 Resources
Resources 
Advancements in graphic processing unit (GPU) technology have changed how we process memory-intensive tasks like AI development and high-performance computing (HPC). As discussed recently, historically, GPUs were utilized primarily to enhance video gameplay by rendering graphics smoothly and efficiently.
However, their use has changed over the years. Today, GPUs are being repurposed and used for more intensive computational tasks that Central Processing Units (CPUs) can not easily handle.
NVIDIA has long been at the forefront of GPU technology, offering solutions that accelerate computing tasks across various fields, including gaming, scientific research, artificial intelligence (AI), and machine learning (ML).
Two of NVIDIA's standout products in this space are the A100 and V100 GPUs. These GPUs are designed to cater to high-performance computing demands yet are tailored to slightly different market segments and user needs.

The A100 GPU is one of NVIDIA's latest GPUs, designed with the latest technological advancements to provide unparalleled computing power. On the other hand, the V100, while slightly older, remains a powerful option for those looking to boost their computational capabilities.
In this article, we will delve into the intricacies of these two powerful pieces of hardware, and compare them across multiple areas, including performance, AI and ML capabilities, cost, and application suitability. This comparison will provide a clear picture of which GPU may best suit specific tasks and budgets.
Overview of NVIDIA V100
The NVIDIA V100 GPU was introduced in 2017 and set a new HPC and AI acceleration standard. It is built on the Volta architecture, which was a huge leap from its predecessor (Pascal), and brought substantial improvements in performance and efficiency.
The V100 was designed to address the growing needs of AI, machine learning, and scientific computing, offering a solution for memory-intensive problems. It introduced Tensor Cores, a feature designed to accelerate AI applications, enabling the V100 to exceed the 100 teraFLOPS (TFLOPS) barrier in deep learning performance.
This was a substantial leap forward from previous generations, as the V100 is designed to provide high-speed interconnect linking and support for extensive memory bandwidth, making it easier to manage and process large datasets efficiently.
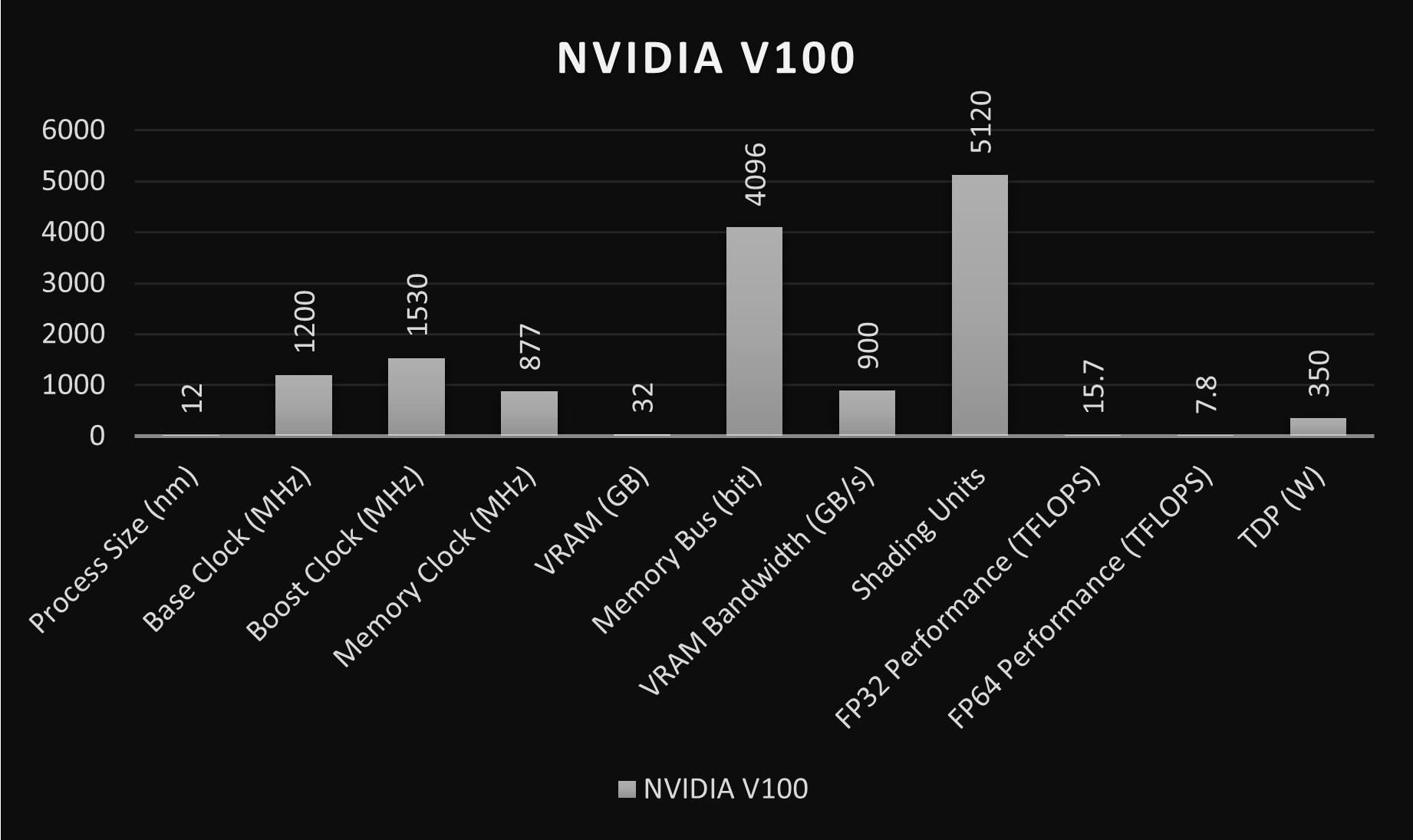
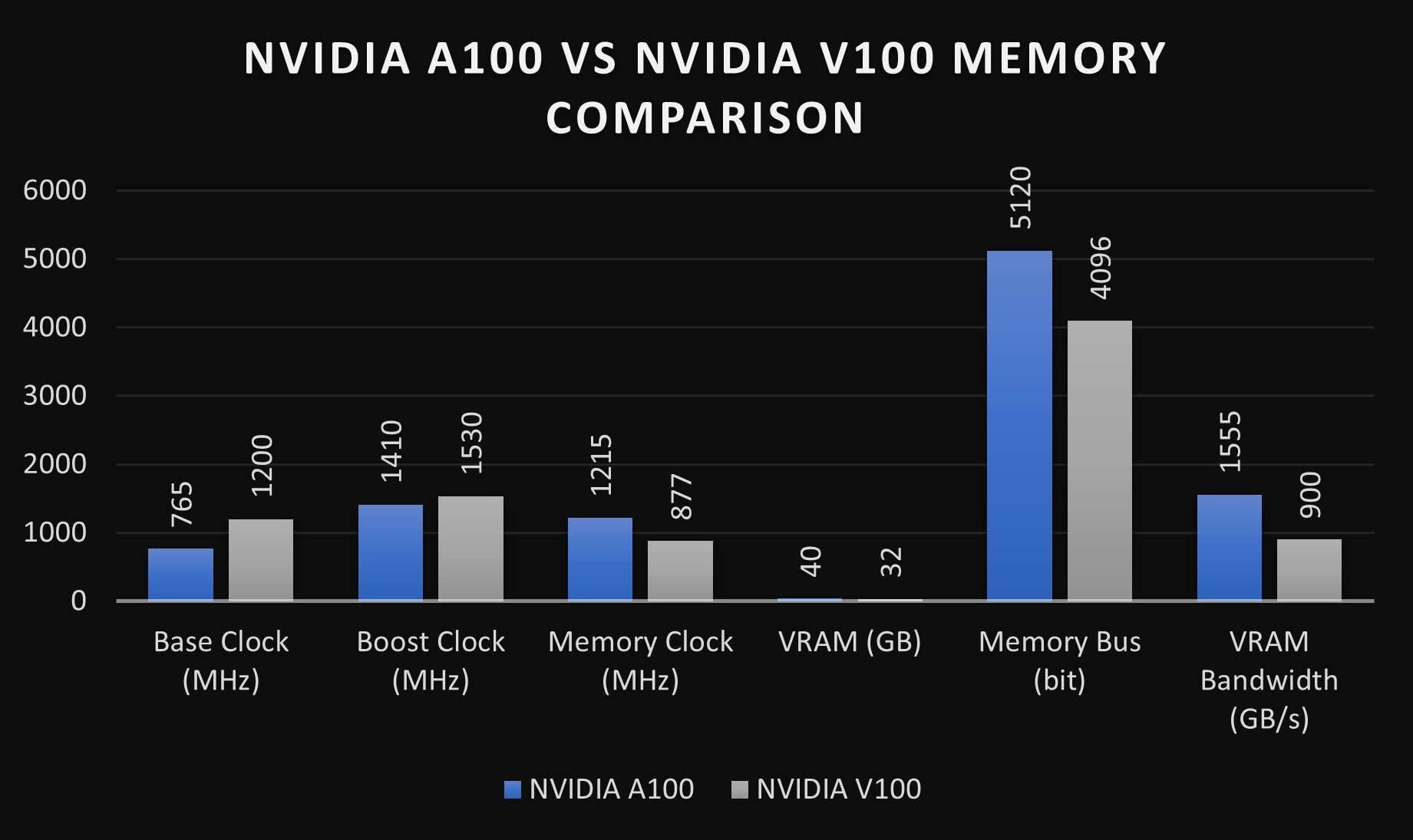
As discussed previously, the V100 features 5,120 CUDA cores and 640 Tensor cores, offering unparalleled computational power at its release. It has 32GB or 16GB of second-generation High Bandwidth Memory (HBM2), supporting memory bandwidths of up to 900 gigabytes per second (GB/s). While the memory capacity and bandwidth are less than the A100, they were groundbreaking at the V100’s launch and remain competitive for various applications.
To read more on the NVIDIA V100 benchmarks, read our V100 GPU Deep Learning with Caffe. To use the NVIDIA V100 for AI development without upfront payment, use Cudo Compute’s cloud GPU server. We can tailor your payment to suit your needs.
Furthermore, the Volta architecture, which underpins the V100, improved upon the previous Single Instruction, Multiple Threads (SIMT) execution model used by NVIDIA's earlier architectures like Pascal.
In earlier GPU architectures like Pascal, the execution model handled threads in groups called "warps." Each warp executed the same instruction across multiple threads, but when different threads in a warp needed to take different execution paths (due to conditional branching, for example), this could lead to inefficiencies. In these cases, threads not following the "active" path had to wait, leading to a serialized execution for divergent paths and, consequently, underutilization of the GPU's computational resources.
The Volta architecture, however, introduced an advanced form of the SIMT execution model. It allowed for what's known as "independent thread scheduling." This enhancement meant that each thread could operate more independently within a warp, maintaining its own state and execution pathway without being locked step-by-step with the rest of the warp's threads.
This, in turn, reduced the penalties associated with divergent code execution, as threads could diverge and converge more efficiently. This change aimed to maximize parallel efficiency by improving the GPU's ability to handle divergent execution paths, which are common in complex computational tasks like those involved in AI and HPC.
The introduction of independent thread scheduling enabled by the Volta architecture improved the GPU's ability to handle complex, fine-grained parallel algorithms more effectively. The V100 improved concurrency and reduced the latency associated with memory-intensive tasks, enabling more efficient data handling and processing.
What is the NVIDIA V100 used for
The NVIDIA V100, like the A100, is a high-performance graphics processing unit (GPU) made for accelerating AI, high-performance computing (HPC), and data analytics.
Overview of NVIDIA A100
Launched in May 2020, The NVIDIA A100 marked an improvement in GPU technology, focusing on applications in data centers and scientific computing. It is built on the Ampere architecture, which substantially improves the previous generation's Volta architecture in the V100.
The A100 is engineered to support a wide array of computing tasks, including AI, data analytics, cloud computing, and HPC. It's designed to deliver acceleration at every scale, enhancing scalable data centers' performance capabilities.
This means that the A100 GPU is designed to speed up computing tasks in isolated instances and across various sizes and complexities of computational work. This acceleration is not limited to small-scale tasks or massive, singular computations but is scalable across different levels of computational demands. This scalability is crucial for varying the workloads that data centers handle.
The A100 offers higher performance than the previous generation and introduces several AI-specific enhancements, such as structural sparsity and Multi-Instance GPU (MIG), which allow for more efficient resource utilization and greater scalability.
Structural sparsity in the A100 takes advantage of the fact that most data sets used in building AI models are full of zeroes or very small numbers that don't really change the outcome of computations if they are removed. By ignoring these unnecessary details, the A100 can do its job twice as fast for some tasks. This makes things like training AI models or analyzing data quicker and more efficient
On the other hand, MIG allows a single A100 GPU to be partitioned into multiple smaller, separate GPUs. Each instance operates independently and can run different tasks concurrently. This capability is particularly beneficial in environments where multiple users or tasks need to share GPU resources, as it allows for better utilization of the GPU, ensuring that its computational power is not left idle and can be scaled according to specific needs.
What is the lifespan of the A100 GPU?
The exact lifespan of an A100 GPU depends on various factors like usage and cooling conditions. However, typically, high-end GPUs like the A100 can last for several years (5-7 years) with proper care.
Moreover, the Ampere architecture supports the latest data transfer and interconnect technologies, including PCIe Gen 4 and NVIDIA's Magnum IO, which can be combined with Mellanox interconnect solutions. This means it can efficiently link many computers or GPUs, which is especially good for large-scale tasks that need lots of computing power.
This versatility makes the A100 highly effective for a variety of applications, from AI training and inference to complex data analytics and high-performance computing tasks
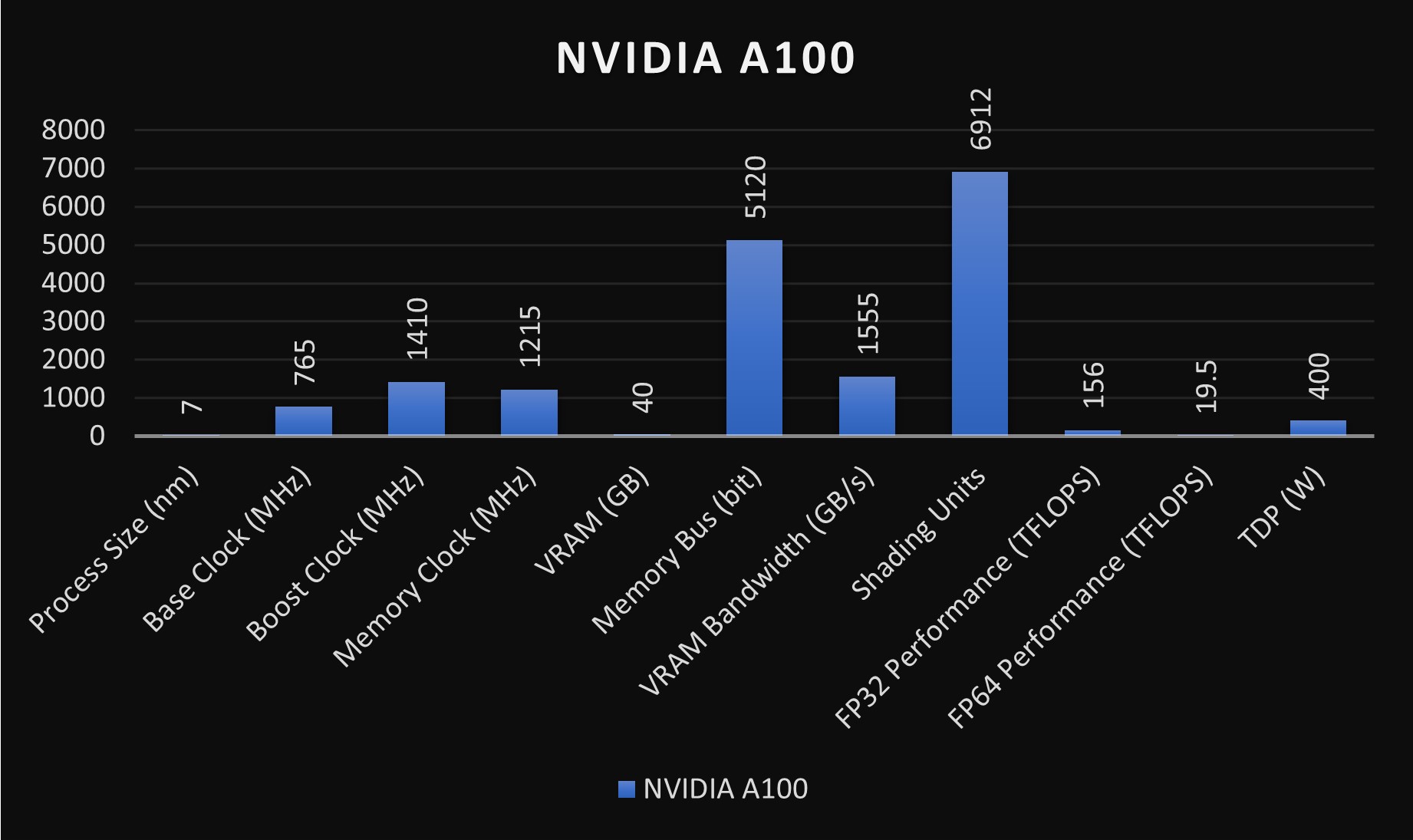
We have previously written about the features of the A100, which include its 6,912 CUDA cores and 432 Tensor cores, that make it easy for the A100 to handle intense data processing tasks. The GPU is equipped with 40GB of HBM2e memory, offering a bandwidth of up to 1.6 terabytes per second (TB/s), which is higher than the V100’s. This vast memory and bandwidth capacity make the A100 great at handling large datasets and complex AI models.
Read more about the NVIDIA A100 benchmark in our previous articles. You can use the NVIDIA A100 for your AIand HPC needs on Cudo Compute. Using the A100 on Cudo Compute will reduce the time required to set up and provide an efficient and scalable solution.
The A100's intended use cases extend from large-scale AI training and inference tasks to HPC applications, making it a versatile solution for various high-demand computing environments.
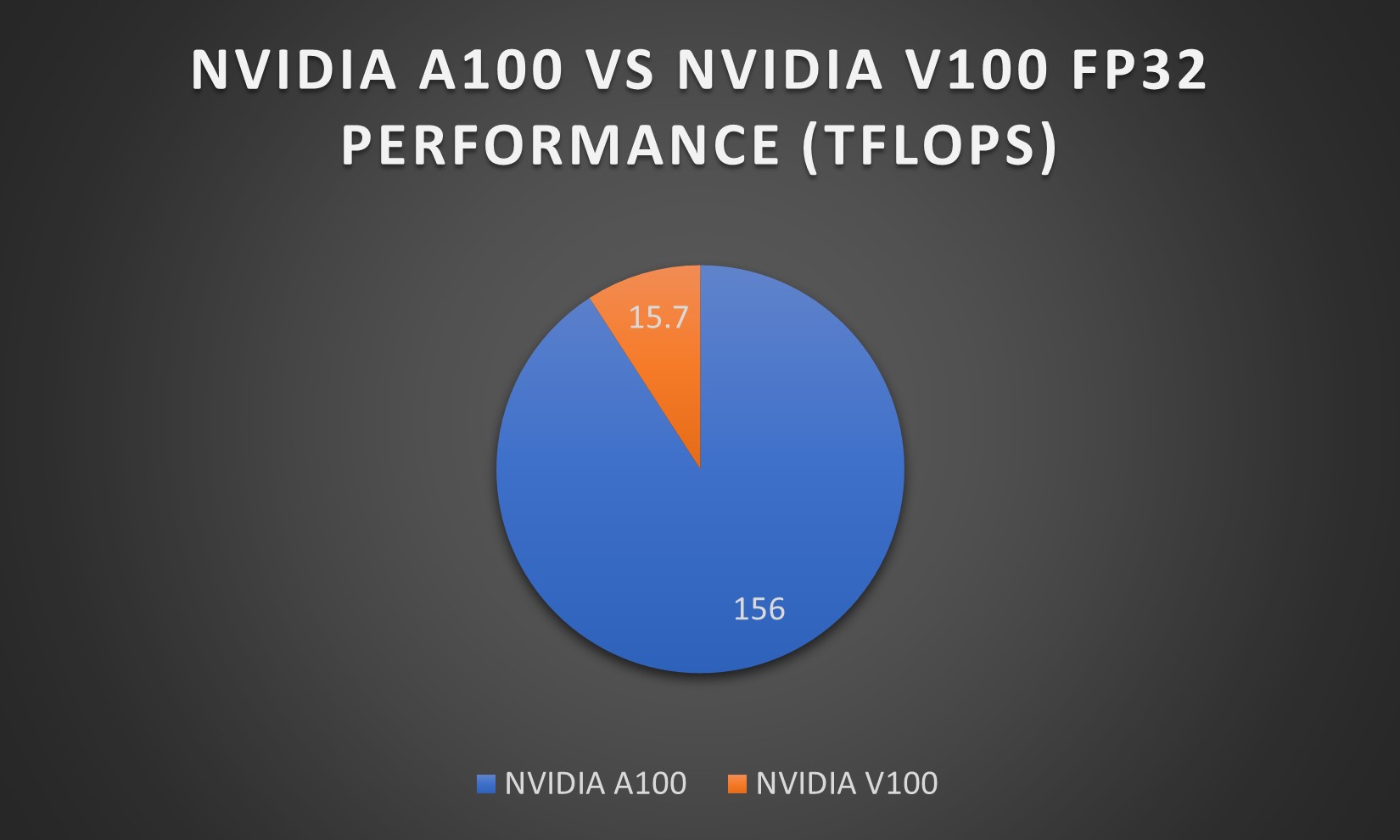
A100 vs V100 performance comparison
The performance comparison between NVIDIA's A100 and V100 GPUs shows significant advancements in computational efficiency. The A100 GPU provides a substantial improvement in single-precision (FP32) calculations, which are crucial for deep learning and high-performance computing applications. Specifically, the A100 offers up to 156 teraflops (TFLOPS), while the V100 provides 15.7 TFLOPS.
This increase in TFLOPS for the A100 signifies its enhanced ability to perform more floating-point calculations per second, contributing to faster and more efficient processing for complex computational tasks.
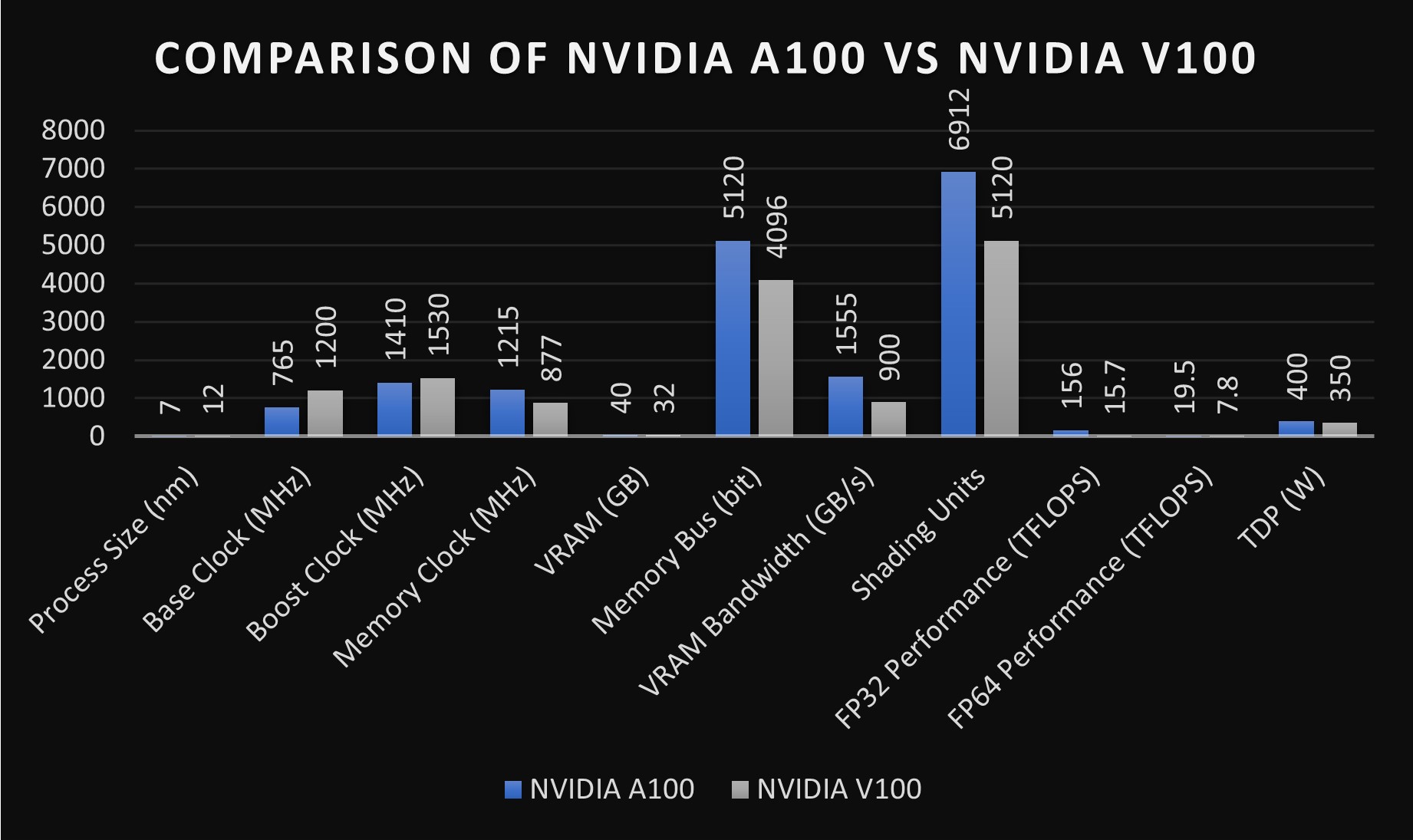
Here is a table that compares both GPUs:
| Specification | NVIDIA A100 | NVIDIA V100 |
|---|---|---|
| Process size (nm) | 7 (Ampere architecture) | 12 (Volta architecture) |
| Base clock (MHz) | 765 | 1200 |
| Boost clock (MHz) | 1410 | 1530 |
| Memory clock (MHz) | 1215 | 877 |
| VRAM (GB) | 40 (HBM2e) | 16/32 (HBM2) |
| Memory bus (bit) | 5120 | 4096 |
| VRAM bandwidth (GB/s) | 1555 | 900 |
| Shading units | 6912 | 5120 |
| Tensor cores | Yes (3rd Gen) | Yes (2nd Gen) |
| FP32 performance (TFLOPS) | Up to 156 | Up to 15.7 (single-precision) |
| FP64 performance (TFLOPS) | Up to 19.5 (double-precision) | Up to 7.8 (double-precision) |
| TDP (W) | 400 | 300/350 |
| Manufacturing architecture | Ampere | Volta |
| Target market | AI, data analytics, HPC | AI, scientific computing, HPC |
The performance difference in AI and deep learning is even more pronounced due to the A100's enhanced Tensor Cores and structural sparsity support. The A100 can achieve up to 312 TFLOPS for AI-specific tasks (using sparsity), substantially increasing over the V100's 125 TFLOPS. This makes the A100 particularly well-suited for training large, complex neural networks.
Memory performance is another critical factor in GPU comparison. The A100's 40GB of HBM2e memory offers a larger capacity than the V100’s 32GB and significantly greater bandwidth (1.6 TB/s compared to 900 GB/s). This improvement translates into better performance for data-intensive tasks and applications dealing with large datasets.
However, energy efficiency is an essential consideration, especially in large-scale deployments. The A100 has a higher thermal design power (TDP) at around 400 watts than the V100's 300 watts. Despite this, when considering the performance gains delivered by the A100, especially in AI and high-performance computing tasks, it becomes apparent that the A100 is a more energy-efficient solution despite its higher TDP.
The A100's enhanced performance in tensor operations and other AI-related computations, combined with its ability to manage and utilize power efficiently, contributes to its improved performance per watt. For instance, it delivers impressive computational throughput for both single-precision and tensor operations, crucial for AI modeling and deep-learning tasks.
If you are considering the environmental impact and power efficiency of your GPU choice, the A100 offers substantial advancements in performance with only a moderate increase in power consumption. This makes it a valuable option for data centers, AI developers, and data scientists seeking to balance computational needs with energy efficiency.
Suitability for different applications
While both GPUs are designed for high-performance computing, their suitability for different applications varies based on their specifications and performance characteristics. Here is how they compare in specific scenarios:
- Scientific research and simulations: Both the A100 and V100 are highly capable of handling scientific research, particularly for simulations and computational tasks. However, the A100's improved performance and larger memory capacity make it a better fit for the most demanding simulations and data-intensive research projects.
- Enterprise data analytics: For businesses relying on large-scale data analytics, the A100 offers faster data processing and the ability to handle larger datasets, which can lead to more insightful analysis and better decision-making.
- Edge computing: While the V100 remains a solid choice for edge computing applications, the A100's features and improved performance metrics offer a forward-looking solution that could better meet the increasing demands of future AI applications at the edge.
- Cloud computing and data centers: The A100's enhanced performance and efficiency make it particularly suitable for cloud computing and data centers, where scalability and energy efficiency are primary considerations. Its ability to handle multiple tasks simultaneously allows for more flexible and cost-effective cloud services.
A100 vs V100 cost and value analysis
The cost of the GPUs is a crucial factor for many users, influencing the overall value they offer to different market segments.
- Initial costs and availability: The A100 is generally more expensive than the V100, reflecting its newer technology and higher performance capabilities. However, prices can vary based on supply and demand and the specific configurations and models.
- Total cost of ownership: When considering the total cost of ownership, it's important to factor in the initial purchase price and operating costs, such as power consumption and cooling. The A100's improved energy efficiency can lead to lower long-term costs, offsetting its higher initial price for many users.

Use the NVIDIA A100 and NVIDIA V100 on Cudo Compute to save costs. With Codo Compute, you save on the cost of buying and maintenance, and you no longer have to use just one GPU. You can use any of our on-reserve GPUs at scale.
Cudo Compute offers customized contracts to suit your needs. Contact us today or simply get started.
Future-proofing and longevity
Considering the rapid pace of technological advancement, future-proofing is essential for organizations investing in high-performance computing solutions.
- Evolving computational needs: The A100 is better positioned to meet the increasing demands of future computational tasks and AI algorithms, thanks to its newer architecture and higher performance. This makes it a more future-proof investment, potentially offering a longer lifespan before becoming obsolete.
- NVIDIA’s support and updates: NVIDIA provides extensive support for both GPUs, including driver updates and optimizations. However, as a newer product, the A100 is likely to receive longer-term support and more frequent updates, enhancing its longevity.
- Resale value and demand: The demand for high-performance GPUs in the secondary market can affect their resale value. The A100, being newer and more powerful, is likely to maintain higher resale value over time compared to the V100.
The NVIDIA A100 and V100 GPUs offer exceptional performance and capabilities tailored to high-performance computing, AI, and data analytics. The A100 stands out for its advancements in architecture, memory, and AI-specific features, making it a better choice for the most demanding tasks and future-proofing needs. However, the V100 remains a viable and cost-effective option for many applications, especially for those with less stringent performance requirements or budget constraints.
Ultimately, the choice between the A100 and V100 will depend on individual needs, budget, and the specific applications envisioned. As GPU technology continues to evolve, staying informed about the latest developments and how they align with your computational needs will be key to making the most informed decision.
