 Resources
Resources 
The NVIDIA H200 GPU is the latest AI GPU to be released. NVIDIA has showcased some remarkable specs of the H200, which boasts nearly twice the memory capacity of its predecessor, the H100. Both GPUs are built on the powerful Hopper architecture enhanced for larger AI and HPC workloads.
When it launched, the NVIDIA H100 revolutionized artificial intelligence (AI) performance. The H200 pushes these boundaries even further. However, the key question remains: How much does the H200 improve on the H100's capabilities?
Diving into the specifics of each GPU's architecture and what NVIDIA has shown on the H200, we can gain valuable insights into the performance gains users can expect.
NVIDIA H100 architecture and specification
The NVIDIA H100 is the most powerful and programmable GPU NVIDIA has released to date. It features several architectural improvements, including higher GPU core frequencies and greater computational power, compared to its predecessor (the A100).
The H100 features a new Streaming Multiprocessor (SM). SMs are components within the GPU architecture that handle various tasks, including:
- Running CUDA threads, which are the basic units of execution in NVIDIA's programming model.
- Performing traditional floating-point computations (FP32, FP64).
- Housing other specialized cores, like the Tensor Cores.

Source: NVIDIA
As stated previously, the H100 SM can perform Matrix Multiply-Accumulate (MMA) operations twice as fast as the A100 for the same data types. The H100 SM delivers a 4x performance boost over the A100 SM for floating-point operations. This is achieved through two key advancements:
- FP8 data type: The H100 introduces a new data format (FP8) that uses half the bits (8 bits) compared to the A100's standard (FP32, 32 bits), enabling faster calculations but with slightly lower precision.
- Improved SM architecture: Even for traditional data types (FP32, FP64) used in Tensor Cores, the H100 SM itself is inherently twice as powerful due to internal architectural enhancements.
Featured snippet:
Is H100 the best GPU?
At launch, the NVIDIA H100 is considered the best GPU for AI and HPC workloads, thanks to its cutting-edge architecture, massive memory bandwidth, and superior AI acceleration. It is specifically designed for deep learning, scientific computing, and data analytics at scale. However, "best" can depend on specific use cases, budgets, and compatibility requirements.
As discussed previously, the H100 features fourth-generation Tensor Cores designed to significantly improve performance over the previous generation, the A100.
The H100 boasts a new transformer engine specifically designed to accelerate the training and inference of transformer models, a crucial capability for Natural Language Processing (NLP). This engine leverages a combination of software optimizations and Hopper Tensor Cores to achieve significant speedups.
The engine dynamically switches between two data precision formats (FP8 and FP16) for faster calculations with minimal impact on accuracy. It automatically and dynamically handles conversions between these formats within the model for optimal performance.
The H100 transformer engine delivers up to 9x faster AI training and 30x faster AI inference for large language models than the A100.
Its powerful NVLink Network Interconnect enables communication between up to 256 GPUs across multiple compute nodes to tackle massive datasets and complex problems. Secure MIG technology partitions the GPU for secure, right-sized instances, maximizing quality of service for smaller workloads.
The NVIDIA H100 is the first truly asynchronous GPU. This refers to its ability to overlap data movement with computations, maximizing the overall computational efficiency. This overlapping ensures that the GPU can perform data transfers in parallel with processing tasks, reducing idle times and boosting the throughput of AI and high-performance computing (HPC) workloads.
The H100 further boosts efficiency with the Tensor Memory Accelerator (TMA), which optimizes GPU memory management. By streamlining memory operations, the TMA significantly reduces the number of CUDA threads required to manage memory bandwidth, freeing up more threads to focus on core computations.
Another innovation is the Thread Block Cluster. This groups multiple threads, enabling them to cooperate and share data efficiently across multiple processing units within the H100, which also extends to asynchronous operations, ensuring efficient use of the TMA and Tensor Cores.
Finally, the H100 streamlines communication between different processing units with a new Asynchronous Transaction Barrier, allowing threads and accelerators to synchronize efficiently, even when located on separate parts of the chip.
To read more on the H100 benchmarks, see our take on the A100 vs H100.
NVIDIA H100 vs H200 benchmarks
From our previous benchmarks of the NVIDIA H100, we discussed its memory specifications and more. In this article, we will focus on the NVIDIA H200.
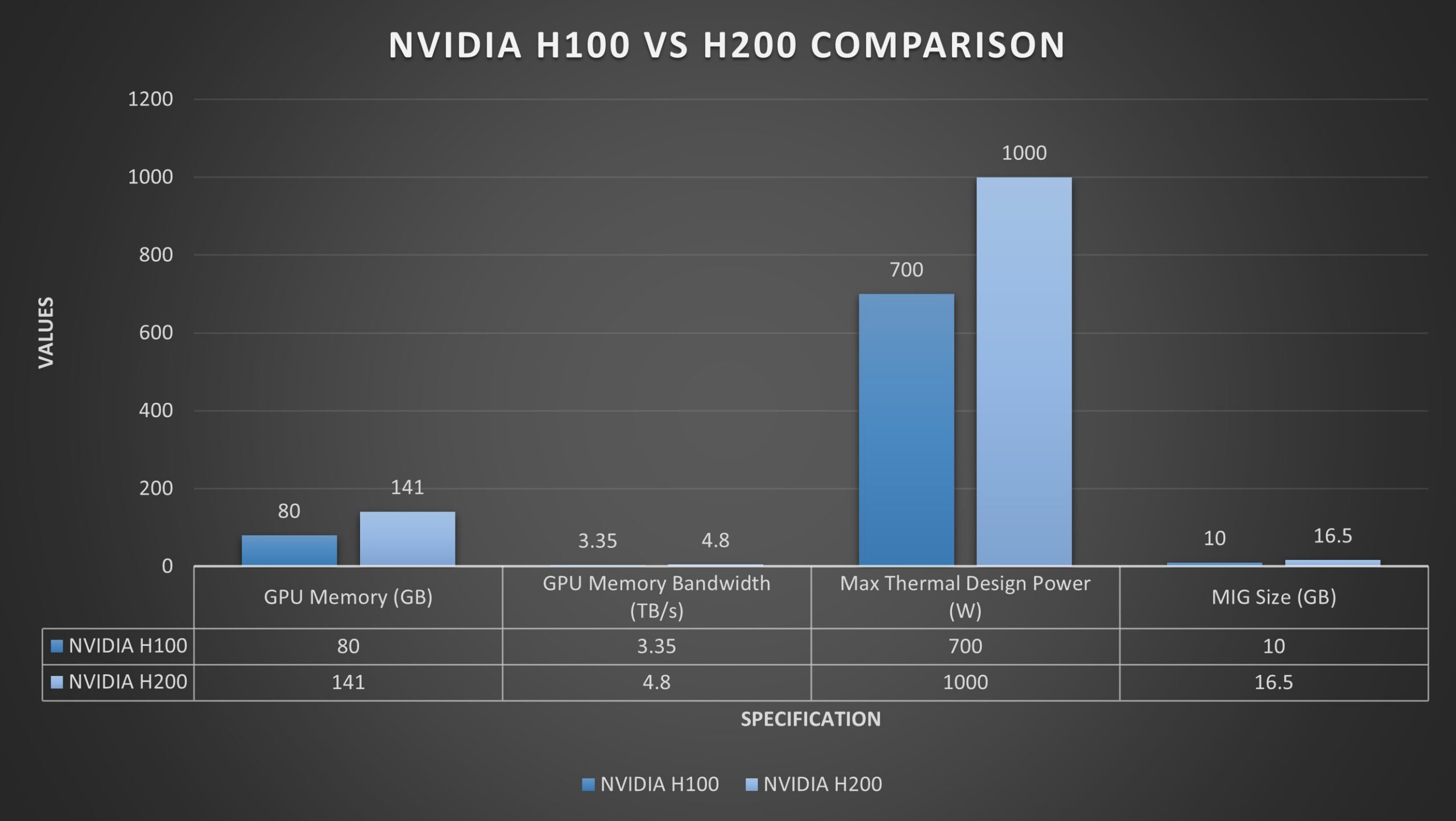
As impressive as the H100 is, the H200 takes its capabilities to the next level. It is the first GPU to feature HBM3e memory, with a memory capacity of 141 GB, which is nearly double that of the H100. The increased memory capacity is significant for AI because it enables larger models and datasets to be stored directly on the GPU, reducing latency associated with data transfer.
The H200's 4.8 TB/s of memory bandwidth is a stark improvement over the H100's 3.35 TB/s, indicating a capability to feed data to the processing cores much faster, which is essential for workloads requiring high throughput.
For memory-intensive HPC tasks like weather modeling or quantum chemistry, the H200's superior memory bandwidth means data can flow more freely between the GPU memory and processing cores, reducing bottlenecks and slashing time to insight. The reported up to 110x performance increase in HPC tasks indicates the H200's potential to handle highly complex simulations, enabling researchers and engineers to achieve more in less time.
You can be first in line to rent or reserve the NVIDIA H200 when it’s available at CUDO Compute. You can register your interest now or use one of our other GPUs, like the H100, and upgrade when the H200 becomes available. Contact us to learn more.
| Specification | NVIDIA H100 SXM | NVIDIA H200 |
|---|---|---|
| Form Factor | SXM | SXM |
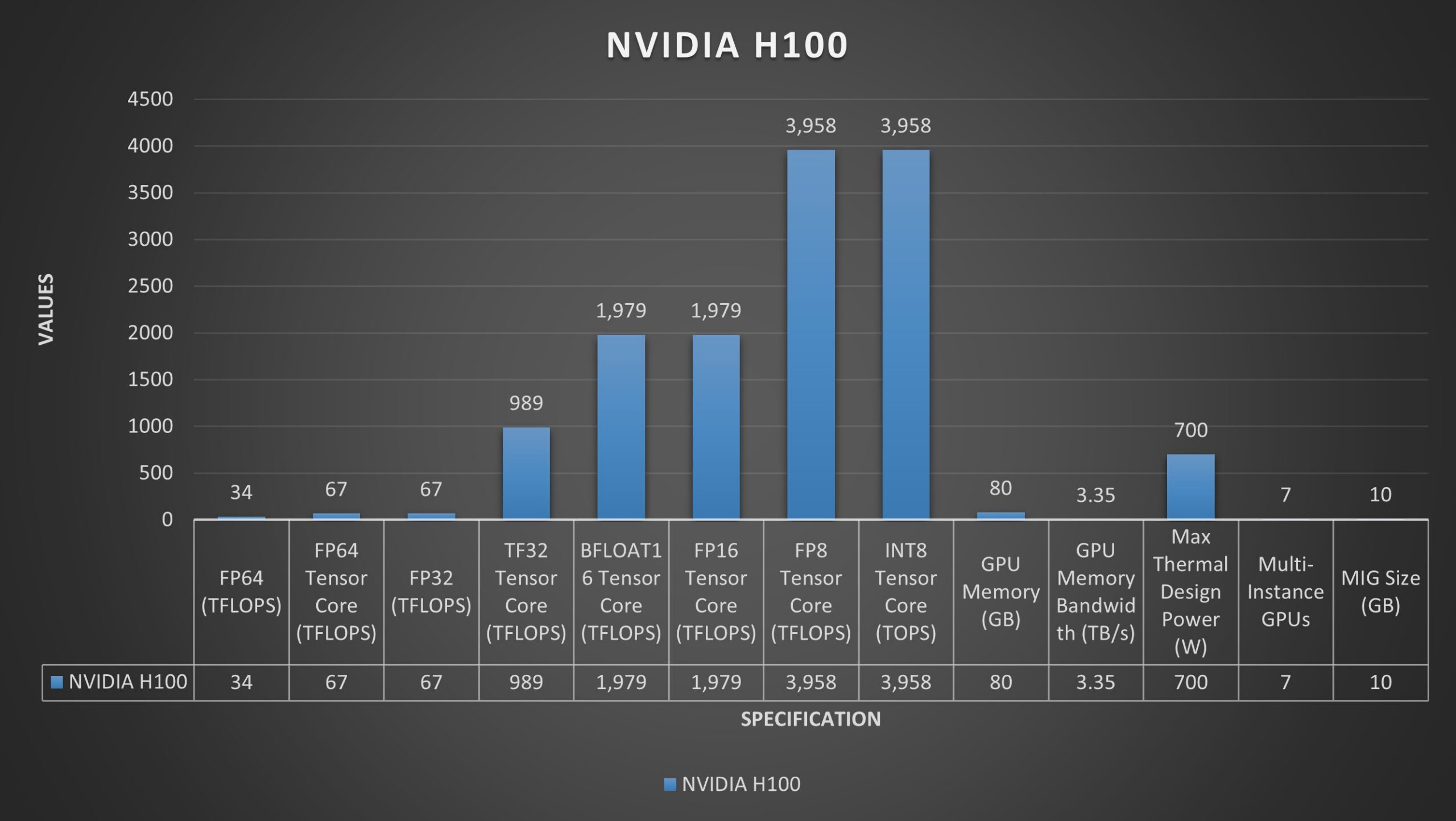
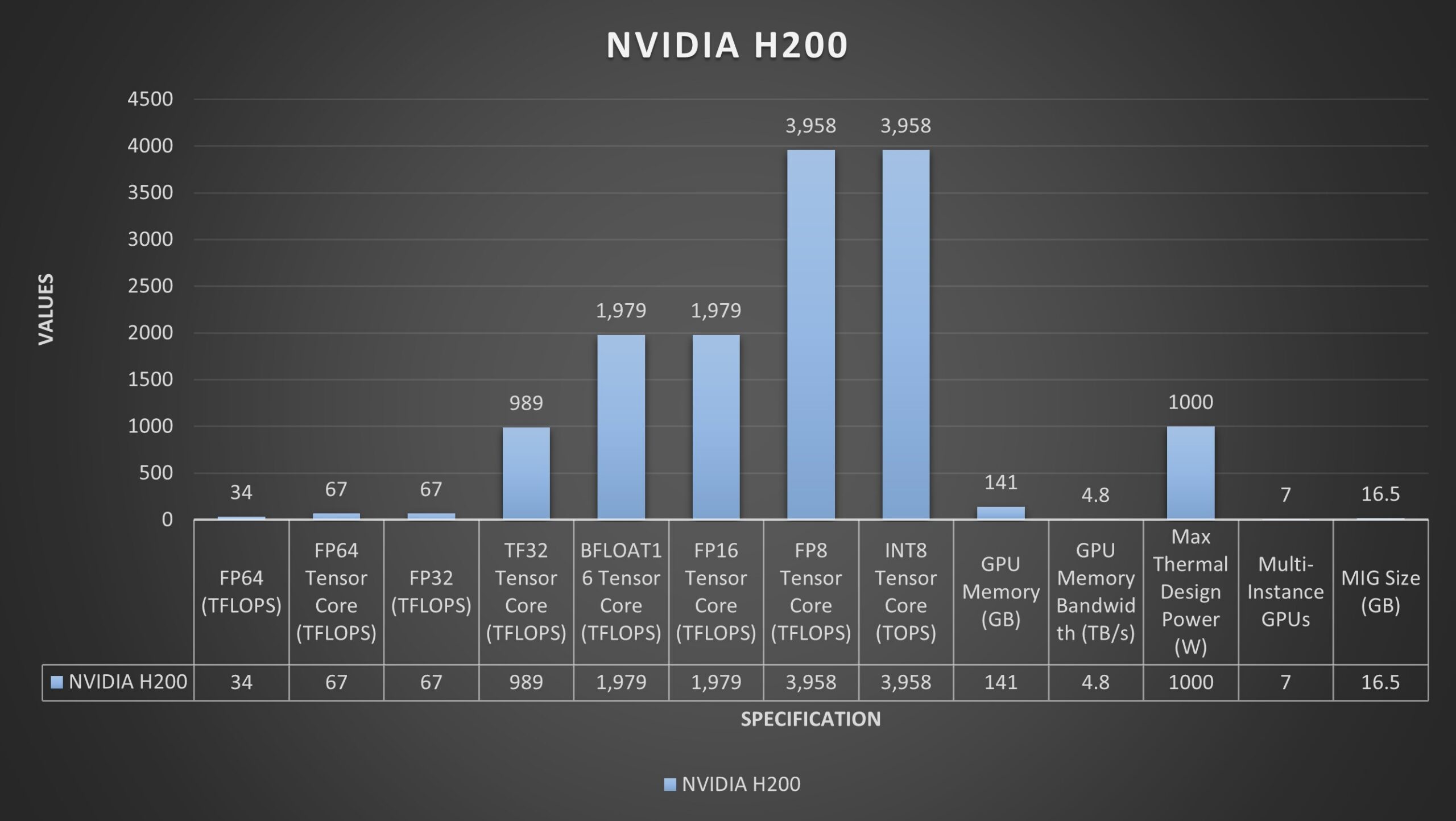
| FP64 | 34 TFLOPS | 34 TFLOPS |
| FP64 Tensor Core | 67 TFLOPS | 67 TFLOPS |
| FP32 | 67 TFLOPS | 67 TFLOPS |
| TF32 Tensor Core | 989 TFLOPS | 989 TFLOPS |
| BFLOAT16 Tensor Core | 1,979 TFLOPS | 1,979 TFLOPS |
| FP16 Tensor Core | 1,979 TFLOPS | 1,979 TFLOPS |
| FP8 Tensor Core | 3,958 TFLOPS | 3,958 TFLOPS |
| INT8 Tensor Core | 3,958 TOPS | 3,958 TOPS |
| GPU Memory | 80GB | 141GB |
| GPU Memory Bandwidth | 3.35TB/s | 4.8 TB/s |
| Decoders | 7 NVDEC, 7 JPEG | 7 NVDEC, 7 JPEG |
| Max Thermal Design Power | Up to 700W | Up to 1000W |
| Multi-Instance GPUs | Up to 7 MIGs @ 10GB each | Up to 7 MIGs @ 16.5GB each |
| Interconnect | NVLink: 900GB/s, PCIe Gen5: 128GB/s | NVLink: 900GB/s, PCIe Gen5: 128GB/s |
The H200 maintains the same performance metrics in FP64 and FP32 operations as the H100. There are also no distinctions in FP8 and INT8 performances, with 3,958 TFLOPS in each category. This is still impressive, as INT8 precision strikes a balance between computational efficiency and model accuracy and is often used on edge devices where computational resources are at a premium.
The H200 not only provides enhanced performance but also consumes the same energy as the H100. The 50% reduction in energy use for LLM tasks, combined with the doubled memory bandwidth, reduces its total cost of ownership (TCO) by 50%.
Featured snippet:
How much faster is H200 vs H100?
The NVIDIA H200 GPU outperforms the H100, delivering up to 45% more performance in specific generative AI and HPC (High Performance Computing) benchmarks. This improvement is largely attributed to the H200's enhanced memory capacity with HBM3e and greater memory bandwidth, as well as optimizations in thermal management. The exact degree of performance enhancement can vary depending on the specific workloads and configurations.
NVIDIA H100 vs H200 MLPerf inference benchmarks
Let’s look at how the NVIDIA H100 compares with the NVIDIA H200 on MLPerf inference analysis. MLPerf benchmarks are a set of industry-standard tests designed to evaluate the performance of machine learning hardware, software, and services across various platforms and environments. They provide a reliable measure for comparing the efficiency and speed of machine learning solutions, helping users identify the most effective tools and technologies for their AI and ML projects.
This is important for gen AI developers to test their models. Inference allows LLMs to understand new, unseen data. When presented with new data, inference enables the model to understand the context, intent, and relationships within the data based on the knowledge it acquired during training. The model then generates tokens (e.g., a word) one unit at a time.
The LLM considers the context inferred from the sequence and the previously generated tokens to predict the most likely next element. This allows the LLM to produce comprehensive outputs, whether it's translating a sentence, writing in different creative formats, or answering a question.
Here is how the H100 compares with the H200 in handling inference tasks, measured by the number of tokens each can generate within a given timeframe. This approach offers a practical metric for assessing their performance, especially in tasks related to natural language processing:
According to the MLPerf Inference v4.0 performance benchmarks for the Llama 2 70B model, the H100 achieves 22,290 tokens/second in offline scenarios, and the H200 achieves 31,712 tokens/second in the same scenarios, demonstrating a significant increase in performance.
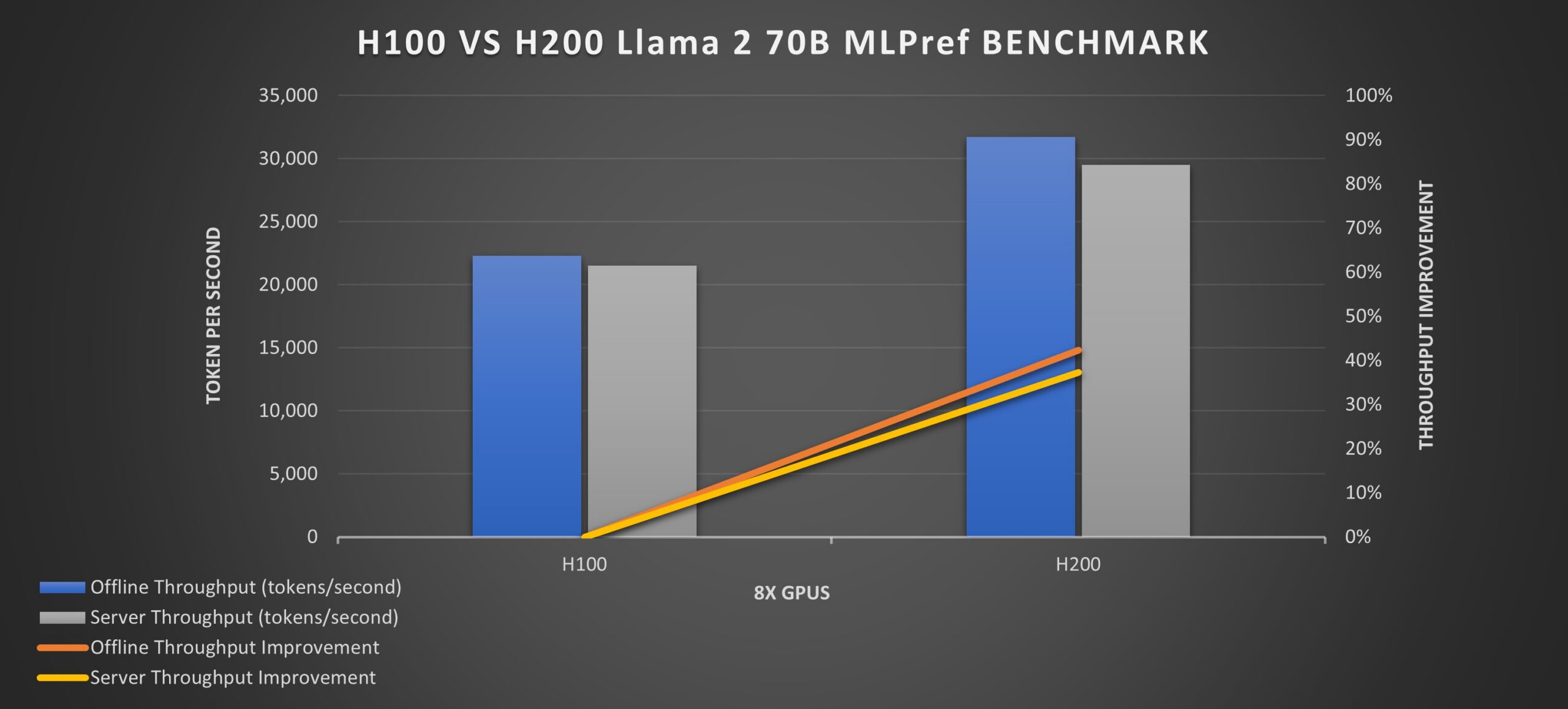
In server scenarios, the H100 achieves 21,504 tokens/second, while the H200 reaches 29,526 tokens/second. This indicates that the H200 delivers a 37% increase in the throughput of the H100 in server scenarios, a considerable performance enhancement. It also shows a notable increase in offline scenarios.
| GPU | Offline Throughput (tokens/second) | Throughput Improvement | Server Throughput (tokens/second) | Throughput Improvement |
|---|---|---|---|---|
| H100 | 22,290 | – | 21,504 | – |
| H200 | 31,712 | +42.4% | 29,526 | +37.3% |
The reasons for this boil down to the following:
H200's memory and bandwidth boost:
The H200’s larger memory (141GB) and higher bandwidth (4.8 TB/s) compared to the H100 are roughly 1.8 and 1.4 times, respectively. This helps the H200 handle larger data sizes than the H100, reducing the need to constantly fetch data from slower external memory. The higher bandwidth allows for faster data transfer between the memory and the GPU.
With these, the H200 can handle large tasks without resorting to complex techniques such as tensor parallelism (data splitting) or pipeline parallelism (processing in stages).
Improved inference throughput:
The lack of memory and communication bottlenecks allows the H200 to dedicate more processing power to computations, leading to faster inference. Benchmarks on the Llama test demonstrate this advantage, with the H200 achieving up to 28% improvement even at the same power level (700W TDP) as the H100.
Performance gains:
Benchmarks show that the H200 achieves up to 45% better performance on the Llama test than the H100 at 1000W of power.
These comparisons highlight the technological advancements and performance enhancements achieved with the H200 GPU over the H100, especially in handling the demands of generative AI inference workloads like Llama 2 70B, enabled by greater memory capacity, higher memory bandwidth, and improved thermal management.
Which models fit on each GPU
Memory capacity determines which models can run efficiently without complex parallelism strategies. Here's how popular models fit on H100 vs H200:
| Model | Parameters | H100 (80GB) | H200 (141GB) |
|---|---|---|---|
| Llama 3.1 8B | 8B | FP16, batch 32+ | FP16, batch 64+ |
| Mistral 7B | 7B | FP16, large batches | FP16, very large batches |
| Llama 2 70B | 70B | FP16, batch 1-4 | FP16, batch 8-16 |
| Llama 3.1 70B | 70B | FP16, batch 1-4 | FP16, batch 8+ |
| Mixtral 8x22B | 176B (sparse) | ⚠️ Requires tensor parallelism | Single GPU with quantization |
| Llama 3.1 405B | 405B | ❌ Requires 8+ GPUs | ⚠️ Requires 4 GPUs |
| DeepSeek R1 | 671B (37B active) | MoE architecture fits | MoE fits with larger batches |
Why this matters:
H200's extra 61GB of memory enables larger batch sizes, which directly translates to higher throughput and lower per-token latency in production inference. For models like Llama 2 70B, this means serving 2-4× more concurrent requests on a single GPU.
For teams running 70B+ parameter models, H200 can eliminate the need for tensor parallelism across multiple GPUs—simplifying deployment and reducing inter-GPU communication overhead.
Looking ahead: H200 vs Blackwell B200
The NVIDIA B200 (Blackwell architecture) began shipping in late 2025, raising questions about the relevance of the H200. While both target AI workloads, they represent different architectural generations with distinct trade-offs.
| Specification | H200 | B200 |
|---|---|---|
| Architecture | Hopper | Blackwell |
| Memory | 141GB HBM3e | 192GB HBM3e |
| Memory Bandwidth | 4.8 TB/s | 8 TB/s |
| FP8 Tensor Core | 3,958 TFLOPS | 9,000 TFLOPS |
| FP4 Support | No | Yes (20 PFLOPS sparse) |
| TDP | 1000W | 1000W |
| NVLink Generation | 4th (900 GB/s) | 5th (1.8 TB/s) |
| Availability | Widely available | Limited availability |
Key architectural differences:
The B200 uses a chiplet design with two dies connected via a 10 TB/s NV-High Bandwidth Interface, packing 208 billion transistors (2.5× more than H100/H200). This enables massive improvements in memory and bandwidth. The fifth-generation Tensor Cores add support for FP4 and FP6 precision—formats that can double inference throughput for compatible workloads.
When to choose H200 over B200:
- Immediate deployment needs where B200 availability is limited
- Existing Hopper infrastructure you want to expand
- Workloads that don't benefit from FP4 precision (most current production models)
- Cost-sensitive deployments where H200's mature ecosystem reduces operational risk
- Software stack not yet optimized for Blackwell (vLLM, TensorRT-LLM still maturing)
When to wait for B200:
- Training frontier models with 100B+ parameters
- Production inference requiring FP4 acceleration
- Building new clusters with 3+ year deployment horizons
- Workloads requiring 192GB+ memory per GPU
For most production inference workloads in 2025-2026, H200 remains the practical choice given availability, ecosystem maturity, and proven performance. B200 becomes compelling for teams pushing the boundaries of model scale.
For everything about the B200, read: NVIDIA’s Blackwell architecture: breaking down the B100, B200, and GB200
The NVIDIA H200 is available on CUDO Compute. Get started using it now!
