodness" of a particular solution. The goal is to find the values of the variables that result in the optimal (minimum or maximum) value of this function.
- Variables/parameters: These are the adjustable elements of the problem that the algorithm can modify to find the optimal solution.
- Constraints: These are optional limitations or restrictions on the variables' values.
Optimization algorithms typically follow an iterative process. They start with an initial guess or set of values for the variables and then evaluate the objective function using the current values of the variables.
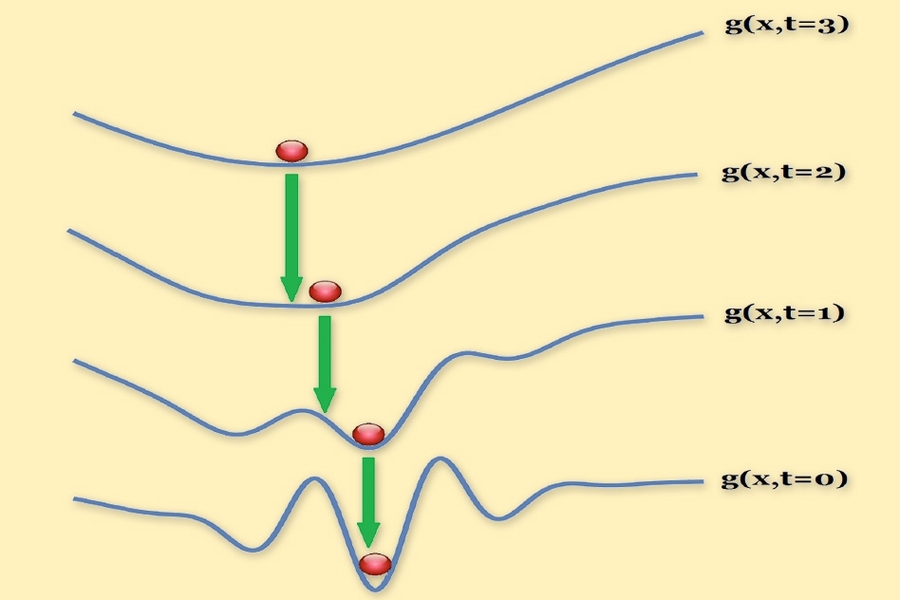 Source: MIT
Source: MIT
Next, they use information from the evaluation to update the variables in a way that is likely to improve the objective function value. These processes are repeated until a termination criterion is met (e.g., the improvement in the objective function is negligible, or a maximum number of iterations is reached).
There are many different types of optimization algorithms, each with its own strengths and weaknesses. Some common categories include:
- First-order algorithms: Rely on the objective function's first derivative (gradient) to determine the improvement direction.
- Second-order algorithms: Utilize the second derivative (Hessian) for potentially faster convergence but at a higher computational cost.
- Evolutionary algorithms: Inspired by natural selection, they involve a population of candidate solutions that evolve over time.
- Heuristic algorithms: Uses problem-specific strategies or rules of thumb to find good solutions quickly but without guarantees of optimality.
The choice of algorithm depends on factors like the nature of the problem, the available computational resources, and the desired level of accuracy.
CUDO Compute offers the latest NVIDIA GPUs and computational resources you need for your AI projects at affordable rates. You can quickly configure a cloud GPU like the NVIDIA H100. Get started now!
Now that we know optimization algorithms let’s focus on gradient descent.
What is gradient descent?
Gradient Descent is a first-order optimization algorithm that works by iteratively adjusting parameters in the direction of the negative gradient of the function at the current point, representing the direction of the steepest descent.
This process helps to minimize the objective function, usually defined as a loss or cost function in various applications. In neural networks, this function typically represents the loss, quantifying how well the network's predictions align with the actual values.
Here is what that means:
Gradient Descent's job is to find the "best" values for the parameters of a model or system. "Best" is defined by a function that measures how well the model is doing, which is the objective function or loss function in machine learning – lower loss means the model makes fewer errors.
 Source: Hyperskill
Source: Hyperskill
The primary goal of gradient descent is to find the parameters (weights and biases) that minimize this loss function, thereby improving the network’s performance. Gradient Descent adjusts the parameters in the direction of the negative gradient of the cost function concerning the parameters.
Let's delve deeper into the mechanics of Gradient Descent.
Understanding the Gradient
In neural networks, the gradient is a vector that points in the direction of the greatest rate of increase of the loss function. Each element of this vector represents the partial derivative of the loss function with respect to a particular parameter. Essentially, it tells us how much the loss would change if we were to make a small change to that specific parameter.
Gradient Descent aims to minimize the loss function. To achieve this, it updates the parameters in the direction opposite to the gradient. This is why we often refer to the "negative gradient." By moving in the opposite direction of the steepest ascent, we effectively move towards the direction of the steepest descent, thus reducing the loss.
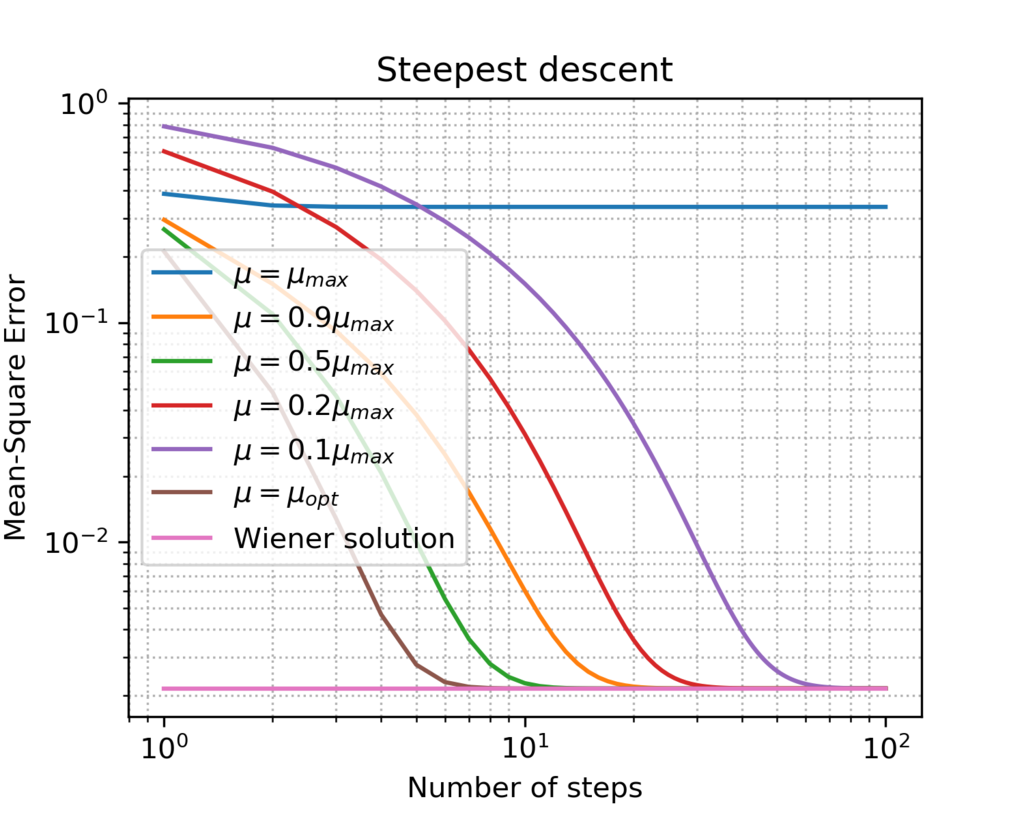 Source: Wikipedia
Source: Wikipedia
Now, let's explore the key elements of gradient descent, starting with the learning rate.
The Learning Rate
The learning rate is a hyperparameter that controls the size of the steps taken during each iteration of Gradient Descent. A larger learning rate means bigger steps, which can lead to faster convergence but also risks overshooting the minimum. Conversely, a smaller learning rate results in smaller steps, which may lead to slower convergence but is less likely to overshoot. Choosing an appropriate learning rate is crucial for the effectiveness of gradient descent.
The next element is the iterative update rule.
The Iterative Update Rule
The core update rule for Gradient Descent is:
new_parameter = old_parameter - learning_rate * gradient
This equation encapsulates the essence of gradient descent: we take the old parameter value, subtract a portion of the gradient (scaled by the learning rate), and obtain the new parameter value. We repeat this process for all parameters in the network, iteratively moving towards a set of parameters that minimize the loss.
For example, imagine the loss function as a landscape with hills and valleys. The goal of gradient descent is to find the lowest point in this landscape (the global minimum). The gradient acts as a compass, pointing uphill. By taking steps in the opposite direction of the gradient, we are essentially walking downhill, gradually approaching the valley floor.
In the next section, we will explore different variants of Gradient Descent and how they address some of the challenges associated with the basic algorithm.
Types of gradient descent algorithms
While the basic concept of gradient descent remains the same, there are several variations of the algorithm that offer different trade-offs in terms of speed, stability, and computational efficiency. Here are a few of them:
- Batch Gradient Descent: Batch Gradient Descent, also known as vanilla gradient descent, computes the gradient of the cost function concerning all training examples in the dataset, meaning that each step taken by the optimizer considers the entire dataset, making it computationally expensive for large datasets.
Advantages:
- Provides a stable convergence path due to the accurate estimation of the gradient.
- Suitable for convex problems where the cost function has a single minimum.
Disadvantages:
- Slow to converge on large datasets as it needs to process the entire dataset at each step.
- It can get stuck in local minima due to its deterministic nature.
Here is a simple code snippet of how it could be implemented:
import tensorflow as tf
# ... (Define your model, loss function, and dataset)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for epoch in range(num_epochs):
with tf.GradientTape() as tape:
predictions = model(X_train) # Forward pass
loss = loss_fn(y_train, predictions) # Calculate loss
gradients = ttape. Gradientloss, model.trainable_variables) # Compute gradients
optimizer.apply_gradients(zip(gradients, model.trainable_variables)) # Update weights
- Stochastic Gradient Descent (SGD): Stochastic Gradient Descent updates the parameters using a single training example at each step rather than the entire dataset. This introduces noise into the gradient estimates, leading to a more fluctuating convergence path.
Advantages:
- Faster iterations, making it suitable for large datasets.
- The noisy nature helps escape local minima and saddle points.
Disadvantages:
- High variance in the gradient updates can lead to unstable convergence.
- Requires careful tuning of the learning rate for effective optimization.
Here is a simple code snippet of how it could be implemented:
import tensorflow as tf
# ... (Define your model, loss function, and dataset)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for epoch in range(num_epochs):
for i in range(len(X_train)):
with tf.GradientTape() as tape:
predictions = model(X_train[i:i+1]) # Forward pass for a single example
loss = loss_fn(y_train[i:i+1], predictions)
gradients = ttape. Gradientloss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
- Mini-Batch Gradient Descent: Mini-Batch Gradient Descent combines the Batch and Stochastic Gradient Descent approaches. It updates parameters based on small random samples (mini-batches) of the dataset, balancing the stability of Batch Gradient Descent with the speed of SGD.
Advantages:
- Reduces variance in gradient updates, leading to a more stable convergence.
- More efficient use of computational resources with vectorized operations.
Disadvantages:
- Still requires careful tuning of mini-batch size and learning rate.
Here is a simple code snippet of how it could be implemented:
import tensorflow as tf
# ... (Define your model, loss function, and dataset)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
batch_size = 32
for epoch in range(num_epochs):
for i in range(0, len(X_train), batch_size):
with tf.GradientTape() as tape:
predictions = model(X_train[i:i+batch_size]) # Forward pass for a mini-batch
loss = loss_fn(y_train[i:i+batch_size], predictions)
gradients = ttape. Gradientloss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
Important Notes
- These snippets provide a basic illustration. In practice, you would likely use higher-level APIs like model.fit in Keras, which abstracts away some of the lower-level details.
- For advanced optimizers like Adam, you would simply replace tf.keras.optimizers.SGD with the corresponding optimizer class (e.g., tf.keras.optimizers.Adam).
- Hyperparameter tuning (learning rate, batch size, etc.) is crucial for achieving good performance.
The choice of gradient descent variant depends on various factors, including the dataset's size, the model's complexity, and the available computational resources. In practice, Mini-batch Gradient Descent is often the preferred choice due to its balance of speed and stability.
Challenges and pitfalls of gradient descent
Gradient descent, while effective, faces several challenges that can hinder model optimization. Recognizing these pitfalls helps in adopting appropriate mitigation strategies.
Local Minima and Saddle Points
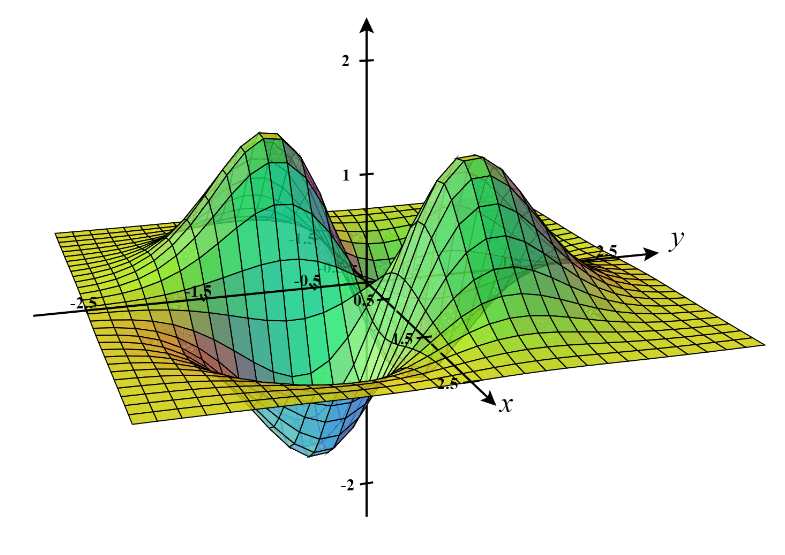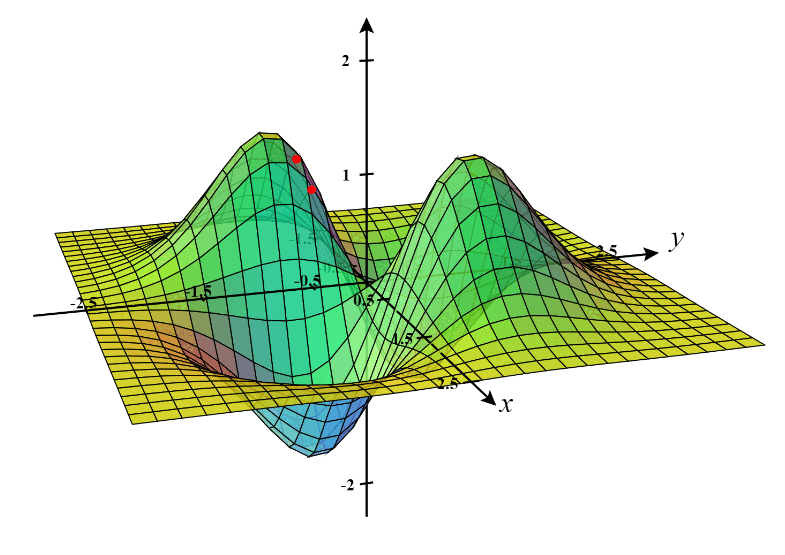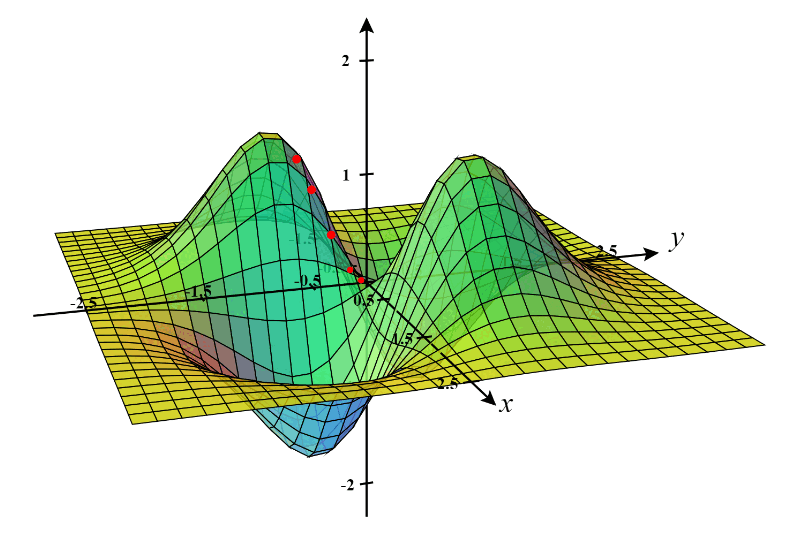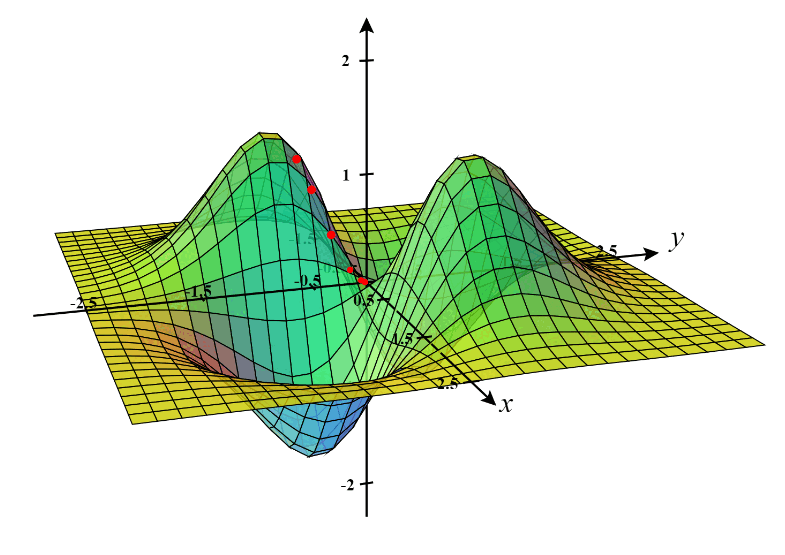
A local minimum is a point on a function's error surface (or loss landscape) where the function value is lower than at any nearby points but not necessarily the lowest possible value across the entire surface. In simpler terms, it is a "valley" in the loss landscape, but it may only be a local valley, not the deepest one (global minimum).
For neural networks, these minima correspond to specific sets of weights that lead to lower errors in the training data. Getting stuck in a local minimum means the algorithm might miss the global minimum (best solution). However, in high-dimensional spaces, many local minima can be as good as the global minimum.
On the other hand, a saddle point is a point on the error surface where the gradient is zero (no slope), but it is neither a local minimum nor a maximum. The surface has a "saddle" shape — it curves upward in one direction and downward in another.
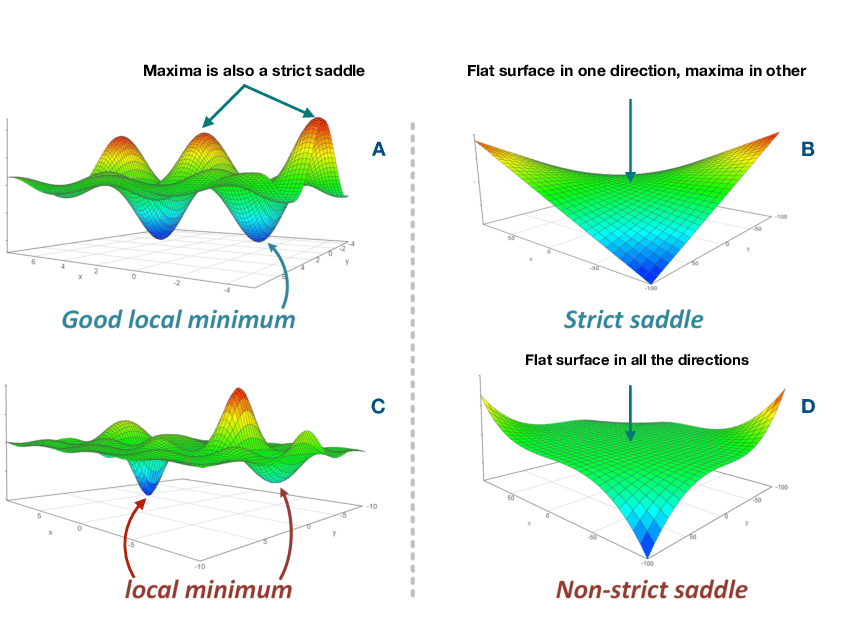 Source: Paper
Source: Paper
Saddle points are more problematic than local minima. They are flat regions where the gradients are close to zero, causing optimization algorithms like gradient descent to slow down or get stuck. This is particularly an issue in high-dimensional spaces, as there can be many saddle points.
Imagine hiking in a mountainous terrain. A local minimum would be a small valley that you find yourself in, even if it's not the lowest point in the entire range. A saddle point would be like a flat ridge between two peaks — you're not at the bottom of a valley, but you're also not at the top of a peak.
In neural networks, the challenge lies in avoiding getting stuck in these saddle points or inefficiently navigating around them during optimization.
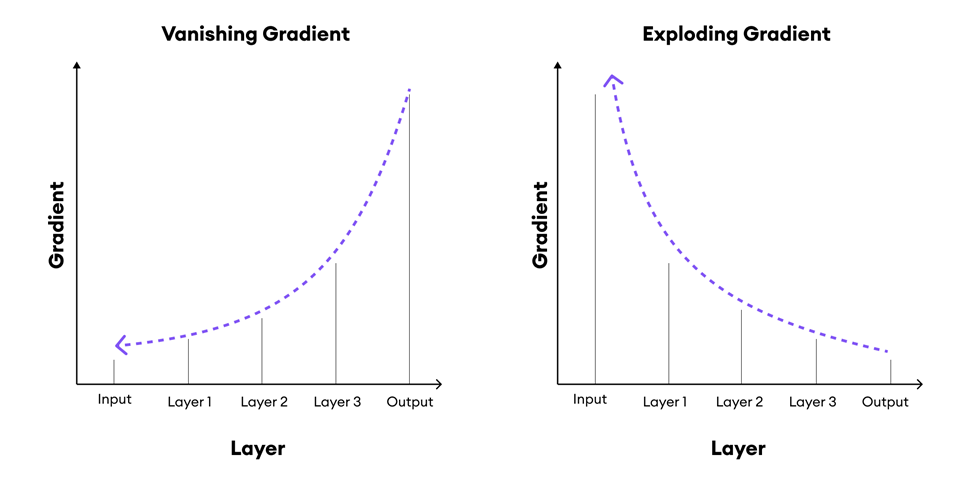
Vanishing and exploding gradients
In deep learning, the problems of vanishing and exploding gradients are well-known challenges, particularly in very deep networks and recurrent neural networks (RNNs). These problems occur during the backpropagation process, where gradients are calculated and propagated backward through the network to update the weights.
- Vanishing Gradients: In this case, the gradients shrink as they are propagated back through the network layers. If the gradients become too small, the weight updates during learning become negligible, effectively stopping the network from learning. Vanishing gradients are more pronounced in deep feedforward networks and RNNs when using activation functions like sigmoid or tanh.
- Exploding Gradients: This occurs when gradients grow exponentially as they are propagated backward, leading to excessively large updates to the network’s weights. Exploding gradients can destabilize the learning process, making it difficult for the network to converge.
These problems disrupt the effective training of deep networks, making it hard for them to capture complex patterns in data.
 Source: superannotate
Source: superannotate
Techniques to avoid vanishing and exploding gradients:
- Gradient clipping: Gradient clipping is a technique used to prevent the exploding gradient problem by limiting the magnitude of the gradients during backpropagation. RNNs, due to their sequential nature, are particularly susceptible to the exploding gradient problem because gradients are propagated through many time steps, amplifying their size.
Clipping helps stabilize training by keeping gradients within a manageable range. Here is how it works. Suppose the norm (magnitude) of the gradient exceeds a pre-defined threshold. In that case, gradient clipping rescales the gradient so that its norm equals the threshold, ensuring that the update step remains reasonable, preventing extreme weight changes.
- Careful initialization: Weight initialization strategies, like the He or Xavier initialization, are designed to keep the gradients within a reasonable range during the forward and backward passes, helping to avoid both vanishing and exploding gradients.
- Normalization: Techniques like batch normalization and layer normalization can help stabilize learning by normalizing the inputs to each layer, thus reducing the risk of exploding or vanishing gradients.
Advanced techniques for optimizing gradient descent
Several advanced optimization techniques have been developed to overcome the inherent challenges of basic gradient descent. These methods enhance the standard gradient descent by introducing momentum, adaptive learning rates, and other improvements.
Momentum:
Momentum builds upon the concept of accelerating Gradient Descent by considering the past gradients to smooth the optimization path. It helps overcome challenges like slow convergence near-flat regions.
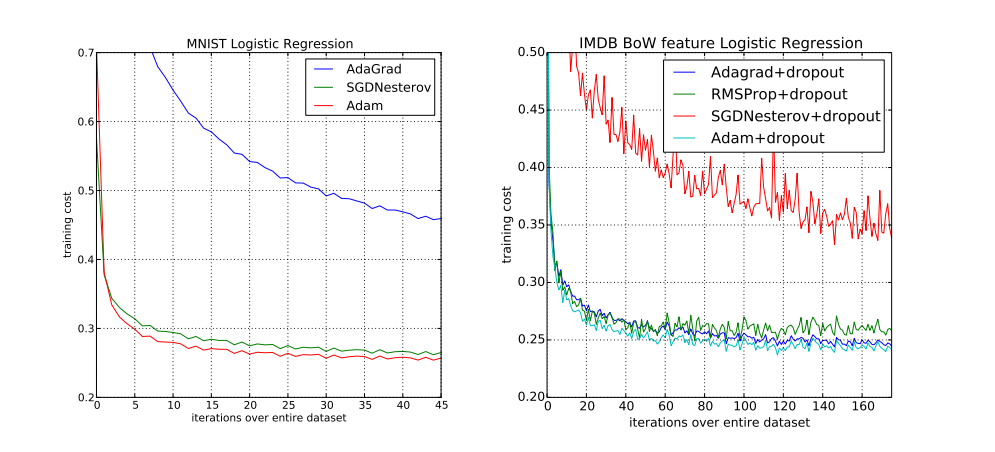
Adaptive learning rates: AdaGrad, RMSprop, and Adam
- AdaGrad: Adapts the learning rate for each parameter based on the magnitude of past gradients, favoring infrequent parameters.
- RMSprop: Modifies AdaGrad by decaying the past gradients, preventing the learning rate from becoming too small over time.
 Source: Paper
Source: Paper
- Adam (Adaptive Moment Estimation): Combines the benefits of RMSprop and momentum, using estimates of the first and second moments of the gradients to adjust the learning rate adaptively. Adam is widely used due to its robustness and efficiency in handling sparse gradients and non-stationary objectives.
Practical tips for optimizing your network with gradient descent
Here are some practical tips to optimize your neural network effectively using gradient descent:
- Choose the Right Algorithm: Depending on your dataset size, problem type, and computational resources, select an appropriate variant of gradient descent (Batch, SGD, or Mini-Batch).
- Tune the Learning Rate: Experiment with learning rate values and consider using learning rate schedules (e.g., decay over time) or adaptive algorithms like Adam to handle the changing nature of the gradients.
- Normalize Your Data: Data normalization (e.g., standardization) helps gradient descent converge faster by ensuring the gradients are on a similar scale.
- Use Regularization Techniques: Regularization methods like L1, L2 regularization, and dropout help prevent overfitting, ensuring that the optimized network generalizes well to unseen data.
- Monitor Gradient Values: Use tools to visualize and monitor gradients during training to identify issues like vanishing or exploding gradients early.
- Use Early Stopping: Implement early stopping to halt training when the validation performance ceases to improve, preventing overfitting and unnecessary training.
- Experiment with Momentum: Momentum-based methods can accelerate training and help escape local minima or saddle points, enhancing convergence speed.
Conclusion
Gradient Descent is an essential tool for neural network optimization, providing a systematic way to minimize errors and improve performance. By understanding the nuances of various gradient descent algorithms and employing advanced techniques, you can effectively optimize your network for superior results.
Whether dealing with large datasets, complex models, or intricate error surfaces, CUDO Compute offers the resources to help you optimize your neural network models. You can begin building your neural networks today onCUDO Compute with just a few clicks. Contact us for more information.
