 Resources
Resources 
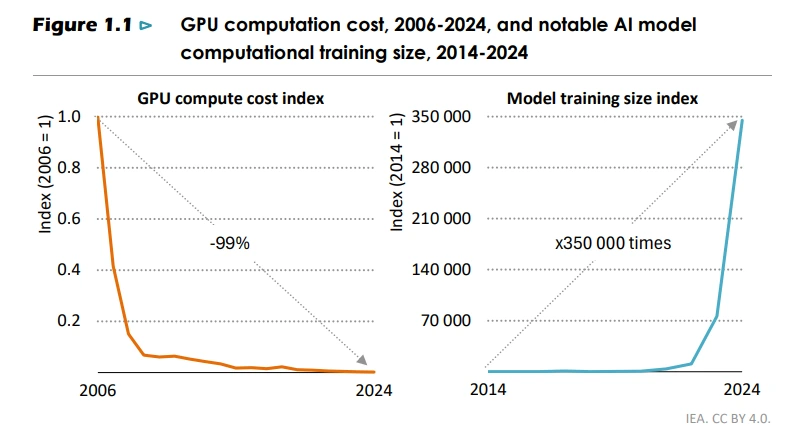
For most of computing history, the relationship between software ambition and physical infrastructure held a rough equilibrium. Software got more demanding, hardware got more efficient, and the two advanced roughly in step. That equilibrium has now broken.
The equilibrium held across three distinct eras, beginning with the mainframe, which was vertical and self-contained. Running a larger workload meant a larger machine in a larger room with a larger power supply, though the physical constraints stayed manageable because the computational ambitions were modest.
Client-server architectures distribute workloads across racks of commodity hardware, creating enterprise data centers with raised-floor rooms that draw 2 to 5 kW per rack and are cooled by air-conditioning units pushing cold air under the raised floors. The infrastructure challenge in both eras was more logistical than physical.
Cloud computing appeared to resolve the relationship permanently. Beginning with Amazon Web Services in the mid-2000s and accelerating through the 2010s, the cloud abstracted infrastructure entirely. Companies migrated to hyperscale data centers operated by Amazon, Google, Microsoft, and Alibaba.
Workloads grew enormously over the same period across streaming, social media, e-commerce, and enterprise SaaS, but total data center power consumption stayed roughly flat for more than a decade. Efficiency gains in servers, storage, and cooling absorbed almost all of the added load. PUE ratios fell, virtualization packed more work onto each physical server, and the industry consolidated millions of inefficient enterprise server closets into a smaller number of large, optimized facilities.
The cloud taught a generation of technology leaders to treat infrastructure as someone else’s problem. Power, cooling, land, and water were the operator’s concern, and the customer rarely saw them. Cloud workloads also scaled horizontally, so more users meant more servers spread across more racks and availability zones. No single workload pushed any one physical system past what it was designed to handle.
The architectural break
AI broke that equilibrium, and the shift it produced is architectural, economic, and physical at once. It invalidates the assumptions that governed data center design for the previous fifteen years.
Where cloud workloads scaled horizontally across commodity servers, AI workloads scale vertically into dense, tightly coupled clusters. A single training run may occupy thousands of GPUs, interconnected by high-bandwidth fabrics that demand physical proximity, drawing sustained power loads that dwarf anything the cloud era produced. Where a cloud server rack draws 7 to 15 kW, a modern AI rack equipped with current-generation GPUs draws 40 to 60 kW, with next-generation configurations approaching 100 to 200 kW with direct liquid cooling. Systems on the near-term roadmap will push higher still.
This is an order-of-magnitude increase in thermal density, and it cascades through every layer of the physical infrastructure. Electrical distribution systems designed for cloud-era loads cannot deliver the power; cooling systems designed for air-cooled racks cannot dissipate the heat; structural floors designed for lighter equipment cannot bear the weight; and network fabrics designed for loosely coupled workloads cannot deliver sufficient bandwidth. The design assumptions for all four subsystems were the same, and they are now all wrong.
The efficiency gains that kept cloud-era power demand flat have already largely occurred. Virtualization, PUE improvements, and server consolidation were one-time structural shifts rather than repeatable optimizations.
There is no equivalent efficiency dividend waiting in the wings for AI workloads. When a training run requires thousands of GPUs operating at near-maximum utilization for weeks or months, no virtualization trick can make the power demand disappear.
The scale of AI demand
The International Energy Agency estimates that data centers consumed approximately 415 TWh of electricity globally in 2024, roughly 1.5% of total global consumption. By 2030, that figure is projected to more than double to 945 TWh, slightly exceeding Japan’s entire annual electricity consumption.
The United States alone accounted for 45% of global data center electricity use in 2024. By the end of the decade, the IEA expects the country to consume more electricity for data centers than for the production of aluminum, steel, cement, chemicals, and all other energy-intensive goods combined.
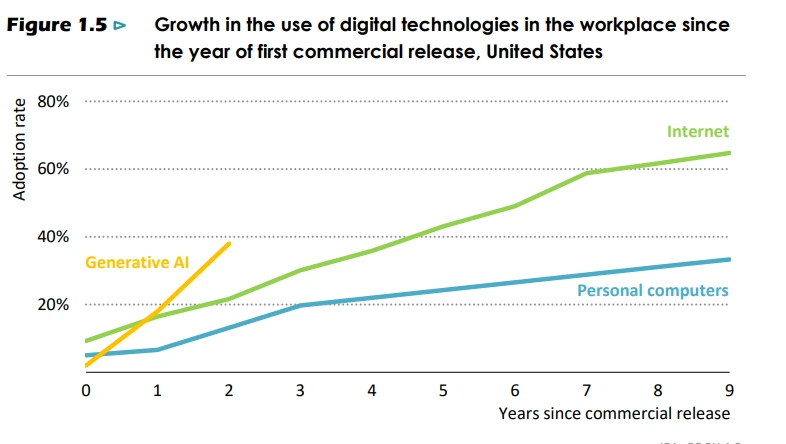
These numbers are driven overwhelmingly by AI: training a model comparable in scale to GPT-4o, a system already several cycles out of date, required a sustained power draw of 20-25 MW for approximately 3 months.
By 2028, individual frontier training runs are projected to require 1 to 2 GW of sustained power, and by 2030, estimates put a single training run at 4 GW, equivalent to the output of several large power stations dedicated to one computational task.
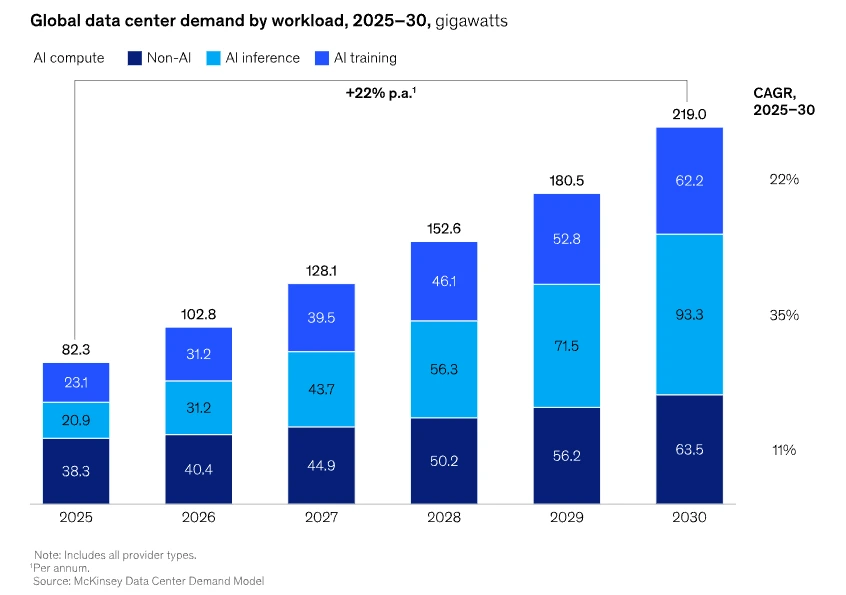
Training is episodic, while inference runs continuously. Deploying frontier models for real-time use across global user bases requires a distributed infrastructure spanning continents, with each node managing the thermal densities and power loads associated with dense GPU clusters. The infrastructure must support both workload types simultaneously, and inference demand scales with adoption, so every new user, product integration, and enterprise deployment adds sustained load.
Training can, in principle, be scheduled, relocated, and batched. Inference cannot, because it runs where users are, when they need it, at whatever density the models require. The infrastructure for inference must be local, always-on, and built to handle peak demand, which means it must be overbuilt relative to average utilization, exactly the opposite of the efficiency logic that governed the cloud era.
Why software optimization will not close the gap
A common objection is that software will catch up: models will become more efficient, algorithms will improve, distillation and quantization will reduce the hardware required for inference, and architectural innovations will lower the compute cost per unit of intelligence.
This holds at the level of individual models but not at the level of aggregate demand, because every efficiency gain in AI has historically been reinvested in capability. When training becomes cheaper per unit of compute, organizations train larger models, train more frequently, and expand the scope of what they attempt.
When inference becomes cheaper, they deploy to more users, integrate into more products, and serve more complex queries. Efficiency improvements at the component level, therefore, do not reduce total demand when the competitive landscape rewards capability above all else.
The cloud era avoided this dynamic because cloud workloads were, by and large, serving established markets. Streaming video, email, and e-commerce had addressable markets that, while enormous, were bounded. The workloads grew, but they grew into a finite space, and efficiency could keep pace.
AI capability has no obvious ceiling, and the pressure to push toward it is intense. The economic incentive structure guarantees that any efficiency gain will be consumed by increased ambition. More efficient training produces more capable models, which generate more demand for inference, which requires more infrastructure. The feedback loop runs in one direction, toward more power, more cooling, more land, and more capital.
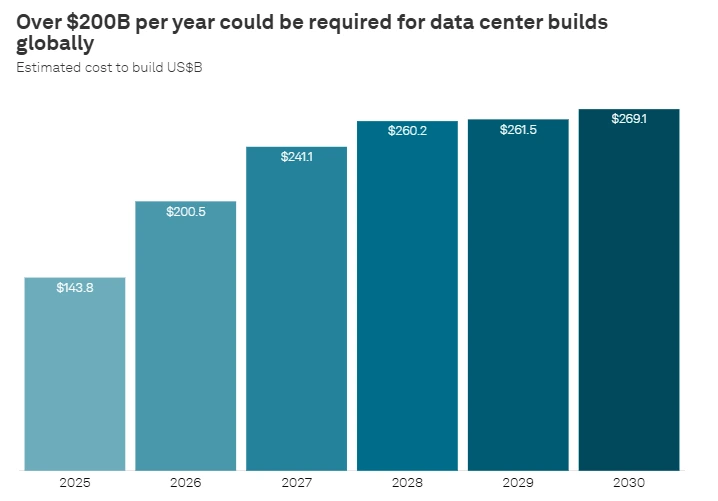
The capital expenditure patterns of the companies building AI infrastructure already reflect this. Hyperscaler capital spending on data centers has surged from under $150 billion in 2024 to projected figures exceeding $600 billion in 2026, with cumulative AI infrastructure investment expected to surpass $2 trillion by 2030. That capital is flowing because the demand curve for AI compute is steeper than anything the cloud era produced, and because the physical systems required to meet it are more expensive, more complex, and slower to build.
Infrastructure timelines now exceed product cycles
There is a final structural asymmetry that separates the AI era from everything that preceded it. In every previous era of computing, infrastructure could be provisioned faster than software demanded. Mainframes were delivered in months and client-server racks in weeks, and cloud capacity expanded continuously through hyperscaler capital programs that comfortably outpaced demand.
AI infrastructure operates on the opposite timeline, with a hardware cycle that runs on a 12- to 18-month cadence and a generation of GPUs that can move from announcement to obsolescence in under three years.The infrastructure required to house those GPUs operates on a fundamentally different clock. Securing land, obtaining planning permission, and completing environmental assessments takes years. Grid connections in established data center markets now involve multi-year queues, reaching seven years in parts of Northern Virginia, with comparable timelines emerging across European legacy hubs.
Transmission operators in the United States reported more than 2,600 GW of proposed generation and storage capacity awaiting grid connection by late 2024, more than twice the country’s installed capacity. Purpose-built power generation, whether natural gas, solar, nuclear, or hybrid, adds further years to the development timeline.
The result is a structural mismatch across the stack, where compute refreshes on a faster cycle than the buildings that house it, the buildings complete faster than the power that feeds them, and that power connects faster than the grid can deliver it. Each layer runs on a longer timeline than the one above it, which creates a cascading constraint that no single investment can resolve.
By the time a facility designed for today’s GPU generation is operational, the hardware it was built to house may be two generations old, its thermal requirements changed, its power density increased, and its networking fabric possibly incompatible.
An infrastructure project conceived in 2025, energized in 2028, and fully operational in 2029 will need to accommodate hardware that does not yet exist, and the design decisions that determine whether it can are being made now, years before the hardware specifications are finalized.
The organizations that navigate this mismatch will be the ones that build infrastructure flexible enough to accommodate a range of futures, rather than those that predict GPU architecture most accurately. That means modular power, adaptable cooling, and structural capacity designed for density headroom rather than current specifications.
What comes next
This is the context in which we undertook the largest independent survey of AI infrastructure decision-makers to date. In February 2026, we surveyed 701 senior professionals with direct responsibility for AI workload and infrastructure decisions across the UK, the United States, and six European markets. In parallel, we conducted in-depth interviews with practitioners across fifteen organizations responsible for deploying and operating AI workloads at scale.
The findings are published in Land • Power • Compute, a report that maps the physical constraints on AI scaling as they exist today, drawn from the operational reality reported by the people making the decisions rather than from projections or forecasts.
The title reflects the hierarchy that has emerged, in which land that is permitted, connected, and serviceable determines where AI infrastructure can exist. Power that is available, affordable, and delivered on time determines whether it can operate. Compute, meaning the GPUs, accelerators, and networking that attract the headlines, comes last, because it is useless without the physical foundation beneath it.
The bottleneck has moved, and the report shows where it went. Land • Power • Compute publishes on CUDO Compute.
