 Resources
Resources 
In 2022, NVIDIA’s DGX SuperPod reference design drew an average of 25 kW per rack. By 2024, the GH200 generation pushed that to 72 kW. The GB200 NVL72, shipping in 2025, nearly doubles it again to 132 kW, and NVIDIA’s roadmap projects ~800 kW per rack for Rubin in 2027.
An industry that spent two decades migrating from 3 kW to 10 kW per rack is now confronting order-of-magnitude increases in density every 18 months. Roughly 60% of all servers being installed now support AI applications, up from a negligible share five years ago.
These systems require fundamentally different power delivery, cooling infrastructure, memory provisioning, and storage architecture than the general-purpose machines they are displacing. The global shortage of HBM, DRAM, and NVMe storage has doubled component prices and stretched procurement timelines to months, making installation mistakes expensive and difficult to reverse.
Getting AI hardware physically installed, correctly configured, and reliably maintained has become the rate-limiting factor for organizations’ ability to deploy and scale AI workloads. In this article, we cover what it takes to get it right: site readiness, rack installation, memory and storage provisioning, commissioning, and ongoing maintenance.
Site readiness and pre-installation planning
Power headroom that looked adequate on a specification sheet proves insufficient under sustained GPU load. For instance, cooling systems designed for 10 kW racks cannot be incrementally upgraded to handle 60 kW, let alone 130 kW, without a fundamental redesign of the thermal management chain from coolant distribution unit to chip because floor loading calculations inherited from traditional IT deployments do not account for the weight of a liquid-cooled AI rack, which can exceed 2,000 lb when fully populated.
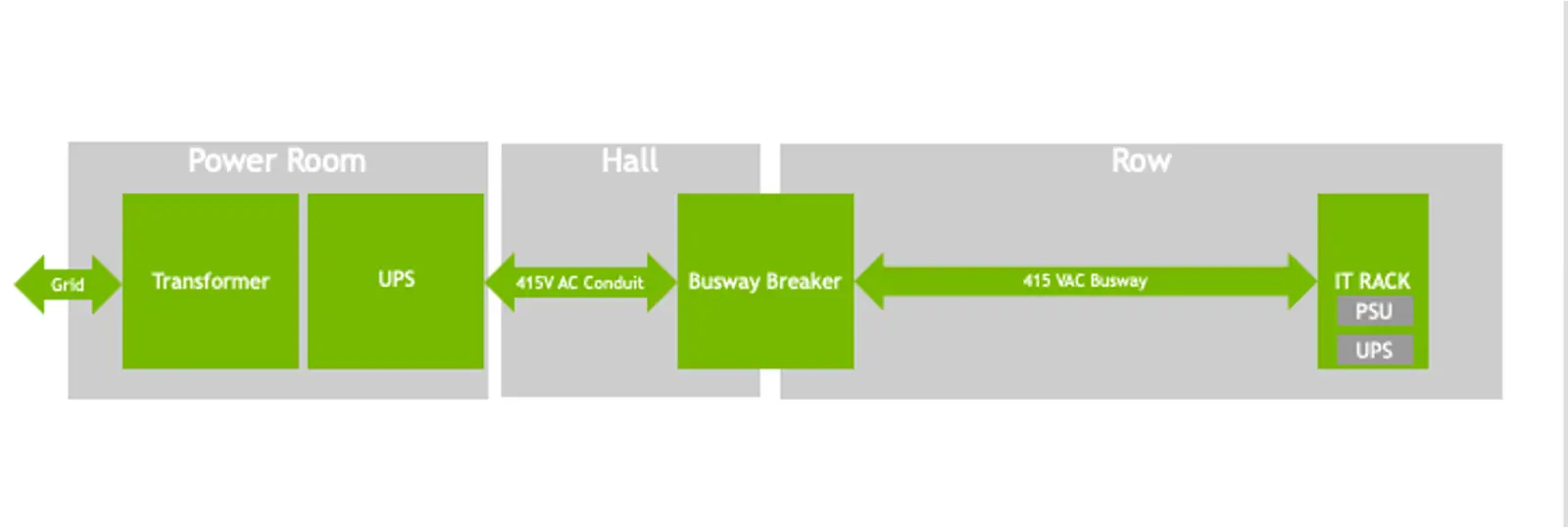
Current data center power architecture. Source: NVIDIA
AI racks drawing 30 to 130+ kW today, with clear trajectories toward 600+ kW within two years, require power distribution architectures that most existing data centers were never designed to deliver. NVIDIA’s emerging 800 VDC architecture, which replaces the 54 V in-rack standard that current Blackwell-generation systems use, supports racks ranging from 100 kW to over 1 MW on the same infrastructure backbone while delivering up to 5% improvement in end-to-end power efficiency and a projected 70% reduction in maintenance costs from fewer PSU failures.
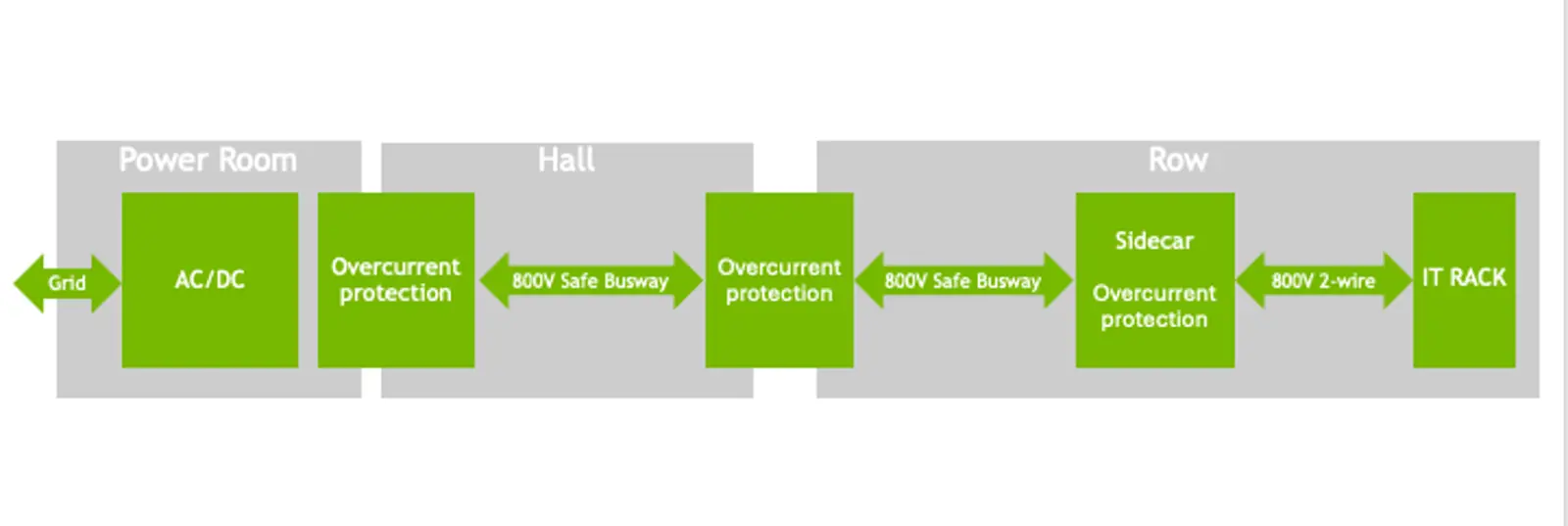
NVIDIA 800 VDC architecture minimizes energy conversions. Source: NVIDIA
At rack densities above 50 kW, the thermodynamic constraints of moving heat with air become insurmountable, and direct-to-chip liquid cooling transitions from an optional upgrade to a mandatory prerequisite. We have seen examples on both sides of the experience:
Meta learned this the hard way when deploying Air-Assisted Liquid Cooling across more than 40 million square feet of data center space with its Catalina rack design, which supports 140 kW with 72 GPUs, but getting there required scrapping multiple in-construction facilities for AI-optimized redesigns, a decision that yielded 31% cost savings but added months of delay.
Google’s seven-year operational dataset with liquid-cooled TPU pods, spanning 2,000+ pods at gigawatt scale, confirms that the technology delivers 99.999% uptime when properly commissioned, but achieving that reliability demands pre-installation work (coolant distribution unit sizing, manifold routing, secondary cooling loop design, leak detection system placement) that must be completed before a single accelerator is energized.
Network fabric topology is a constraint that can be easily overlooked until rack positions have already been committed. AI clusters built on InfiniBand or high-speed Ethernet (400G/800G) have strict optical path length requirements that directly determine how racks must be physically arranged relative to spine switches, and redundant interconnect paths require topologically separate cable trays to prevent correlated failures. These trays must be planned into the facility layout before concrete is poured or raised-floor tiles are laid.
GPU and accelerator rack installation
A standard 42U rack hosting NVIDIA DGX H100 servers, each drawing roughly 10.2 kW under sustained AI training load, fills very differently than one housing wafer-scale systems that occupy 15U per unit and require 30 kW+ per rack with closed-loop water cooling, or reconfigurable dataflow units that achieve competitive inference throughput at an average of 10 kW per rack but demand entirely different interconnect topologies and firmware initialization sequences.
Each architecture imposes its own constraints on U-space allocation, power shelf placement, coolant routing, and cable management, and assuming that GPU rack installation procedures generalize to all AI accelerator hardware is a reliable way to introduce deployment delays.
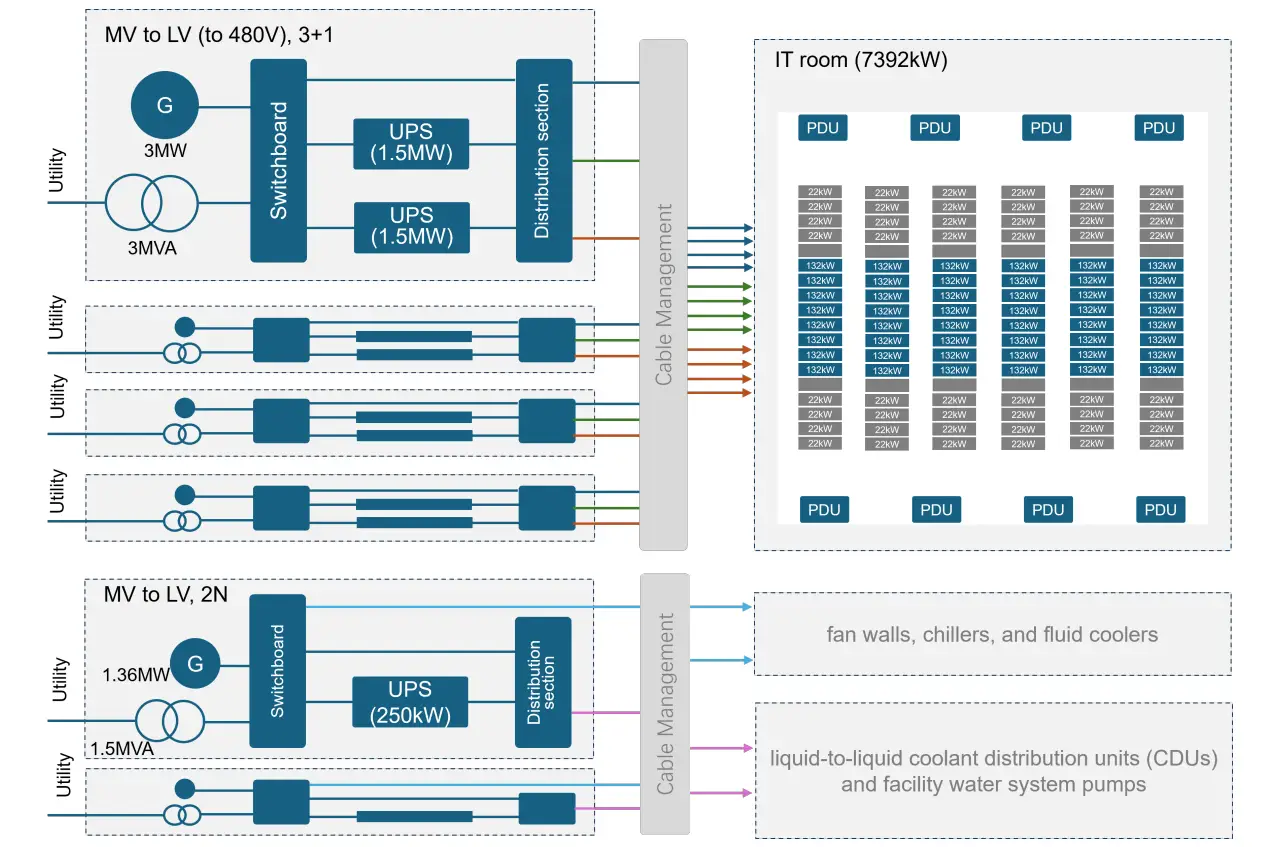
GPU cluster reference design implementation demonstrating comprehensive power distribution architecture (from Schneider RD109, 7392kW for IT racks, total power consumption approximately 10.5MW including cooling infrastructure). Source: Paper
NVIDIA’s GB200/GB300 NVL72 configuration uses up to eight power shelves per rack, and the inrush current generated by powering on a fully populated rack without proper sequencing can trip upstream breakers and cascade into facility-level power events.
Redundant PDU configurations (A+B feeds) must be validated under realistic load, not merely inspected for correct wiring, before production workloads are assigned, and facilities deploying multiple high-density racks simultaneously need staggered power-on procedures coordinated with the utility feed.
GPUs and accelerators must not be powered on until cooling loops are fully commissioned and verified, because a single failed manifold connection in a direct-to-chip liquid-cooling system can destroy accelerator hardware worth hundreds of thousands of dollars within minutes. Before any accelerator is energized, installation teams must complete:
- Leak testing at every joint in the liquid cooling loop
- Verification of coolant flow rates against the accelerator manufacturer’s specifications
- Confirmation of CDU thermal capacity at rated load
- For immersion-cooled deployments: verification of fluid dielectric properties, proper submersion depth, and heat rejection pathways that have no analog in air-cooled or direct-to-chip installations
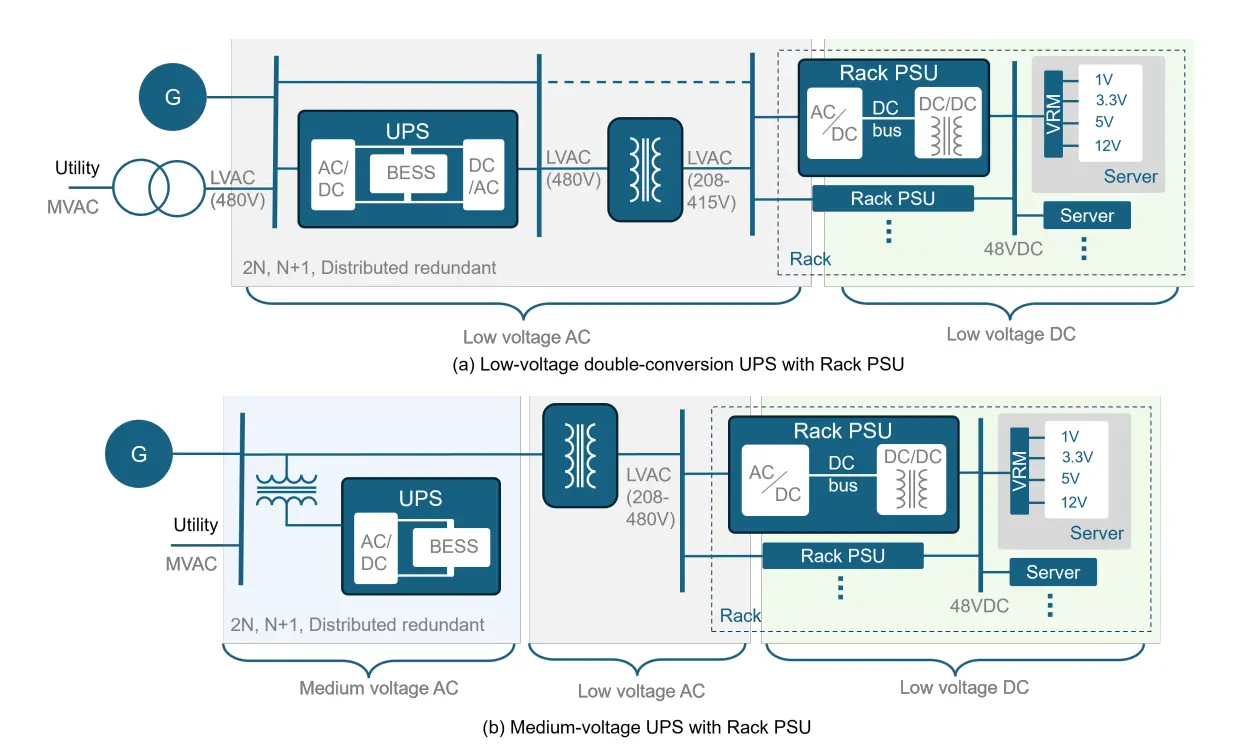
Power chain of GPU clusters (cooling excluded). The illustration shows multiple conversion stages (e.g., MVAC to LVAC, LVAC to DC, and final DC/DC stages) along with potential UPS integration. Source: Paper
NVLink cables, InfiniBand HCA connections, and high-speed Ethernet links have strict bend radius and length specifications, and violations cause cascading hardware issues:
- Signal degradation reduces effective interconnect throughput, with poorly cabled clusters losing 10-20% to retransmissions and error-correction overhead.
- Intermittent errors that appear only under production load remain difficult to diagnose because they do not reproduce during low-utilization testing.
- Thermal hotspots form where bundled cables restrict airflow to adjacent components, compounding cooling challenges that are already at the edge of design tolerances in high-density racks.
Memory architecture: the hierarchy that determines performance
GPU compute power has grown roughly 60,000-fold over the past 20 years, while DRAM memory bandwidth has improved by approximately 100-fold over the same period, creating a 600:1 disparity commonly referred to as the “memory wall,” which is the defining constraint on modern AI hardware performance.
HBM (High Bandwidth Memory) was developed to close that gap by stacking multiple DRAM dies atop a logic base die and connecting them via thousands of through-silicon vias (TSVs), enabling aggregate bandwidths that conventional DDR memory physically cannot achieve.

Source: Article
NVIDIA’s H100 GPU, equipped with HBM3E, delivers up to 3.35 TB/s of aggregate memory bandwidth and has become the standard for any system processing large language models with more than 100 billion parameters, but HBM is not a field-replaceable component as it is integrated directly into the GPU package via 2.5D interposer technology, meaning capacity is permanently fixed at procurement and determines the effective ceiling of workloads each node can support for its entire operational life.
DDR5-6000, which offers roughly 50% higher bandwidth than its DDR4 predecessor, serves as the buffer tier in an AI server’s memory hierarchy, handling pre-tokenization of input data, storing intermediate results during training, and absorbing KV cache overflow from HBM when context windows exceed the GPU’s on-package memory capacity.
Matching channel counts, ranks, and speeds to the specific CPU or accelerator’s memory controller configuration is an installation decision that matters more than most installation teams realize, and incorrect population (partially filling channels, mixing speeds, or leaving ranks unbalanced) can degrade memory bandwidth by 20% or more with no visible hardware error to diagnose. Standard monitoring tools will never surface the problem; the system simply underperforms its specifications indefinitely.
Source: Article
NVIDIA’s Dynamo Distributed KVCache Manager illustrates how all three memory tiers must work together: actively used key-value pairs stay in HBM, infrequently accessed pairs move to DDR system memory, and rarely accessed pairs offload to NVMe storage.
A system with ample HBM but insufficient DDR, or with adequate DDR but slow NVMe, will bottleneck at the tier boundary and force the GPU to recompute data it has already processed, producing high utilization metrics but low productive throughput.
Memory provisioning at installation must be sized across all three tiers in concert, and organizations facing the ongoing HBM/DRAM/NVMe shortage (which has doubled prices and stretched procurement to months) may need to deliberately overprovision DDR and NVMe tiers to compensate for constrained HBM availability.
Not every accelerator follows the GPU memory model. Wafer-scale engines integrate massive on-chip SRAM meshes (the WSE-3 contains 44 GB of on-chip SRAM distributed across 900,000 cores) that eliminate much of the off-chip memory bottleneck but impose their own constraints on external memory subsystem configuration, while reconfigurable dataflow units use three-tier memory architectures purpose-built for AI inference that behave differently from GPU memory hierarchies under the same workloads. When deploying heterogeneous accelerator fleets, there is no single memory installation template.
Storage installation: the tier most likely to strangle GPU performance
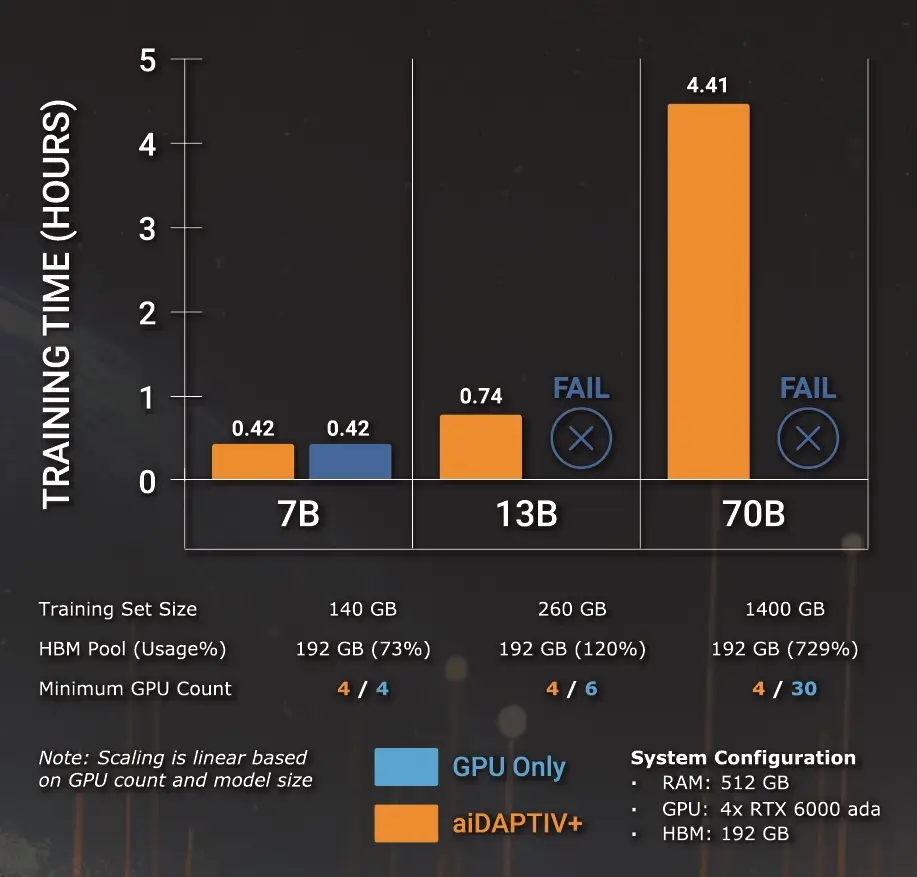
A benchmark study found that GPU clusters costing $2 to $3 million routinely deliver only $600,000 to $900,000 worth of productive compute, not because they lack accelerator capacity but because the storage subsystem cannot feed data to GPUs fast enough.
Most production AI clusters operate at 30 to 50% GPU utilization, with the rest idle while accelerators wait for data. Fixing the storage bottleneck could triple effective compute capacity on identical hardware, bringing utilization above 90% and reducing model deployment times from five minutes to fifteen seconds.
NVMe SSDs offer the lowest latency and highest throughput for the “hot” storage tier in an AI data center, handling model checkpoints, KV cache spillover, and data staging, but their installation requires decisions that directly determine whether they serve as a performance accelerator or a bottleneck.
Drive placement (colocated within GPU server chassis versus aggregated in dedicated storage nodes) affects PCIe lane availability and latency characteristics, and endurance requirements are where AI workloads diverge most sharply from general-purpose storage: training runs generate enormous sustained write volumes as checkpoints are saved at regular intervals, and consumer-grade or even standard enterprise NVMe drives can exhaust their write endurance within months.
Phison’s aiDAPTIV+ platform uses specialized SSDs that operate TLC flash in pseudo-SLC mode to achieve 100 drive writes per day endurance at 6 GB/s sustained sequential write bandwidth, which is how far AI storage hardware has diverged from conventional specifications.
Source: Article
Scaling storage beyond a single node requires dedicated fabric planning separate from the GPU interconnect network. NVMe-over-Fabrics (NVMe-oF) with rack-local switch topologies minimizes network hops and maintains performance consistency across multi-node training jobs, and storage traffic and GPU interconnect traffic must run on separate fabrics to prevent contention.
For large-scale distributed training on petabyte-class datasets, parallel file systems (Lustre, GPFS/Spectrum Scale, WekaFS) provide the concurrent throughput that thousands of GPU nodes require simultaneously, and installing these systems involves dedicated storage servers, high-speed network links, and careful tuning of stripe sizes and I/O schedulers that must be completed and validated before training workloads begin.
Source: NVIDIA
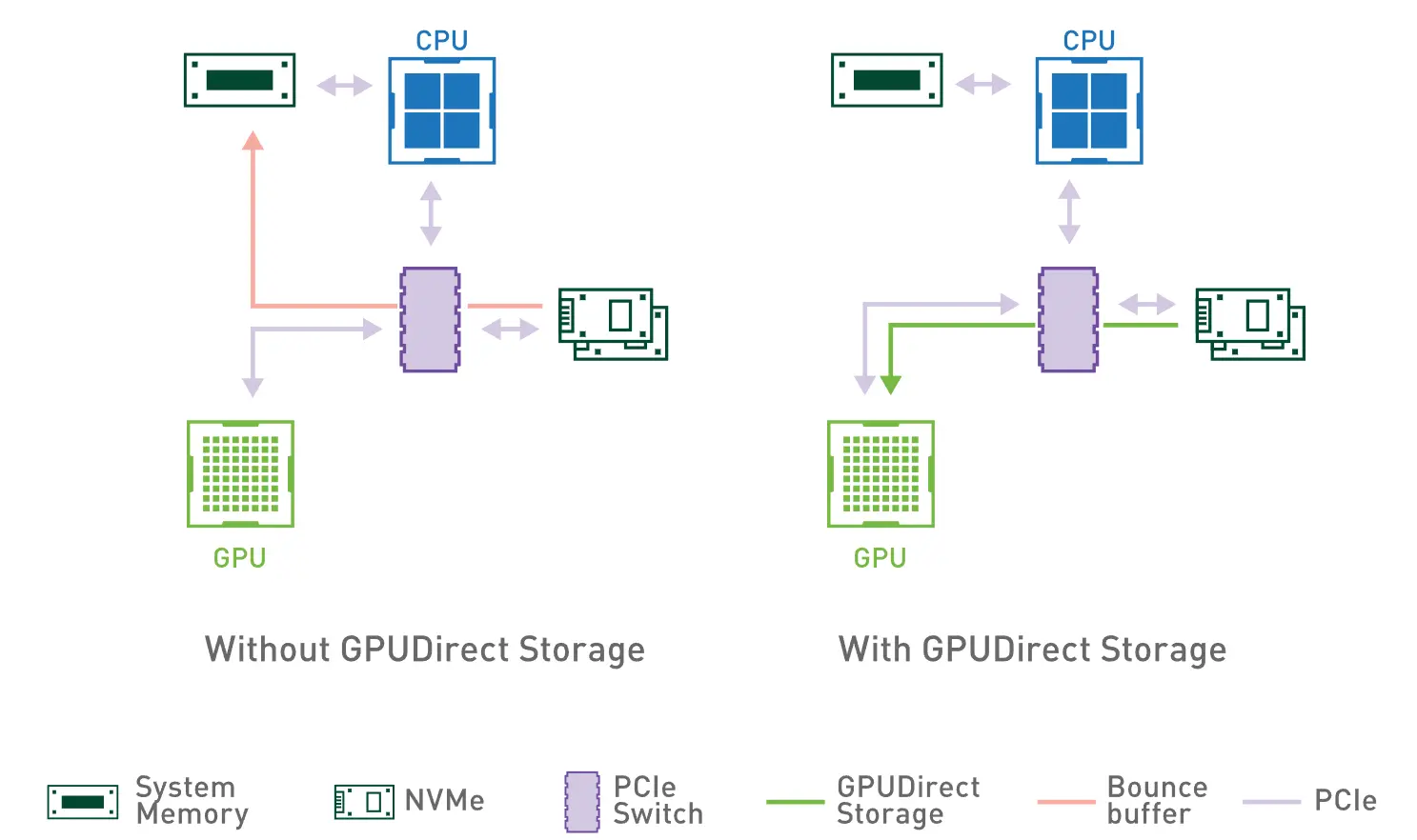
NVIDIA’s GPU Direct Storage (GDS) allows NVMe SSDs to transfer data directly into GPU memory, bypassing the CPU and system memory entirely, but enabling it during installation requires specific NVMe controller compatibility, kernel driver configuration, and PCIe topology verification beyond standard storage deployment procedures.
When operating in regulated industries where data integrity and auditability are contractual requirements, storage installation must additionally account for encryption at rest across all storage tiers, immutable audit trail logging, and checkpoint integrity verification — requirements that add complexity to the storage architecture but are non-negotiable for deployments in defense, healthcare, and financial services environments.
Commissioning, validation, and burn-in
A GPU that passes individual diagnostics may throttle under sustained multi-node training load because the cooling system cannot dissipate the aggregate heat of a fully loaded rack when ambient temperature rises above design assumptions, and an NVMe drive that benchmarks correctly in isolation may introduce latency spikes when competing for PCIe bandwidth with GPU interconnect traffic under realistic workload conditions.
These interaction failures are invisible to component-level testing, which is why most deployment timelines slip between physical installation and production readiness.
Thermal validation must be conducted under sustained compute load, not at idle or under brief stress tests, because GPU clusters exhibit thermal behavior that only manifests after hours of continuous operation at rated power draw.
Running a representative multi-node training workload for 48 to 72 hours while monitoring per-GPU junction temperatures, coolant inlet and outlet differentials, and CDU capacity utilization is the minimum to confirm the cooling infrastructure can sustain production workloads without thermal throttling.
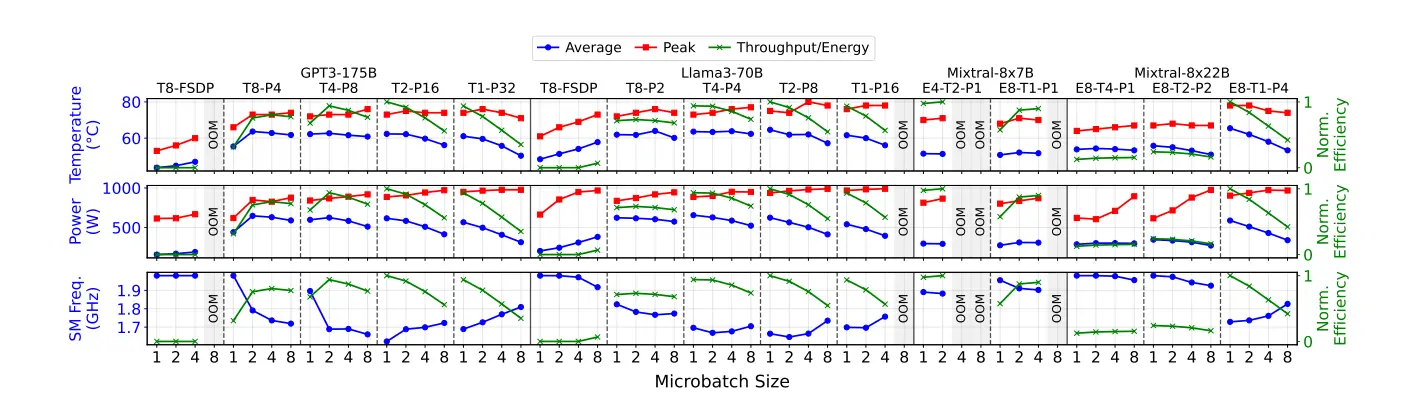
GPU power, temperature, and clock frequency on the H200 cluster across models, parallelism configs, and microbatchsizes. Activation recomputation enabled. Efficiency normalized per model (best = 1). Source: Paper
Any GPU that throttles during this validation period will throttle in production, and the root cause — whether inadequate coolant flow, a partially obstructed manifold, or an undersized CDU — is far cheaper to address before production data enters the system.
A single underperforming link in an all-reduce training topology degrades the entire cluster’s performance to the speed of its slowest connection, so every fabric link must be tested at rated bandwidth using traffic generators that simulate realistic AI communication patterns (gradient synchronization, parameter server updates, collective operations) rather than simple ping or throughput tests.
Memory diagnostics should scan all installed DIMMs for single-bit errors indicative of early-stage degradation, and NVMe drives should undergo sustained write tests to verify both throughput and endurance under AI-representative I/O patterns.
For regulated-industry deployments serving government, healthcare, or financial workloads, commissioning extends beyond hardware performance to include verification of:
- Encryption at rest across all storage tiers
- Network segmentation between tenants
- Access control configurations enforcing least-privilege principles
- Audit trail functionality provides immutable records of system access and data movement
These checks must be completed and documented before any production data enters the system because retroactively demonstrating compliance after data has been processed on uncertified infrastructure is a far more expensive and legally uncertain proposition.
Ongoing maintenance and operational reliability
A frontier model training run does not burst and subside like a traditional batch job — it runs continuously for weeks or months across thousands of accelerators, and any hardware failure during that period can invalidate days or weeks of accumulated computation if the checkpoint and recovery infrastructure is not properly maintained.
This makes AI hardware maintenance fundamentally different from traditional IT maintenance, where scheduled downtime windows are routine and individual server failures affect only the workloads on that server.
GPU clusters generate extensive telemetry (per-GPU thermal readings, power draw at millisecond resolution, ECC error counts in HBM and system memory, and CRC error rates on interconnect links) that, when properly monitored, can predict failures before they manifest as workload interruptions.
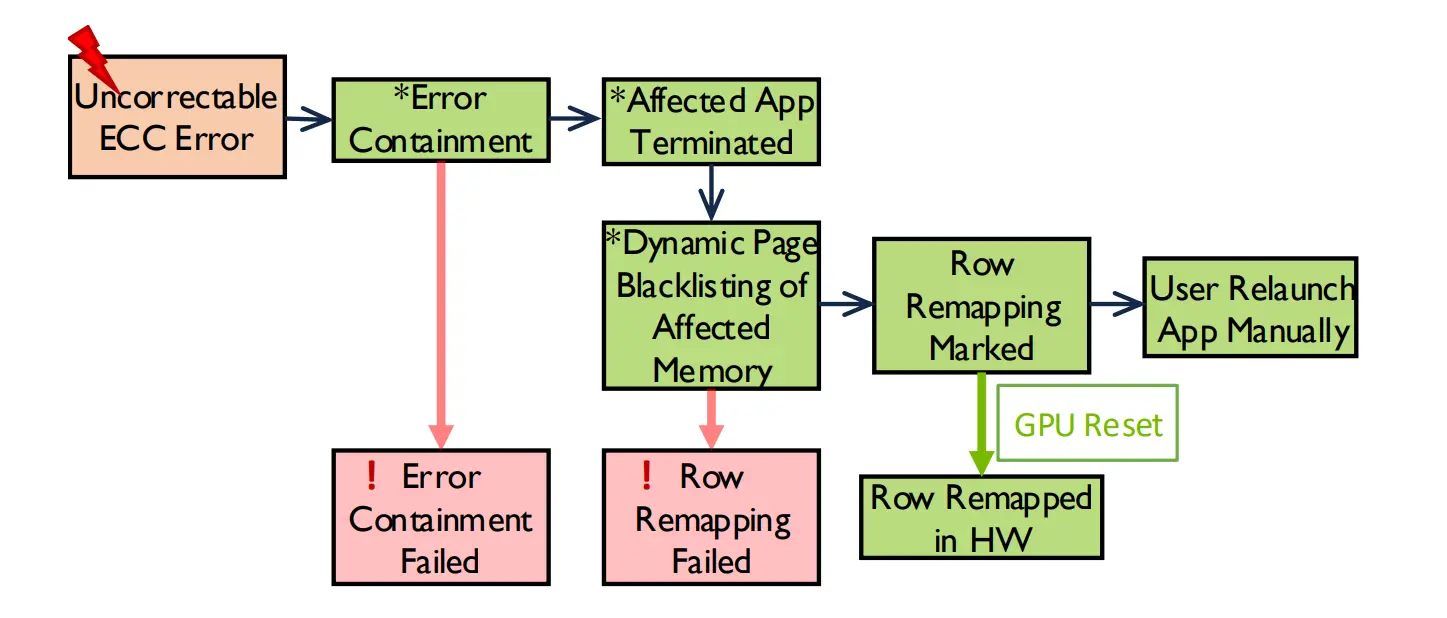
NVIDIA memory error recovery process for A100 and H100 GPUs. Source: Paper.
Tracking the ECC error rate on a specific GPU’s HBM over time reveals degradation curves that indicate when the memory will begin producing uncorrectable errors, and scheduling a proactive replacement during a planned checkpoint window costs hours rather than the days that an unplanned failure during a training run would consume. Relying on periodic manual inspection rather than continuous automated monitoring are discovering that AI hardware fails in patterns that quarterly maintenance visits cannot catch.
Infrastructure serving AI workloads in regulated industries must meet concurrent maintainability standards (Tier 3 or higher under TIA-942 or EN50600 Class 3), meaning any single component, be it a cooling unit, UPS module, power feed, or network switch, must be serviceable without shutting down the cluster.
For defense, healthcare, and financial services deployments, this is not a best practice recommendation but a contractual and regulatory requirement, and concurrent maintainability is determined at installation design time, not during operations. A cluster that was not designed with redundant cooling loops, dual power feeds, and multiple network paths cannot be retrofitted to meet these standards without essentially rebuilding the infrastructure.
Direct-to-chip and immersion cooling systems require maintenance regimes that have no precedent in air-cooled data center operations:
- Coolant: The quality must be continuously monitored for conductivity, pH, and particulate contamination, as any of these can degrade heat transfer performance or corrode loop components over time.
- Pump and CDU motors: They require scheduled servicing on intervals determined by operational hours rather than calendar time, since AI workloads run these systems at near-continuous duty cycles that accelerate wear.
- Manifold seals and quick-disconnect fittings: These must be inspected for micro-leaks that are invisible to the eye but detectable through pressure decay testing.
Meta’s facility-wide transition to liquid cooling required the development of entirely new maintenance procedures and retraining operations staff. When deploying liquid cooling for the first time, anticipate a similar investment in operational capability or plan to partner with specialized maintenance providers.
Lead times for GPUs, HBM-equipped accelerator modules, high-endurance NVMe drives, and InfiniBand HCAs can stretch to months under current supply conditions, and an organization whose SLA commits to 99.99% uptime cannot maintain that commitment if a failed GPU requires a 12-week procurement cycle to replace.
On-site spares inventories must be calibrated to failure rate projections for each component class, and for regulated-industry deployments where downtime carries compliance penalties as well as operational costs, the economic calculation overwhelmingly favors maintaining larger spares pools than a traditional cost-optimization model would suggest.
Getting AI hardware installed correctly and maintained reliably is a problem that compounds with every shortcut at installation becoming a recurring operational cost, and every missed maintenance signal a training run interruption. If your team is planning a GPU cluster deployment, scaling an existing installation, or struggling with utilization and reliability on hardware that should be performing better, talk to us. We help organizations get AI infrastructure right the first time — and keep it running.
